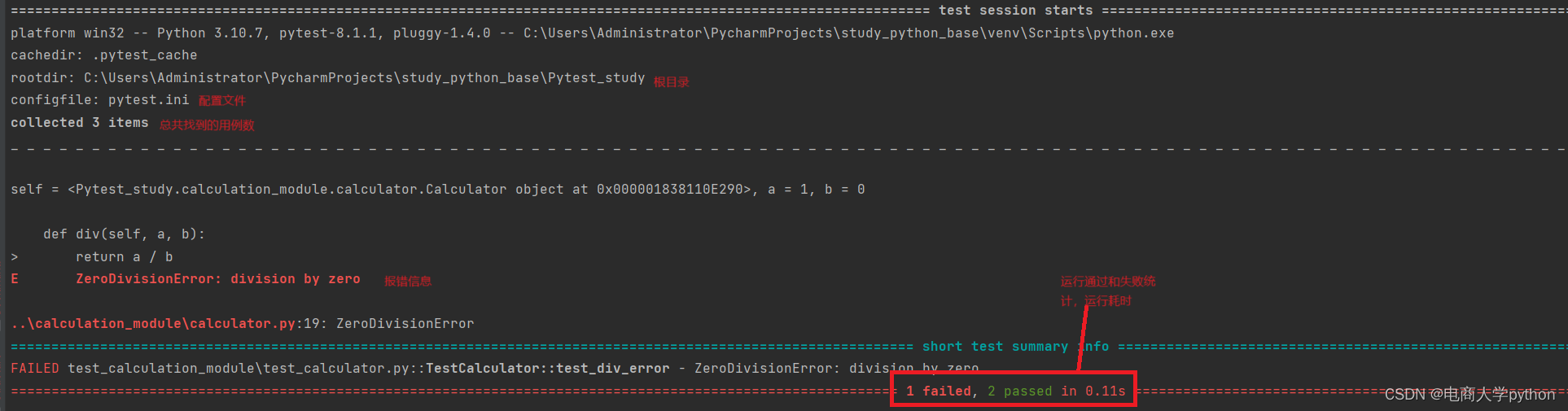
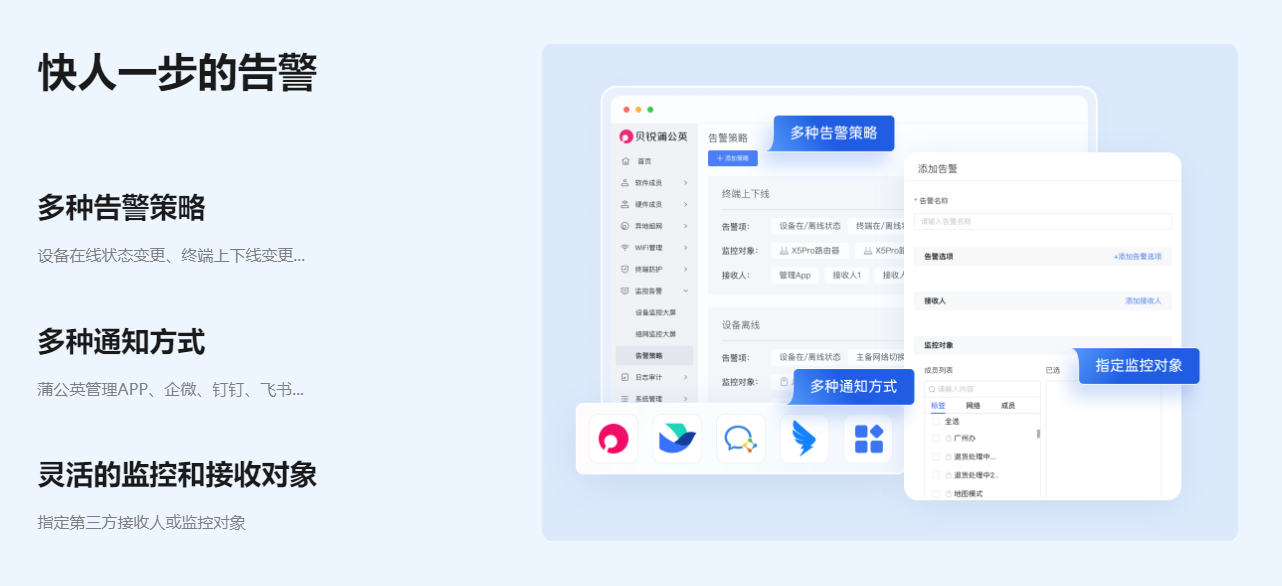
如何让大语言模型(LLMs)“智能涌现”?关键技术之一是思维链(Chain of Thought,CoT),它通过引导大模型,一步一步模拟人类思考过程,可有效增强大模型的逻辑推理能力。
而自洽性方法(Self-Consistency,SC)一直是思维链推理中广泛使用的解码策略。SC 通过生成多个思维链并取多数答案作为最终答案,来提高模型的性能。尽管在各种多步推理任务中带来了显著的性能提升,但它是一种高成本的方法,需要进行预设大小的多次采样。
在 ICLR 2024 上,小红书搜索算法团队提出一种简单且可扩展的采样过程 —— 即早停自洽性方法(Early-Stopping Self-Consistency,ESC),它能在不牺牲性能的情况下,大幅度降低 SC 的成本。在此基础上,团队进一步推导出一种 ESC 控制方案,以动态选择不同任务和模型的性能-成本平衡。
随后,小红书和北理工的研究者们选择了三种主流推理任务(数学,常识和符号推理),并利用不同规模的语言模型进行实验。实验结果显示,ESC 在六个基准测试中显著降低了平均采样次数,包括 MATH(-33.8%),GSM8K(-80.1%),StrategyQA(-76.8%),CommonsenseQA(-78.5%),Coin Flip(-84.2%)和 Last Letters(-67.4%),同时几乎保持原有性能。
这说明了 ESC 的有效性和创新性,它能够在保证推理性能的同时显著减少采样次数,从而降低计算成本。这一点对于大语言模型非常重要,因为这些模型的推理过程通常需要大量的计算资源。

