一、RabbitMQ 原理
1、基本原理
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是AMQP(高级消息队列协议)的标准实现。支持多种客户端,如:Python、Java、Javascript、C#、C/C++,Go等,支持AJAX,持久化存储。可用于进程之间、分布式系统、异系统之间通信、工作流等。
RabbitMQ支持很多通讯协议,包括AMQP 0-9-1、AMQP 1.0、MQTT和STOMP等。默认使用 AMQP 0-9-1 做为网络层协议。
其支持的网络通讯模型主要有:
- 生产者–消费者模式
- 任务队列模式
- 发布者–订阅者模式
- 路由模式
- RPC模式
所以,如果你的项目包含多个子系统,需要交换的数据有各种类型,有1对1,1对N通信等各种要求,显然成熟的RabbitMQ是1个非常好的选择。如果需要传输大尺寸图像文件,高实时性场景,建议便用ZeroMQ等低层网络库开发消息队列服务器代码更合适。
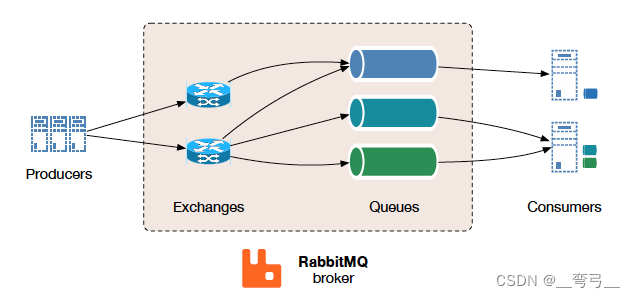
2、核心组件包括:
- Exchange(交换机)
- Message Queue(消息队列)
- Binding(绑定)
Exchange 交换机类型
- Direct Excnahge直接交换
基于route key 来将消息发送到queue。主要用于单播 - Fanout Exchange 广播交换
不使用route key, 而是一些队列会绑定到Fanout, 新消息会被发送到所有绑定的queue, 适用于广播消息。 - Topic Exchange 主题交换
基于route key 与 匹配pattern , 将queue绑定到exchange ,
示例用途:
分发与特定地理相关的数据 位置,例如销售点
由多个工作人员完成的后台任务处理, 每个都能够处理特定的任务集
股票价格更新(以及其他类型的财务数据更新)
涉及分类或标记的新闻更新 (例如,仅适用于特定运动或团队) - Headers exchange 消息头交换
不使用route key, 而是通过message header 来绑定queue 与exchange 。1条queue可以绑定多个header
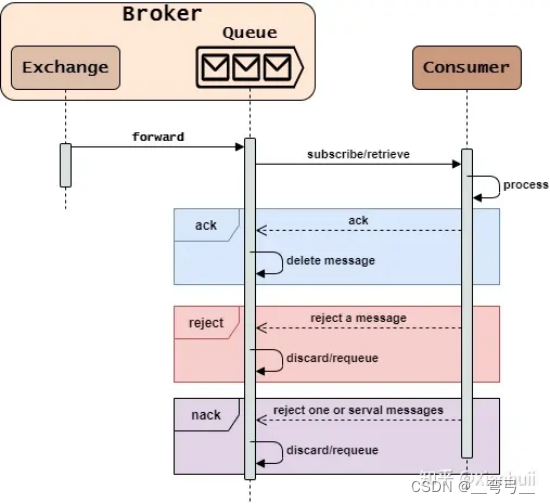
消息队列 Queue
工作流程
消息队列是FIFO(First In First Out,先进先出)队列,它的作用是:
- 接收消息(from Exchange)
- 保存消息
- 发送消息(to Consumer)
RabbitMQ中Message Queue的基本工作流程是
Queue 的属性
“queues”: [
{
“name”: “testQueue”,
“vhost”: “/”,
“durable”: true,
“auto_delete”: false,
“arguments”: {
“x-queue-type”: “classic”
}
}]
Binding 绑定
Exchange和Message Queue并没有存储对方的信息,那么Exchange在转发过程中是如何找到正确的Message Queue的呢?这需要借助Binding组件。
Binding中保存着source和destination属性,可以将交换机作为消息源,交换机/消息队列作为转发地址。当交换机路由消息时,会遍历Binding数组,找到source为自身的绑定关系,判断消息属性是否满足routing_key或arguments进行转发。
主要属性
"bindings": [
{
"source": "amq.headers",
"vhost": "/",
"destination": "bigAndBlue",
"destination_type": "queue",
"routing_key": "",
"arguments": {
"color": "blue",
"size": "big",
"x-match": "all"
}
}]
RabbitMQ 其它重要概念:
- Broker:简单来说就是消息队列服务器实体。 Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- producer:消息生产者,就是投递消息的程序。 consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
二、RabbitMQ 的安装
这里简略介绍Win10下安装 RabbitMQ 3.13.1 的步骤,详细也可参考另1篇介绍安装的文章
1、RabbitMQ安装方式
- Docker 安装方式, 有官方docker image,最方便。
- Linux安装 , Debian或ubuntu
- windows安装,开发环境
当前最新版本 3.13.1, 要求erlang 版本为25.x, 26.x
2、Windows安装步骤
1) 安装 Erlang语言环境
Step-1 从Erlang主页下载26.x 版本。
https://www.erlang.org/downloads
Step-2 下载 windows installer 后安装
step-3 添加环境变量
(1) 新建ERLANG_HOME,指向 erlang安装目录,
(2) 将 %ERLANG_HOME%\bin目录添加至path 系统环境变量。
3、安装 rabbitMQ server.
