目录
一、restful 、django-rest-framework 、swagger 三者的关系
(一)restful API(REST API)
1. rest
2. restful
3. api
4. restfulAPI
(二)django-rest-framework(简称DRF)
(三)swagger
二、DRF 基础配置
(一)安装依赖
(二)配置环境
三、自定义序列化器(定义序列化类,serializers)
(一)Django 序列化 & DRF 序列化器
1. Django 序列化
(1)序列化
(2)反序列化
2. DRF 序列化器
(二)序列化类
(三)常用字段
1. 序列化器的常用字段
2. 自定义字段类型
3. 字段的many参数
4. 字段的多关系子序列化
(1)source参数的使用
① 重命名字段
② 跨表
③ 执行方法
(2)SerializerMethodField的使用
5. fields的必要性
6. exclude
7. validate_字段名
(四) 创建序列化器(定义序列化类)
1. 一般写法
2. 公共字段
四、使用序列化器(实例化)
(一)构造序列化对象
1. data
2. instance
(二)实例化后的类属性
1. data 属性
2. 实际应用
(1)单个数据模型
(2)多个数据模型
(三)实例化后的类方法
1. is_valid( ) 方法
(1)作用
(2)参数raise_exception
(3)配合validate_字段
2. save() 方法
3. 两者举例
(1)简单举例
(2)完整应用
(四)运行查看
1. 设置路由(urls)
2. 运行情况
五、问题解决
1. ValidationError({'non_field_errors': [ErrorDetail(string='Expected a list of items but got type "dict".', code='not_a_list')]})
2. "The field 'XXX' was declared on serializer SerializerRecipeBodySave, but has not been included in the 'fields' option."
一、restful 、django-rest-framework 、swagger 三者的关系
(一)restful API(REST API)
1. rest
架构的设计风格,即架构规范(该篇文章主要针对接口的请求方式)。
2. restful
符合rest原则的开发理念(设计标准)。
3. api
通讯接口。
4. restfulAPI
使用REST风格理念的接口(每一种请求API,对应后端的一种数据库操作)。
(二)django-rest-framework(简称DRF)
是针对Django,生成restfulAPI的框架(序列化)。
即,给Django提供了跨平台跨语言的Web API框架。
需安装依赖 djangorestframework,settings.py的INSTALLED_APPS引入rest_framework。
(三)swagger
针对django-rest-framework(DRF),遵循rest风格理念(restful),生成接口开发文档的工具(UI 界面,可测试、也方便前后端对接)。
需安装依赖 drf-yasg,settings配置INSTALLED_APPS引入drf_yasg。
swagger的应用,可参考另一篇文章:Backend - Django Swagger-CSDN博客
二、DRF 基础配置
(一)安装依赖
pip install djangorestframework==3.14.0(二)配置环境
# settings.py文件中
INSTALLED_APPS = [
...
'rest_framework',
...
]三、自定义序列化器(定义序列化类,serializers)
主要针对Serializers.py 和Models.py。
(一)Django 序列化 & DRF 序列化器
1. Django 序列化
针对DRF的序列化器的应用来讲:
(1)序列化
序列器将orm模型或queryset物件转换成字典,再由response把字典转换成json的过程。
即,后端传数据给前端时,将“查询集QuerySet格式”,最终序列化转为“json格式”。
(2)反序列化
序列化器将request获取的json数据转化为python对象。
即,前端将数据传给后端时,将json数据,最终反序列化为python对象。
2. DRF 序列化器
虽然,Django有自带的序列化类(serializers类),但DRF提供的序列化器更实用。
(二)序列化类
序列化器的序列化类有3种:
Serializer、ListSerializer、ModelSerializer(最常用的)
(三)常用字段
1. 序列化器的常用字段
CharField,IntegerField,DateField、BooleanField
2. 自定义字段类型
# 例如自定义Combobox
# 自定义复选框字段类型
class Combobox(serializers.Serializer):
bookname = serializers.CharField()
bookid = serializers.IntegerField()
# 使用复选框字段
class SerializerAuthor(serializers.Serializer):
age = serializers.BooleanField()
name = serializers.CharField()
books = Combobox(many=False)3. 字段的many参数
序列化单个对象,默认参数many=False
序列化多个对象,指定参数many=True
4. 字段的多关系子序列化
(1)source参数的使用
① 重命名字段
自定义返回给前端的字段名。
② 跨表
获取外键表的字段。
③ 执行方法
执行model模型类内的自定义方法。
# models.py
class BookType(models.Model):
bid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
color = models.CharField(max_length=32)
fontsize = models.CharField(max_length=32)
fontcolor = models.CharField(max_length=32)
class PublishPlace(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
status = models.BooleanField(default=True, db_index=True)
city = models.CharField(max_length=32)
email = models.CharField(max_length=32)
class Author(models.Model):
aid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField(default=10)
sex = models.CharField(max_length=32)
birthday = models.DateField()
class Book(models.Model):
