- 样本不均衡是什么意思
样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如4:1)就可以归为样本不均衡的问题。
现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。
- 数据不同分布是什么意思
实际预测与训练数据不满足同分布的问题,也就是数据集偏移(Dataset shift),是机器学习一个很重要的问题。不同因素对应着如下三种情况得数据偏移:
Covariate shift:协变量偏移(统计学中的协变量即机器学习中的特征的概念), 指的是输入空间的边缘概率分布P(x),也就输入特征x分布变化导致的偏移。换句话说,就是指训练集和测试集的输入服从不同分布,但背后是服从同一个函数关系,如图所示。
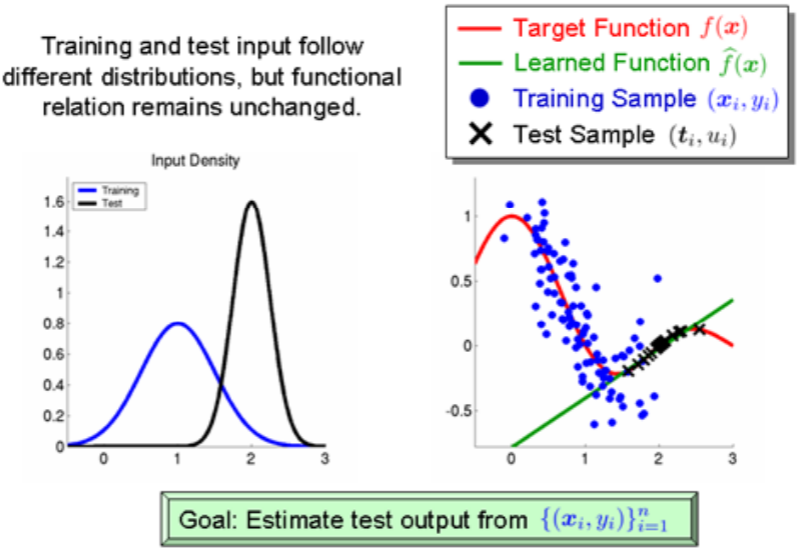
这个应该是最为常见的,比如图像识别任务中,训练时输入的人脸图像数据没戴口罩,而预测的时候出现了很多戴口罩人脸的图像。 再如反欺诈识别中,实际预测欺诈用户的欺诈行为发生升级改变,与训练数据的行为特征有差异的情况。
Prior probability shift:先验概率偏移,指的是标签分布P(Y) 差异导致的。比如反欺诈识别中,线上某段时间欺诈用户的比例 对比 训练数据 突然变得很大的情况。
Concept shift 概念偏移:映射关系偏移,指P(y|x) 分布变化,也就是x-> y的映射关系发生变化。
导致数据分布不同的原因
(1)样本选择偏差(Sample Selection Bias) :分布上的差异是由于训练数据是通过有偏见的方法获得的。例如非均匀选择(Non-uniform Selection),导致训练集无法很好表征的真实样本空间。
比如金融领域的信贷客群是通过某种渠道/规则获得的,后面我们新增加营销渠道获客 或者 放宽了客户准入规则。这样就会直接导致实际客群样本比历史训练时点的客群样本更加多样了(分布差异)。
(2)不平稳环境(Non-stationary Environments):当训练集数据的采集环境跟测试集不一致时会出现该问题,一般是由于时间或空间的改变引起的。
比如金融领域,预测用户是否会偿还贷款的任务。有一小类用户在经济环境好的时候有能力偿还债务,但是由于疫情或其他的影响,宏观经济环境不太景气,如今就无法偿还了。
- 数据不均衡的根本影响
样本不均衡带来的根本影响是:模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)。如下图
