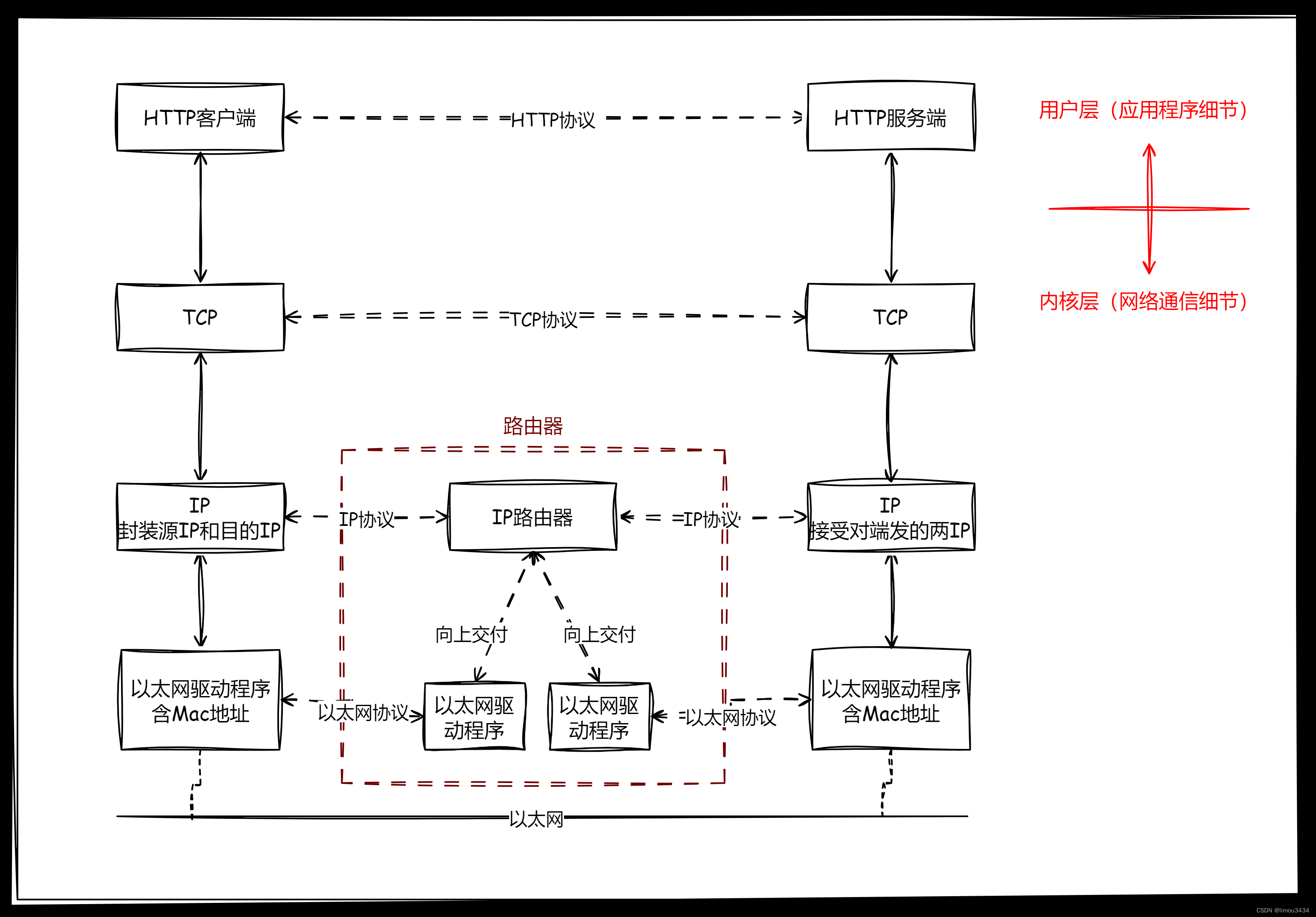
一、下载途径
全国400多个气象站气候数据(1942-2022)
王晓磊:中国空气质量/气象历史数据 | 北京市空气质量历史数据
气象数据免费下载网站整理
中国气象站观测的气象数据怎么下载
二、R语言处理
2.1 提取站点文件
library(dplyr)
library(readxl)
library(openxlsx)
library(tidyverse)
require(devtools)
rm(list=ls())
setwd("E:\\program1\\03-项目进展-3模型模拟结果验证\\input\\20230628 中国气象观测数据")
Stations=read_excel("../city_pre.xlsx",sheet = 1, col_names = c("province","stations","city","lat","lon"), col_types = NULL, na = "", skip = 0)
####Pre 36cities#####
for (i in 1:dim(Stations)[1]) {
station=Stations[i,2]
province=Stations[i,1]
city=Stations[i,3]
station_data <- data.frame()
for (year in 2000:2021) {
infile <- paste0("china_isd_lite_", year, "/", station, "0-99999-", year)
if (file.exists(infile)) {
temp_data <- read.table(infile) %>%
as.tibble() %>%
set_names("Year", "Month", "Day", "Hour", "ATemp", "DPTemp", "SLP", "WDir", "WSpeed", "SkyCover", "LPD1", "LPD6")
station_data <- bind_rows(station_data,temp_data)
} else {
cat("No such file exists:", infile, "\n")
}
}
if (nrow(station_data) > 0) {
output_folder <- "E:/program1/03-项目进展-3模型模拟结果验证/output/PRE_files/"
city_Pre <- paste(output_folder,"Pre_",province,"_",city,"_",station,"_data.csv",sep="")
write.csv(station_data, city_Pre, row.names = T)
}
}
####判断station是否存在####
#获取有文件的站点
row(Stations)#98 5
dim(Stations)[1]#行数
length(row(Stations))#总数行*列
station_data <- data.frame()
for (i in 1:dim(Stations)[1]) {
city=Stations[i,2]
infile <- paste0("china_isd_lite_2020", "/", city, "0-99999-", 2020)
if (file.exists(infile)) {
st <- as.data.frame(Stations[i, ])
station_data <- bind_rows(station_data,st)
}
else {
cat("No such file exists:", infile, "\n")
}
}
output_folder <- "E:\\program1\\04-项目进展-4城市降水量整理\\output\\PRE\\"
city_Pre <- paste(output_folder, "Pre_stations_info.csv", sep = "")
write.csv(station_data, city_Pre, row.names = T)
Sys.setlocale(category = "LC_ALL",locale = "Chinese")
