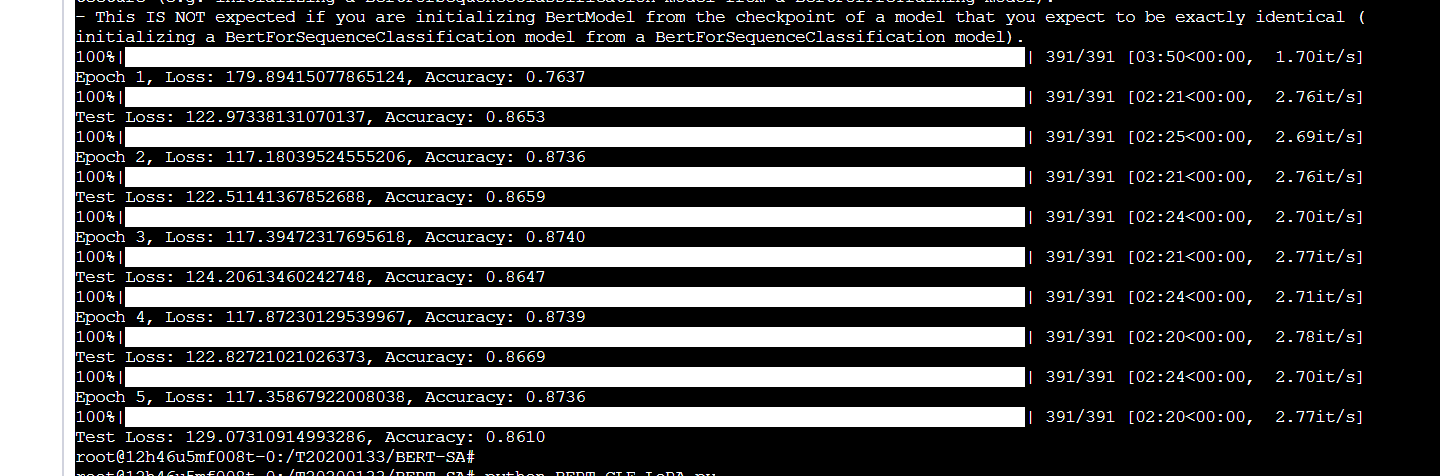
文章目录
- 1. Street-View Image Generation from a Bird’s-Eye View Layout
- 1.1 Problem introduction
- 1.2 Why
- 1.3 How
- 1.4 My takeaway
- 2. DisCoScene: Spatially Disentangled Generative Radiance Fields for Controllable 3D-aware Scene Synthesis
- 2.1 What
- 2.2 Why
- 2.3 How
- 2.4 My takeaway
- 3. BerfScene: Bev-conditioned Equivariant Radiance Fields for Infinite 3D Scene Generation(Follow DisCoScene)
- 3.1 What
- 3.2 Why
- 3.3 How
- 3.4 My takeaway
1. Street-View Image Generation from a Bird’s-Eye View Layout
1.1 Problem introduction
From the title of this paper, we know it bound a relation from Bev(Bird’s-Eye View) to Street view image.

Concretely, the input (Bev) is a two-dimensional representation of a three-dimensional environment from a top perspective. In the BEV diagram, squares of different colors represent different objects or road features, such as vehicles, pedestrians, lane lines, etc. And green square means an ego vehicle that has three cameras in front.
The task is to generate three street-view images aligned to the Bev according to the relative position among these square objects.
As for the concept of “layout”, it should consider the effects of these factors:
- Cameras with an overlapping field-of-view (FoV) must ensure overlapping content is correctly shown
- The visual styling of the scene also needs to be consistent such that all virtual views appear to be created in the same geographical area (e.g., urban vs. rural), at the same time of day, with the same weather conditions, and so on.
- In addition to this consistency, the images must correspond to the HD
map, faithfully reproducing the specified road layout, lane lines, and vehicle locations.
1.2 Why
It is the first attempt to explore the generative side of BEV perception for driving scenes.
1.3 How
-
Methods

As shown in this pipeline, the Bev layout and source images were encoded as an input of the autoregressive transformer collaborating with direction and camera information to help the understanding of space. New mv-images were output. -
Experiments
Three metrics are used.

FID represents the diversity and quality of generated images. Road mIoU and Vehicle mIoU can be used to represent the overlapping to verify the relative position in the Bev inputs.
Scene edit was achieved by the change of Bev layout:

1.4 My takeaway
- How to utilize the ability of an autoregressive transformer!!! Why do we use it other than others?
- I have known about what is Bev.
2. DisCoScene: Spatially Disentangled Generative Radiance Fields for Controllable 3D-aware Scene Synthesis
2.1 What
An editable 3D generative model using object bounding boxes without semantic annotation as layout prior, allowing for high-quality scene synthesis and flexible user control of both the camera and scene objects.
2.2 Why
-
Existing generative models focus on individual objects, lacking the ability to handle non-trivial scenes.
-
Some works like GSN can only generate scenes, without object-level editing. That is because of the lack of explicit object definition in NeRF.
-
GIRAFFE explicitly composites object-centric radiance fields to support object-level control. Yet, it works poorly on mixed scenes due to the absence of proper spatial priors.
-
Interesting refer:
17: Layout-transformer: Layout generation and completion with self-attention.
26: Layout-gan: Generating graphic layouts with wireframe discriminators.
58: Blockplanner: City block generation with vectorized graph representation.
2.3 How

Bounding boxes as layout priors to generate the objects, combined with the generated background were used in neural rendering. Meanwhile, an extra object discriminator for local discrimination is added, leading to better object-level supervision.
2.4 My takeaway
- Is it possible to cancel the manually marked bbox and automatically identify and regenerate the corresponding area in Gaussian?
3. BerfScene: Bev-conditioned Equivariant Radiance Fields for Infinite 3D Scene Generation(Follow DisCoScene)
3.1 What
Incorporating an equivariant radiance field with the guidance of a BEV map, this method allows us to produce large-scale, even infinite-scale, 3D scenes via synthesizing local scenes and then stitching them with smooth consistency.
Understood as the superposition of patches in a bev:

3.2 Why
- Generating large-scale 3D scenes cannot simply apply existing 3D object synthesis techniques since 3D scenes usually hold complex spatial configurations and consist of many objects at varying scales.
- Previous approaches often relied on scene graphs, facing limitations in processing due to unstructured topology.
- DiscoScene introduces complexity in interpreting the entire scene and
faces scalability challenges when using Bbox. - BEV maps could specify the composition and scales of objects clearly but lack insights into the detailed visual appearance of the objects. Recent attempts like InfiniCity and SceneDreamer try to avoid the ambiguity of BEV maps, but they are inefficiency.
3.3 How

To integrate the prior information provided by the BEV map into the radiation field, the researchers introduced a generator U U U, which can generate a 2D feature map based on BEV map conditions. Builder U U U adopts a network structure that combines U-Net architecture and StyleGAN blocks.
3.4 My takeaway
- Confused about how to use this U-Net, need some other time to supplement background knowledge. 🤡






![适用于 Windows 的 10 个顶级 PDF 编辑器 [免费和付费]](https://img-blog.csdnimg.cn/img_convert/63160b0208f693f03a94219ece10a78d.webp?x-oss-process=image/format,png)