类别不均衡情况下的分类边界会偏向“侵占”少数类的区域。更重要的一点,这会影响模型学习更本质的特征,影响模型的鲁棒性。
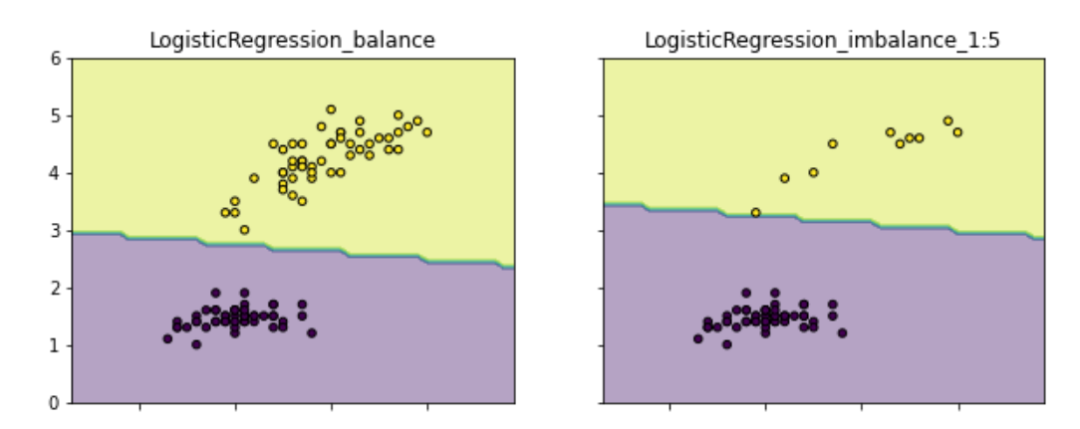
我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
- 什么时候需要解决不均衡问题
判断任务是否复杂:复杂度学习任务的复杂度与样本不平衡的敏感度是成正比的(参见《Survey on deep learning with class imbalance》),对于简单线性可分任务,样本是否均衡影响不大。需要注意的是,学习任务的复杂度是相对意义上的,得从特征强弱、数据噪音情况以及模型容量等方面综合评估。
判断训练样本的分布与真实样本分布是否一致且稳定,如果分布是一致的,带着这种正确点的先验对预测结果影响不大。但是,还需要考虑到,如果后面真实样本分布变了,这个样本比例的先验就有副作用了。
判断是否出现某一类别样本数目非常稀少的情况,这时模型很有可能学习不好,类别不均衡是需要解决的,如选择一些数据增强的方法,或者尝试如异常检测的单分类模型。
- 如何检测数据满足同分布
可能我们模型在训练、验证及测试集表现都不错,但一到OOT(时间外样本)或者线上预测的时候,效果就掉下来了。这时我们就不能简单说是模型复杂导致过拟合了,也有可能是预测数据的分布变化导致的效果变差。我们可以通过如下常用方式检测数据分布有没有变化:
【一文讲通】如何检测数据满足同分布_allein_STR的博客-CSDN博客
- 样本不均衡的解决方法
【一文讲通】样本不均衡问题解决--上_allein_STR的博客-CSDN博客_分类类别不均衡
【一文讲通】样本不均衡问题解决--下_allein_STR的博客-CSDN博客
- 数据分布不同解决办法
【一文速通】数据分布不同解决办法_allein_STR的博客-CSDN博客
- 评价指标
如何更好决策以及客观地评估不平衡数据下的模型表现:
对于分类常用的precision、recall、F1、混淆矩阵,样本不均衡的不同程度,都会明显改变这些指标的表现。
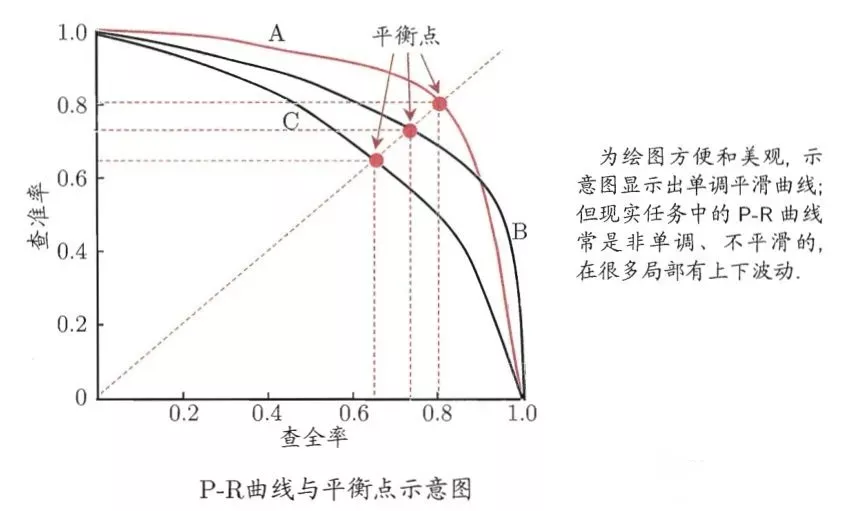
对于类别不均衡下模型的预测,我们可以做分类阈值移动,以调整模型对于不同类别偏好的情况(如模型偏好预测负样本,偏向0,对应的我们的分类阈值也往下调整),达到决策时类别平衡的目的。这里,通常可以通过P-R曲线,选择到较优表现的阈值。