在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。基于此,由于复杂推理任务通常允许有多条推理路径指向正确答案,先前的研究者引入了一种称为自洽性(Self-Consistency,SC)的解码策略,以进一步提高推理性能。
与传统只生成单一路径(greedy search)的标准思维链提示相比,SC 方法会根据预设的样本规模采样多条推理路径,并通过投票机制确定最终答案。尽管这种方法有效,但它会产生与采样数量成正比的显著开销。以 GPT-4 为例,若采样量为 40,在 MATH 数据集测试一次,成本需要高达 2000 美元,这迫切需要一种降低 SC 成本的改进方法。
在 SC 中,生成多个样本的过程可以被视为近似 LLM 预测的真实答案分布。通过选择出现频率最高的结果作为最终答案,可以减少单一采样策略带来的随机性。然而,考虑到 SC 只需要最置信的答案,并不要求整个答案分布完美匹配。因此,我们认为没有必要直接为每个输入生成与预设采样大小对齐的所有推理路径。相反,生成过程可以被序列化为较小的部分,每个部分被命名为一个采样窗口。考虑到小窗口和大量的采样输出都源自同一预测答案分布,采样窗口可以被视为一个探针,仅通过少量的采样数就可以揭示真实分布的一些信息。
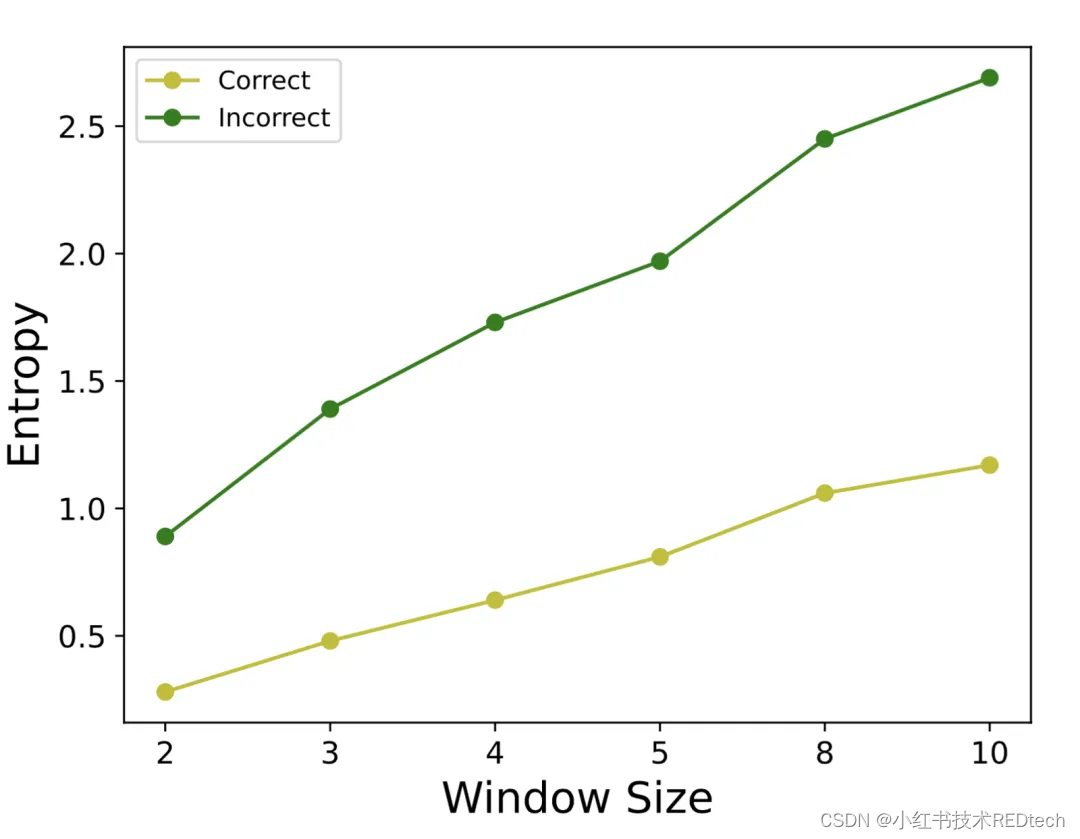
图 1 : GPT-4 在 MATH 数据集采样窗口内的平均熵得分
对于答案分布,一个猜想是正确答案的候选分布通常较为集中,而错误答案则相对分散。我们使用熵作为答案分布形状的表示。上图分别展示了窗口内正确和错误投票答案分布的平均熵值,结果表明,具有较高概率的正确答案通常伴随着较低的熵值,因此熵值可以作为一个指标来确定是否继续采样。
基于此,我们提出了早停自洽性方法(Early-Stopping Self-Consistency,ESC) ,即在低熵窗口截断采样过程。为了尽可能地保持性能,我们设置最严格的阈值:熵等于零,即窗口内生成的所有样本都有相同的答案。发生这种情况时停止采样,既能减少采样消耗,同时将性能影响降至最低。