bid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
booktype = models.ForeignKey(to='BookType', to_field='bid', on_delete=models.CASCADE)
publish = models.ForeignKey(to='PublishPlace', to_field='pid', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
def __str__(self):
return self.name
# 取出该书的出版社
def getpublishdata(self):
return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email}
# 取出该书的所有作者
def all_author(self):
return [{'id': author.aid, 'name': author.name, 'age': author.age} for author in self.authors.all()]
# serializers.py
from rest_framework import serializers
from myAPP import model # 引入model.py
class AuthorSerializer(serializers.ModelSerializer):
class Meta:
model = Author
fields = "__all__"
class SerializerBook(serializers.ModelSerializer):
authors = AuthorSerializer(many=True)
book_price = serializers.CharField(source='price') # price是数据库字段,book_price 是自命名的。
book_type = serializers.CharField(source='booktype.name') # booktype是关联“书籍类型表”的外键字段。name是“书籍类型表”的字段。
publish2 = serializers.DictField(source="getpublishdata") # 字典形式(执行模型类的方法)
class Meta:
model = model.Book
fields = [ 'name', 'publish', 'authors', 'Publish2', 'book_price','book_type']
# fields是设置最后返回的数据有哪些。book_price和book_type、Publish2 是上方自定义的字段名。 name、Publish、authors是数据库原本的字段名。(2)SerializerMethodField的使用
需要搭配 get_XXX( ) 方法。
可自定义返回给前端的字段值格式。
一般用于跨表查询。
# serializers.py
class SerializerBook(serializers.ModelSerializer):
publish = serializers.SerializerMethodField() #设置序列化,才能用下面的get__XXX()方法。
booktype = serializers.SerializerMethodField()
class Meta:
model = model.Book
fields = ['publish']
def get_publish(self, obj): # 自定义返回的数据格式
return {'label': obj.city, 'value': obj.email} # city和email都是publish字段关联到的外表publishplace表的字段
def get_booktype(self, obj):
booktypes=obj.booktypes.all() # 全部书籍样式
b_list=list()
for booktype in booktypes:
b_list.append({'name':booktype.color,'age':booktype.fontsize})
return b_list5. fields的必要性
自定义的字段、前端展示的字段,都需要在fields中填写。
6. exclude
排除不需要显示的字段。
注意:fields和exclude不能共存。
7. validate_字段名
写在序列化器中(serializers.py中)。
需要搭配实例化后的is_valid()方法(views.py中)。实例化序列化器在后面的模块中会讲。
class BookInfoSerializer(serializers.Serializer):
price = serializers.BooleanField()
name = serializers.CharField()
class Meta:
model = model.Book
fields = [ 'name', 'price','booktype']
# ① 验证单个字段
def validate_booktype(self, value):
if '教育' not in value:
raise serializers.ValidationError("该书籍不属于教育")
return value
# ② 验证多个字段
def validate(self, vals):
price = vals['price']
booktype = vals['booktype']
if booktype =='教育' and price > 100
raise serializers.ValidationError("该教育书籍价格大于100")
return value(四) 创建序列化器(定义序列化类)
上述自定义序列化器中的一些相关实例,也有讲创建序列化器。
1. 一般写法
# 在myBook项目下新建book_serializer.py文档
from book_models import Book, Author
from rest_framework import serializers
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book # model名
fields = '__all__'2. 公共字段
# 在myBook项目下新建book_serializer.py文档
from book_models import Book, Author
from rest_framework import serializers
# 不同的序列化,有共同字段
class BaseData(serializers.ModelSerializer):
decription = serializers.CharField()
class BookSerializer(BaseData):
class Meta:
model = Book # model名
fields = ['name', 'card', 'place', 'author', 'decription']
class AuthorSerializer(BaseData):
class Meta:
model = Author # model名