1) 下载RabbitMQ window installer 安装。
https://www.rabbitmq.com/docs/install-windows
2) 安装后点击安装,系统会自动添加RabbitMQ服务。
3) 按Ctrl+R,输入services, 检查 RabbitMQ 服务是否已启动。
4、基本配置
RabbitMQ 有默认配置。 通常开发环境、单服务器环境下也够用了。
5、命令行工具
RabbitMQ提供了一些命令行工具。在安装目录的 sbin/ 子目录下。如 D:\App\rabbitmq\rabbitmq_server-3.13.1\sbin>,
- rabbitmqctl 管理工具
- rabbitmq-diagnostics 健康检查工具
- rabbitmq-plugins 插件管理
使用管理界面来管理rabbitmq
rabbitmq-plugins enable rabbitmq_management, 运行后,默认管理界面的URL: http://localhost:15672/
三、RabbitMQ 各类通信模式的实现
1、安装 RabbitMQ 客户端连接工具
Step-1 安装RadditMQ 客户端
python -m pip install pika --upgrade
Step-2: Producer端send.py
import pika
2、基本模式:生产者–消费者模式
本例功能需求; 生产者将消息发往Queue, 消费者从queue接收消息
1) 生产者代码实现 producer.py
import pika
# 首先建立至RabbitMQ 服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 创建1个 queue
channel.queue_declare(queue='hello')
#Rabbit发送消息,须经过exchage, 本例 使用默认exchange, 使用routing_key=’hello’发送消息。
channel.basic_publish(exchange='',
routing_key='hello', # hello为前面创建的queue名字
body='Hello World!')
print(" [x] Sent 'Hello World!'")
#发送完成后,即可关闭连接
connection.close()
2)消费者接收消息代码实现
import pikia
#建立至rabiitMQ服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明接受队列queue
channel.queue_declare(queue='hello')
#定义callback
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 配置consume 参数,指定queue, 回调函数,auto_ack等。
channel.basic_consume(queue='hello',
auto_ack=True,
on_message_callback=callback)
# 等待数据,收到后自动执行callback
channel.start_consuming()
3) 测试:
1)打开第1个终端 ,运行客户端 python receive.py
2)打开第2个终端 ,运行Producer端, python send.py
consumer端应该显示
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'Hello World!'
2、任务队列模式的实现
任务队列 Work Queue, 也称Task Queue, 主要用于发布耗时任务.
功能需求:
(1)Producer将任务及数据封装在1 个message中,发送给work queue,
(2)Worker 从队列中读取消息。几个worker同时工作,则速度大大提高。
(3) Work Queue中的1条消息,RabbitMQ Server只发给1个worker, 发送完成后删除。
Producer.py , 创建发布task message.