早停止(Early-Stopping)是一种被广泛用于训练模型时的技术,以防止过拟合现象发生。在本文中,我们引入早停止策略,应用于减少多次采样过程的成本。与原始的 SC 相同,ESC 是完全无监督且与模型无关,无需任何人工注释或额外训练。我们推导出了在 SC 中有或无早停止方法的结果不一致概率的理论上限,结果表明 ESC 有极大的概率保持性能。此外,我们还提出一个 ESC 动态控制方案:通过选择窗口大小和最大采样次数,动态地为不同任务和模型找到最佳的性能-成本平衡点,以满足实际需求。

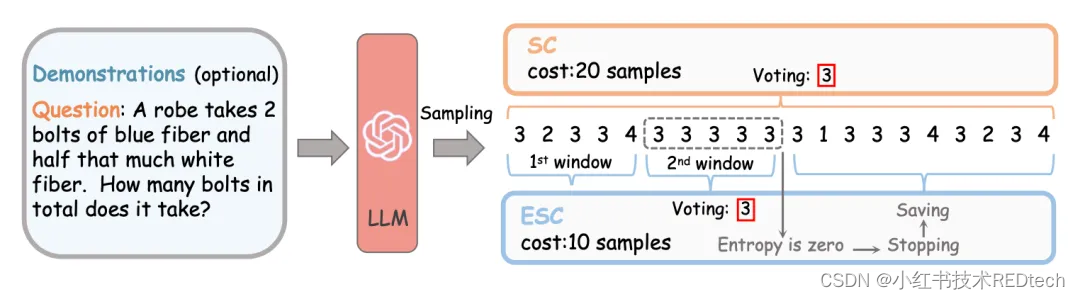
如图展示 ESC 与原始 SC 的完整过程对比。我们将大采样量(在本例中等于 20)分成几个连续的小窗口(在本例中为 5),当一个窗口内的答案都相同时停止采样,即预测答案分布的熵值为零。
2.1 自洽性方法分析
自洽性方法的核心思想在于,对于一个复杂问题,通常允许有多种推理思路,这些思路最终都能导向相同的正确答案。基于此,在采样量为 L L L 下的投票过程可以表述为:
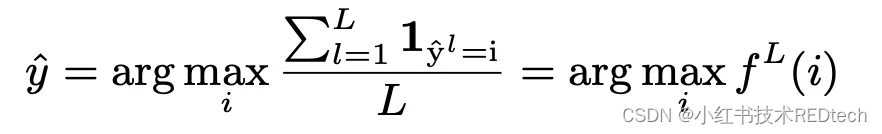
其中
f
L
(
i
)
f^L(i)
fL(i) 表示在
L
L
L 个采样实例中,模型的预测结果为
i
i
i 的频率。根据大数定律,当
L
L
L 趋近于无限时,采样结果的分布将逼近模型预测的真实分布结果
P
(
i
)
P(i)
P(i)。进一步地,我们可以得出:
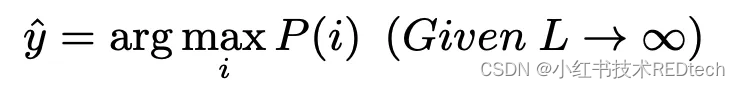
通过上述公式,我们可以看到,多次采样的过程能减轻单次采样引入的噪声,从而提升性能。我们的目标是确保选择那个具有最高概率的预测结果,作为最终答案。从这个角度分析,答案分布熵与性能表现成正相关关系,也就是说,当答案分布的熵较低时,我们只需要较少的采样次数 L 就能够显著减少采样噪声的影响。