write.csv(station_data, city_Pre, row.names = FALSE,fileEncoding = "UTF-8")
####~~~~~~~~####
#查看结果文件数量
# 指定文件夹路径
folder_path <- "E:\\program1\\04-项目进展-4城市降水量整理\\output\\PRE_Process"
# 列出文件夹中的所有文件
files <- list.files(folder_path)
# 获取文件数量
num_files <- length(files)
# 打印文件数量
print(num_files)
```ruby
library(dplyr)
library(readxl)
library(openxlsx)
library(tidyverse)
require(devtools)
rm(list=ls())
setwd("E:\\program1\\04-项目进展-4城市降水量整理\\output\\")
Stations=read_excel("../input/city_pre.xlsx",sheet = 1, col_names = c("province","stations","city","lat","lon"), col_types = NULL, na = "", skip = 0)
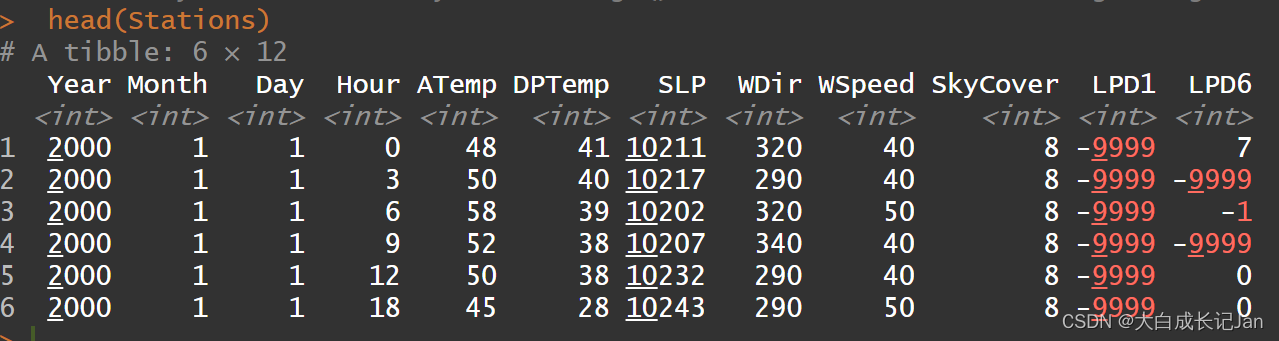
head(file)
2.2降水数据处理
####Pre 36cities#####
folder_path <- "./PRE/" # 替换为实际的文件夹路径
files <- list.files(folder_path, full.names = TRUE)
# 循环处理每个文件
for (file in files) {
#查看字符串长度eg Pre_安徽_合肥_58321_data.csv
a=str_length(file)
#提取字符串从
name <- str_sub(file, start = 7, end =a)
Stations = read.csv(file)%>%
#将文件读取为一个tibble数据框,并修改表头
as.tibble()
head(Stations)
#将降水为-99999和-1的无效值赋值为0
Stations$LPD6[Stations$LPD6 <0] <- 0
#选取列,不要4-11列
data=Stations[,-4:-11]
#删除b,d列的处理方式,-which 可以用!代替
#data[ , -which(colnames(data) %in% c("SLP","WDir"))]
# head(data)
# 将日期列合并为一个新的列
data$Date <- as.Date(paste(data$Year, data$Month, data$Day, sep = "-"))
# 按日期分组,并计算每天的 LPD6 总和
sum_LPD6 <- aggregate(LPD6 ~ Date, data = data, FUN = sum)
# head(sum_LPD6)
# 将年、月、日的列与 LPD6 总和列合并以Date为标准
result <- merge(data, sum_LPD6, by = "Date")
#head(result)
result=result[,-5]
result$LPD6.y=result$LPD6.y/10
data_unique <- unique(result)
# 打印结果
# head(data_unique)
output_folder <- "./PRE_Process/"
city_Pre <- paste0(output_folder,"Pro_",name, sep = "")
write.csv( data_unique, city_Pre, row.names = FALSE)
}
code参考
2000-2020年中国地面气象数据:从NOAA到分省面板
R语言批处理中国地面气候资料日值数据集(V3.0)
使用R语言处理气象站点数据,站点数据批量并行计算合成
R语言处理中国气象数据共享网-中国地面气候资料日值数据集(V3.0)
三、制图
R语言可视化作图