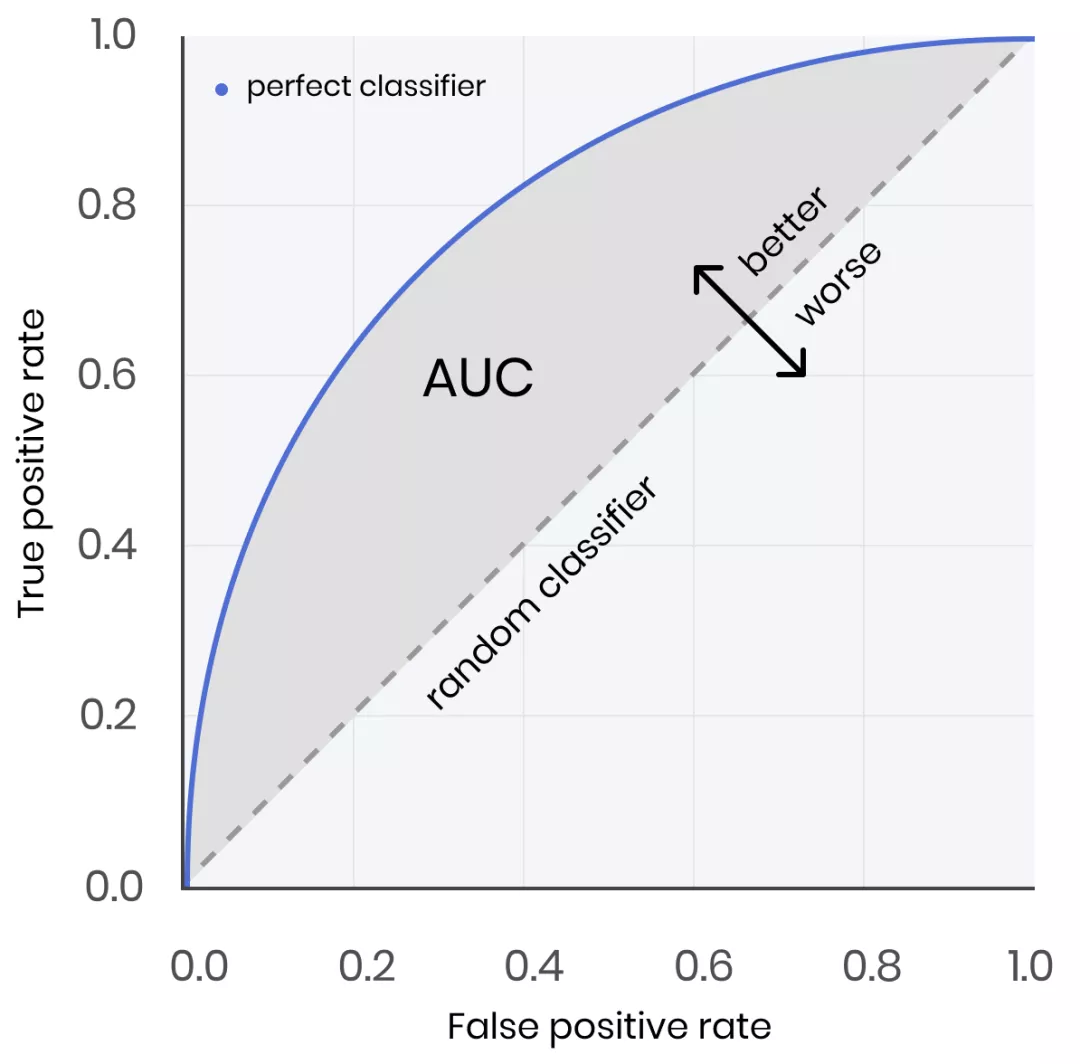
对于类别不均衡下的模型评估,可以采用AUC、AUPRC(更优)评估模型表现。AUC的含义是ROC曲线的面积,其数值的物理意义是:随机给定一正一负两个样本,将正样本预测分值大于负样本的概率大小。AUC对样本的正负样本比例情况是不敏感,即使正例与负例的比例发生了很大变化,ROC曲线面积也不会产生大的变化。
具体可见 机器学习中常用的评价指标_allein_STR的博客-CSDN博客
9. 总结
我们通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
可以将不均衡解决方法归结为:通过某种方法使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的。具体可以从数据样本、模型算法、目标函数、评估指标等方面进行优化,其中数据增强、代价敏感学习及采样+集成学习是比较常用的,效果也是比较明显的。其实,不均衡问题解决也是结合实际再做方法选择、组合及调整,在验证中调优的过程。
参考资料:
[1] Dataset Shift in Classification: Approaches and Problems - Francisco Herrera, PPT: http://iwann.ugr.es/2011/pdf/InvitedTalk-FHerrera-IWANN11.pdf
[2] 2021“AI Earth”人工智能创新挑战赛 - 阿里天池, 比赛: https://tianchi.aliyun.com/competition/entrance/531871/introduction
[3] Kernel Distribution - MathWorks, 文档: https://www.mathworks.com/help/stats/kernel-distribution.html
[4] seaborn.kdeplot(), 文档: http://seaborn.pydata.org/generated/seaborn.kdeplot.html
[5] KS-检验(Kolmogorov-Smirnov test)-- 检验数据是否符合某种分布 - Arkenstone, 博客: https://www.cnblogs.com/arkenstone/p/5496761.html
[6] scipy.stats.ks_2samp(), 文档: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ks_2samp.html