2.2 早停自洽性方法
依据 2.1 的分析,我们设计了一种多路采样的动态截断策略,实现以更少成本获得与原始采样量相当的性能表现。具体而言,我们以滑动生成窗口代替一次性生成所有样本,并利用窗口内的分布熵或相似度作为截断条件进行早停操作。
当窗口内的所有预测结果一致时,答案分布的熵为 0,这表明该样本的投票结果与理论上采样次数无限多时的结果高度一致。因此,一旦出现这种情况,我们便停止进一步采样。
如果在采样过程中没有遇到满足条件的观察窗口,将迭代以获得多个观察窗口,直到达到预设的采样大小 L L L。算法流程如算法 1 所示:

为了评估引入早停止机制对结果一致性的影响,我们进行 Z Z Z 检验,以计算在 SC 中采用或不采用早停止方案的结果不一致概率的理论上限。结果表明,当窗口大小为 8 时,ESC 与 SC 结果不一致的概率小于 0.002。这验证了 ESC 在保持性能的同时,能够有效减少采样次数。
2.3 动态控制方案
为适应不同的预算与性能需求,我们研究了 ESC 的动态控制方案来调整截断策略,推导适合的窗口大小与最大采样数(窗口大小 w w w,最大采样数量 L L L)。
我们提出一种用于动态截断的控制模式:将基于第一个观察窗口(将其窗口大小表示为 w 0 w_0 w0),可以推导不同窗口大小( w w w)和最大采样量( L L L)设置下的推理性能和采样成本的期望:
采样数 L L L 的期望为:
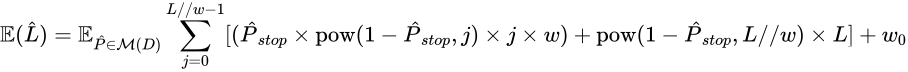
截断结果与原始结果不一致的上界为:
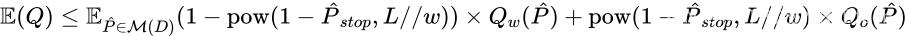
最后,考虑到采样预算和性能要求,根据各自的预期值选择适当的( w w w, L L L)值来执行 ESC。算法流程如算法 2 所示:


我们对提出的 ESC,在三类推理任务的六个基准数据集上进行评估 :
-
算术推理:数据集使用 MATH 和 GSM8K
-
常识推理:数据集使用 CommonsenseQA 和 StrategyQA
-
符号推理:数据集使用 Last Letter Concatenation 和 Coin Flip
ESC 在三种不同规模的语言模型上进行评估:GPT-4、GPT-3.5-Turbo 和 LLaMA-2 7b。所有实验都在 few-shot 设置下进行,无需训练或微调语言模型。对于 MATH 数据集,采样温度 T T T 为 0.5,而其他数据集则设为 0.7。
3.1 ESC 的实验结果
我们比较基线是 greedy search 的思维链提示(CoT)和 SC。
MATH 数据集的采样大小 L L L 为 64,其他数据集为 40,ESC 使用相同的值作为最大样本量。
相应地,MATH 数据集的窗口大小 w w w 为 8,其他数据集为 5。我们报告的结果是基于 10 次运行的平均值,由于空间有限,省略了方差数据。 L L L 是 ESC 平均采样数量, L L L-SC 表示采样大小为 L L L 的 SC 的准确性。
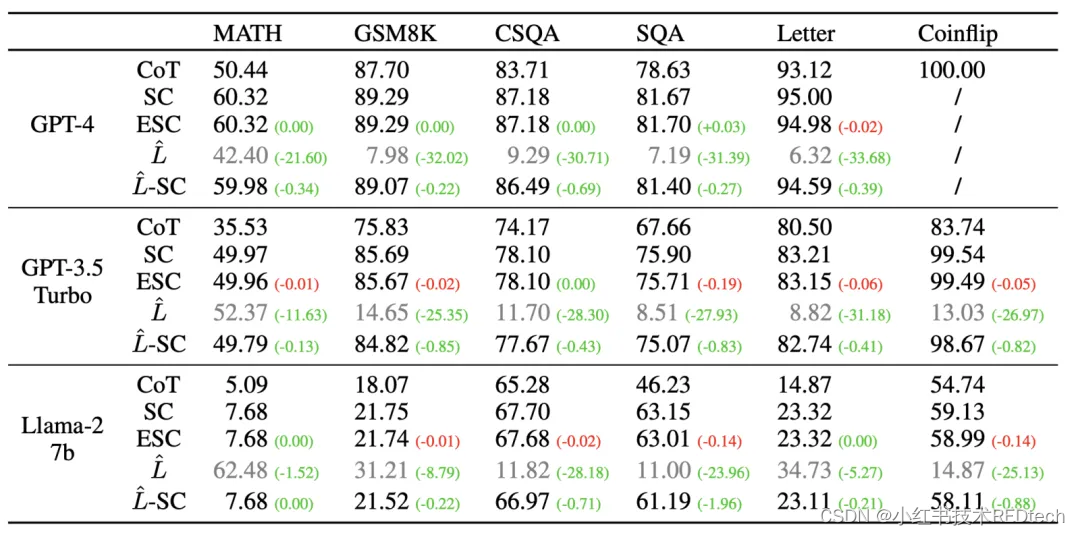
表 1 : 六个推理任务上的测试结果
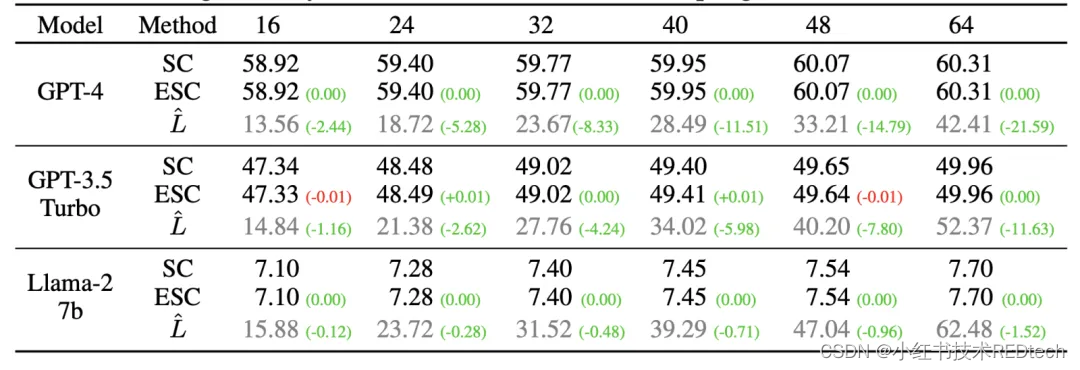
表 2 : MATH 数据集上不同最大采样大小 L 的推理准确性(%)
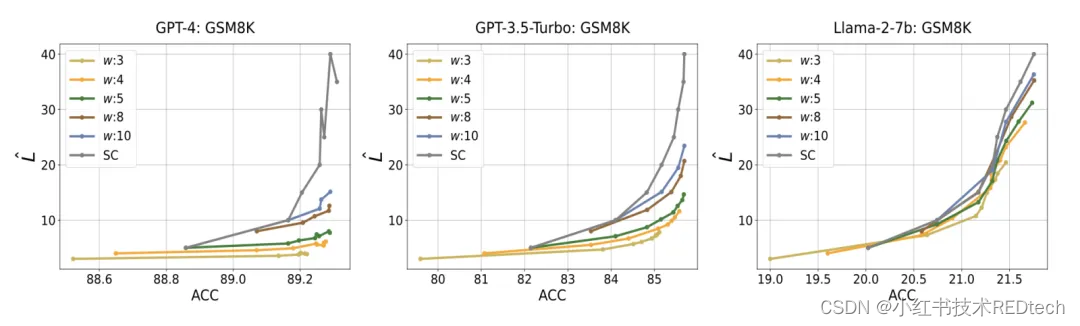
图 3 : GSM8K 数据集上不同模型下观测窗大小 w w w 的鲁棒性分析
根据以上结果,可以得出以下三点结论:
ESC 在几乎不影响性能的情况下显著降低了成本