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print(f" [x] Sent {message}")
Worker.py, 处理任务的工作放在callback 函数。
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag) (发送ack)
测试:
启动2个worker.py ,用1个producer发布task消息
消息持久化配置
当rabbitmq server宕机,任务消息会丢失,如果需要保持queue不丢失
Worker端:
channel.queue_declare(queue='hello', durable=True)
Producer端
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = pika.DeliveryMode.Persistent
))
Pair Dispatch 根据ack分派消息
为避免worker负荷不均,使用pair dispatch 方式: Server只有收到Worker上1条消息的ack ,才发送1条新消息。 worker设置 prefetch_count参数=1
channel.basic_qos(prefetch_count=1)
完整代码
Producer.py
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(
exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=pika.DeliveryMode.Persistent
))
print(f" [x] Sent {message}")
connection.close()
Worker.py
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
channel.start_consuming()
3、Publish-Subscribe 发布订阅模式的实现
Pub-Sub中,producer发布1条消息,这条消息可以发送给多个consumer.
功能需求: 构建1个log system, 1个emit 发送log, 多个 receiver 接收log并打印。
本例 exchange 使用fanout 类型,使用默认queue, 每条消息都会广播给所有consumer,
Producer端
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
发布消息
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
完整代码: publish.py
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#设置exchange参数
channel.exchange_declare(exchange='logs', exchange_type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
# 发布 消息
channel.basic_publish(exchange='logs', routing_key='', body=message)
print(f" [x] Sent {message}")
connection.close()
Consumer端
先创建exchange对象,申明默认queue, 绑定exchage 与queue.
channel.queue_bind(exchange=‘logs’, queue=result.method.queue)
Binding 关系,可以理解为,这个queue接收从该exchange发送的所有消息。也可以添加route-key参数。
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#使用与Producer相同的 exchange,
channel.exchange_declare(exchange='logs', exchange_type='fanout')
# 使用默认queue, 绑定至exchange
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue #系统命名默认queue
channel.queue_bind(exchange='logs', queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] {body}")
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
4、路由模式的实现
路由 Routing 使用 direct exchage, 只接收queue上符合route-key规则的消息。
如上图,queue Q1 与 只包含 orange的消息, Q2 接受包含 black 或 green的消息。
也可以将1个route-key绑定到多个queue.
发布方 pub.py
创建exchange
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
发送消息
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
订阅方receiver.py :
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
完整代码
Receiver.py
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(
exchange='direct_logs', queue=queue_name, routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] {method.routing_key}:{body}")
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
Pub.py
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(
exchange='direct_logs', routing_key=severity, body=message)
print(f" [x] Sent {severity}:{message}")
connection.close()
测试
启动多个receiver, 分别接受不同
worker-1: python receiver.py error warning
worker-2: python receiver.py warning
用pub.py 发消息
Python sub.py warning “a warning for test” # worker-1, worker-2都会收到
Python sub.py error “a error for test” # only worker-1 收到
主题模式Topics
主题网络模式使用 topic exchage, 可以用于更复杂的场景。
主题交换的route-key 使用替换符
*表示 1个词#表示 0或多个word.
Topic的route-key 建议格式:
<celerity>.<colour>.<species>, 每1级主题之间用.点号分隔。
实例 :
*.orange.* , *.*.rabbit, lazy.##表示该queue可以接收所有消息,相当于fanout- 不含
*与#的 route-key ,与 direct exchange作用相同。
Pub.py
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(
exchange='direct_logs', routing_key=severity, body=message)
print(f" [x] Sent {severity}:{message}")
connection.close()
Receiver.py
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(
exchange='direct_logs', queue=queue_name, routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(f" [x] {method.routing_key}:{body}")
channel.basic_consume(
queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
测试
启动消息者 receiver.py
python receiver.py warning error
启动发布者,发布消息
python pub.py error "Run. Run. Or it will explode."
python pub.py info "it is info, not explode."
可以看到消费者收到了error消息, 但没有收到info消息。
6、RPC 调用
在rpc场景中,Server暴露1个接口, client 在调用时,将调用请求做为消息发布至 1 queue, 同时指定reply_to 队列,Server将响应发送到reply_to 队列
Server 在开始是做为消息的接受者,发送响应时做为消息发送者。
client.py 代码
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(queue='', exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response,
auto_ack=True)
self.response = None
self.corr_id = None
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4()) # 产生1个 uuid
print("发送rpc请求")
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events(time_limit=None)
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(f" [.] Got {response}")
提供 rpc 函数的服务端代码 server.py
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body):
n = int(body)
print(f" [.] 收到请求,调用 fib({n})")
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()
测试:
先启动服务端 python server.py
再启动客户端 python client.py