fields = ['name', 'sex', 'age', 'place', 'decription'] 四、使用序列化器(实例化)
主要针对views.py。
(一)构造序列化对象
Serializer(instance=None, data=empty, **kwarg) # 构造方法,初始化其中,可传入 instance, data 等参数。
1. data
是需要验证的资料,预设为empty。
2. instance
格式:是针对某条queryset数据,预设为None。
作用:
实例化serializer(创建序列化对象)时,根据是否传入instance参数,判断执行update还是create。
即,若传入的instance有值时,则instance.save调用update方法;
反之,若传入的instance为None(或没有传instance)时,则instance.save调用create方法。
(二)实例化后的类属性
1. data 属性
获取序列化后的数据。
2. 实际应用
(1)单个数据模型
# 在myBook项目下新建views_book.py文档
from rest_framework.generics import GenericAPIView
from django.http import JsonResponse
from django.db import transaction
from book_models import Book
from book_serializers import BookSerializer
class BookView(GenericAPIView):
def get(self, request, *args, **krgs):
books_qst = Book.objects.get(id=1) # 获取单笔数据
book_seri = BookSerializer(books_qst, many=True) # 数据转换,即数据序列化
res = book_seri.data # 获取数据 {'id': 1, 'bookname': '数据结构', 'author': '萝卜干'}
return JsonResponse(res)(2)多个数据模型
# 在myBook项目下新建views_book.py文档
from rest_framework.generics import GenericAPIView
from django.http import JsonResponse
from django.db import transaction
from book_models import Book
from book_serializers import BookSerializer
class BookView(GenericAPIView):
def get(self, request, *args, **krgs):
books_qst = Book.objects.all() # 查询数据库,获取多笔数据
book_seri = BookSerializer(books_qst, many=True) # many=True,表示序列化多条数据
res = book_seri.data # 获取数据 [('id', 1), ('bookname', '数据结构'), ('author', '萝卜干')]
return JsonResponse(res, safe=False) # 结果是列表,则需声明safe=False(三)实例化后的类方法
1. is_valid( ) 方法
(1)作用
验证newdata是否符合数据库数据规范。
(2)参数raise_exception
raise_exception=True # 若验证时出现异常,会接收到此异常,向前端返回HTTP 400 响应。
(3)配合validate_字段
在上述自定义序列化器的模块中,有讲解如何使用。
2. save() 方法
保存当前数据。
3. 两者举例
(1)简单举例
bookins = models.Book.objects.first()
myserializer = BookSerializer(instance=bookins, data=newdata, partial=True)
myserializer.is_valid(raise_exception=True)
myserializer.save()(2)完整应用
# 在myBook项目下新建views_book.py文档
from rest_framework.generics import GenericAPIView
from django.http import JsonResponse
from django.db import transaction
from book_models import Book
from book_serializers import BookSerializer
class BookView(GenericAPIView):
def post(self, request, *args, **krgs):
book_data = request.data
try:
serializer =BookSerializer(data=book_data) # 更改数据库
serializer.is_valid(raise_exception=True) # 检查是否合格
with transaction.atomic():
serializer.save()
res = serializer.data # 获取序列化后的数据
except Exception as e:
res = {'error': str(e)}
return JsonResponse(res)(四)运行查看
1. 设置路由(urls)
展示序列化数据的整体流程,涉及models、serializers、views、urls 模块。
# 在myPro项目下新建urls.py文档
from django.urls import path, re_path # url规则
from myBook import views_book as book_view
urlpatterns = [
...
path('book/', book_view.BookView.as_view()),
] 2. 运行情况
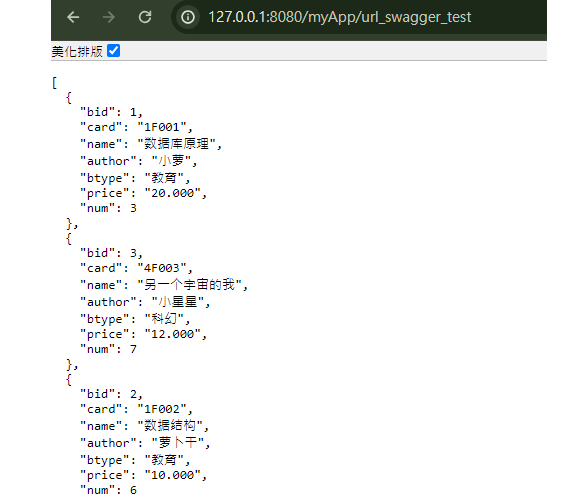
浏览器输入链接,回车。
链接:http://127.0.0.1:8080/myApp/book
展示界面如下:
五、问题解决
1. ValidationError({'non_field_errors': [ErrorDetail(string='Expected a list of items but got type "dict".', code='not_a_list')]})
原因:在使用序列化时,many设置了为True。表示存入多笔,但实际若只存单笔,则会报错。
解决:many设置为False,或删除该属性。
2. "The field 'XXX' was declared on serializer SerializerRecipeBodySave, but has not been included in the 'fields' option."
原因:字段 XXX 已在序列化程序上声明,但尚未包含在fields“字段”选项中。
解决:在 fields = ( ) 中加上该字段。