SC 显著优于 CoT,证实投票过程对推理的有效性。对于 ESC,L 远小于相应的最大采样大小,而性能几乎保持不变。我们还用 L 作为采样大小来测试 SC,其准确度大幅下降。总体而言,ESC 可以显著降低成本,同时几乎不会影响性能。在相同的采样成本下,ESC 可以获得更高的精度。
ESC是一个对于最大采样量和窗口大小鲁棒的解码过程
表 2 和图 3 分别显示了不同最大采样大小和窗口大小下的性能表现。可以看到,ESC 对于最大采样量和窗口大小鲁棒。随着采样大小的增加,SC 的性能不断提高。在此基础上,ESC 可以显著节省成本,同时保持性能。
成本节省与性能表现呈正相关
如表 1 和表 2 所示,一个明显的现象是成本节约与性能呈正相关。这是因为更佳的性能通常不需要更大的采样量。然而,ESC 不需要任何模型能力和任务难度的先验知识。
3.2 动态控制方案的实验结果
为了验证 ESC 动态控制方案的有效性,我们在 GSM8K 数据集上分别对比真实与预测的采样量,以及性能变化百分比。
选用 L1 正则以及皮尔逊相关系数来反应相关性,结果如下表 3 所示。结果表明,我们基于动态控制方案获得的预测,对于平衡采样成本和投票性能是高度可靠的。

表 3 : 动态控制方案实验结果
3.3 ESC在开放域的实验结果
原始的 SC 仅适用于具有固定答案的问题,而 Jain 等人提出 UCS,通过文本相似性匹配取代投票,将 SC 扩展到开放式生成任务。
我们在 MBPP 数据集上,针对不同采样大小(窗口大小为 5 )进行了 ESC 实验。实验结果显示,ESC 同样适用于开放式任务。

表 4 : ESC在开放域的实验结果
3.4 ESC的鲁棒性研究
我们进行一系列额外的实验,以进一步测试 ESC 的鲁棒性,包括对采样参数和提示的稳健性测试:
在图 4 上半部分中,我们展示了随着解码采样温度的升高,ESC 对采样量的节省是鲁棒的。
图 4 左下部分表明,ESC 对 t o p − p top-p top−p 采样的 p p p 值是鲁棒的。