[7] Adversarial_Validation - Qiuyuan918, 代码: https://github.com/Qiuyan918/Adversarial_Validation_Case_Study/blob/master/Adversarial_Validation.ipynb
[8] lightgbm.Dataset(), 文档: https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Dataset.html#lightgbm.Dataset
[9] 蚂蚁金服ATEC风险大脑-支付风险识别--TOP2方案 - 吊车尾学院-E哥, 文章: https://zhuanlan.zhihu.com/p/57347243?from_voters_page=true
[10] 工业大数据之注塑成型虚拟量测Top5分享 - 公众号: Coggle数据科学
[11] 数据敏感度:以AI earth为栗子 - 公众号: YueTan
[12] 伪标签(Pseudo-Labelling)——锋利的匕首 - TripleLift, 文章: https://zhuanlan.zhihu.com/p/157325083
[13] 训练集和测试集的分布差距太大有好的处理方法吗?- 知乎, 文章: https://www.zhihu.com/question/265829982/answer/1770310534
[14] 训练/测试集分布不一致解法总结 (qq.com)
[15] 理解数据集偏移 https://zhuanlan.zhihu.com/p/449101154
[16] 训练/测试集分布不一致解法总结
[17] 训练集和测试集的分布差距太大有好的处理方法吗 https://www.zhihu.com/question/265829982/answer/1770310534
[18] 训练集与测试集之间的数据偏移(dataset shift or drifting) https://zhuanlan.zhihu.com/p/304018288
[19] 数据集偏移&领域偏移 Dataset Shift&Domain Shift https://zhuanlan.zhihu.com/p/195704051
[20] 如何量化样本偏差对信贷风控模型的影响?https://zhuanlan.zhihu.com/p/350616539