图 4 右下部分表明,ESC 可以推广到 zero-shot 方式。
表 5 显示不同示例(demonstrations)组的 ESC 和 SC 的准确性,可以看到,ESC 对各种示例都是稳健的。
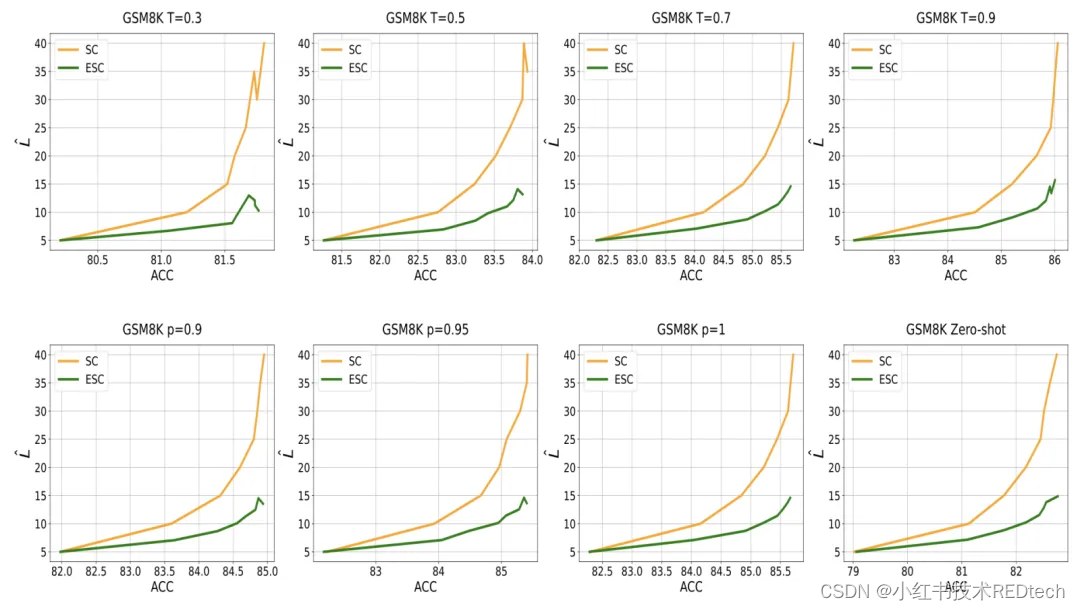
图 4 : ESC关于采样温度 T T T、 p p p 值的鲁棒性分析,以及 zero-shot 结果

表 5 : 不同示例组的实验结果

本项工作引入了一个简单而有效的采样过程,称为早停自洽性(ESC)。通过在高置信度窗口停止解码过程,ESC 在不牺牲性能的情况下大大降低了 SC 的成本。我们进一步推导出 ESC 的控制方案,以动态选择不同任务和模型的性能-成本平衡,不需要额外的模型能力和任务难度的先验知识。
实验结果显示,ESC 在六个主流的基准测试中显著减少了自洽性推理的实际样本数量,同时达到了类似的性能,这对于大模型推理非常重要,可以显著节省大模型推理成本。我们还展示了 ESC 的控制方案可以准确预测各种任务和模型的性能-成本权衡,可以更好的满足实际的预算与性能需求。分析实验结果表明,考虑到不同的解码设置和示例,甚至在开放式生成任务上,ESC 都可以鲁棒地大幅节省成本。
论文地址:https://arxiv.org/abs/2401.10480

-
李易为
现博士就读于北京理工大学,小红书社区搜索组实习生,在 ICLR、AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文,主要研究方向为大语言模型推理与蒸馏、开放域对话生成等。
-
袁沛文现博士就读于北京理工大学,小红书社区搜索组实习生,在 NeurIPS、ICLR、AAAI 、EACL 等发表多篇一作论文。主要研究方向为大语言模型推理与评测、信息检索。
-
冯少雄
负责小红书社区搜索向量召回。博士毕业于北京理工大学,在 ICLR、AAAI、ACL、EMNLP、NAACL、EACL、KBS 等机器学习/自然语言处理领域顶级会议/期刊上发表数篇论文。主要研究方向为大语言模型测评推理蒸馏、生成式检索、开放域对话生成等。
-
道玄
小红书交易搜索团队负责人。博士毕业于浙江大学,在 NeurIPS、ICML 等机器学习领域顶级会议上发表数篇一作论文,长期作为多个顶级会议/期刊审稿人。主要业务覆盖内容搜索、电商搜索、直播搜索等。
-
曾书
小红书社区搜索语义理解与召回方向负责人。硕士毕业于清华大学电子系,在互联网领域从事自然语言处理、推荐、搜索等相关方向的算法工作。

小红书社区搜索算法工 程师(全职 / 实习)
岗位职责:
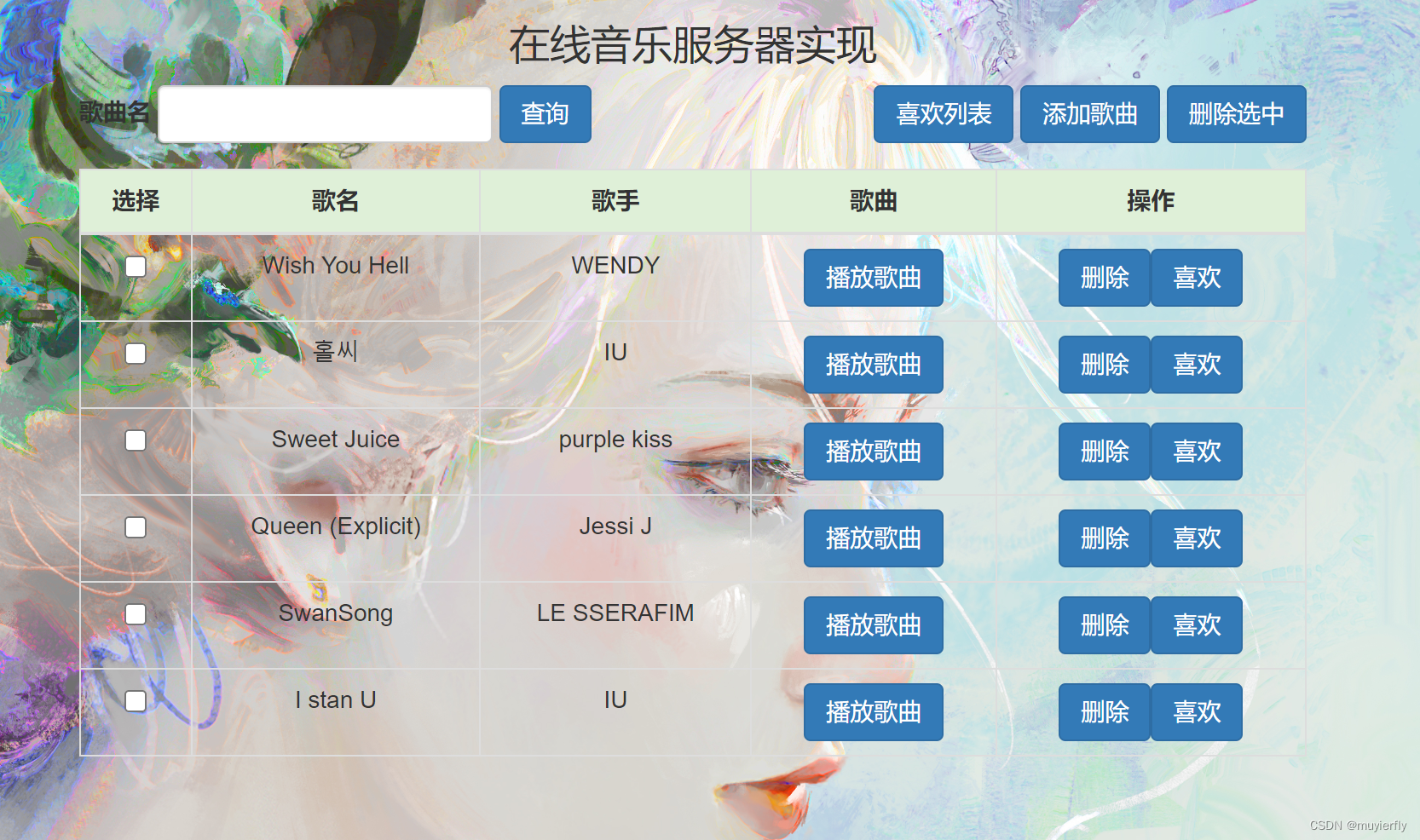
1、对小红书搜索效果进行优化,包括搜索算法和策略的调研、设计、开发、评估等环节,提升用户体验;
2、发现并解决搜索场景中在查询分析、意图识别、向量召回、排序模型、去重等方向的问题;
3、解决小红书搜索实际问题,更好地满足用户的搜索需求;
4、跟进业内搜索相关模型和算法的前沿进展,并在实际业务中进行合理应用。
任职资格:
1、本科及以上学历,计算机相关专业背景;
2、有搜索、推荐、广告、图像识别等相关背景优先;
3、熟悉机器学习、NLP、数据挖掘、知识工程的经典算法,并能在业务中灵活解决实际问题;
4、在国际顶级会议(KDD、SIGIR、WSDM、ICLR、NeurIPS、ICML、ACL、EMNLP 等)以第一作者发表过高水平论文者、知名数据挖掘比赛(例如 KDD Cup 等)中取得领先名次者优先;
5、积极向上,踏实勤奋,自我驱动,善于沟通,解决问题优先。
欢迎感兴趣的同学发送简历至 REDtech@xiaohongshu.com,并抄送至 luyun2@xiaohongshu.com、fengshaoxiong@xiaohongshu.com。