简介
Instagram 是目前最热门的社交媒体平台之一,拥有大量优质的视频内容。但是要逐一下载这些视频往往非常耗时。在这篇文章中,我们将介绍如何使用 Python 编写一个脚本,来实现 Instagram 视频的批量下载和信息爬取。
我们使用selenium获取目标用户的 HTML 源代码,并将其保存在本地:
def get_html_source(html_url):
option = webdriver.EdgeOptions()
option.add_experimental_option("detach", True)
# option.add_argument("--headless") # 添加这一行设置 Edge 浏览器为无头模式 不会显示页面
# 实例化浏览器驱动对象,并将配置浏览器选项
driver = webdriver.Edge(options=option)
# 等待元素出现,再执行操作
driver.get(html_url)
time.sleep(3)
# ===============模拟操作鼠标滑轮====================
i=1
while True:
# 1. 滚动至页面底部
last_height = driver.execute_script("return document.body.scrollHeight")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(4)
# 2. 检查是否已经滚动到底部
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
logger.info(f"Scrolled to page{i}")
i += 1
html_source=driver.page_source
driver.quit()
return html_source
total_html_source = get_h
tml_source(f'https://imn/{username}/')
with open(f'./downloads/{username}/html_source.txt', 'w', encoding='utf-8') as file:
file.write(total_html_source)
然后,我们遍历每个帖子,提取相关信息并下载对应的图片或视频:,注意不同类型的帖子,下载爬取方式不一样
def downloader(logger,downlod_url,file_dir,file_name):
logger.info(f"====>downloading:{file_name}")
# 发送 HTTP 请求并下载视频
response = requests.get(downlod_url, stream=True)
# 检查请求是否成功
if response.status_code == 200:
# 创建文件目录
if not os.path.exists("downloads"):
os.makedirs("downloads")
# 获取文件大小
total_size = int(response.headers.get('content-length', 0))
# 保存视频文件
#
file_path = os.path.join(file_dir, file_name)
with open(file_path, "wb") as f, tqdm(total=total_size, unit='B', unit_scale=True, unit_divisor=1024, ncols=80, desc=file_name) as pbar:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
pbar.update(len(chunk))
logger.info(f"downloaded and saved as {file_path}")
return file_path
else:
logger.info("Failed to download .")
return "err"
def image_set_downloader(logger,id,file_dir,file_name_prx):
logger.info("downloading image set========")
image_set_url="https://imm"+id
html_source=get_html_source(image_set_url)
# # 打开或创建一个文件用于存储 HTML 源代码
# with open(file_dir+file_name_prx+".txt", 'w', encoding='utf-8') as file:
# file.write(html_source)
# 4、解析出每一个帖子的下载url downlod_url
download_pattern = r'data-proxy="" data-src="([^"]+)"'
matches = re.findall(download_pattern, html_source)
download_file=[]
# # 输出匹配到的结果
for i, match in enumerate(matches, start=1):
downlod_url = match.replace("amp;", "")
file_name=file_name_prx+"_"+str(i)+".jpg"
download_file.append(downloader(logger,downlod_url,file_dir,file_name))
desc_pattern = r'<div class="desc">([^"]+)follow'
desc_matches = re.findall(desc_pattern, html_source)
desc=""
for match in desc_matches:
desc=match
logger.info(f"desc:{match}")
return desc,download_file
def image_or_video_downloader(logger,id,file_dir,file_name):
logger.info("downloading image or video========")
image_set_url="https://im"+id
html_source=get_html_source(image_set_url)
# # 打开或创建一个文件用于存储 HTML 源代码
# with open(file_dir+file_name+".txt", 'w', encoding='utf-8') as file:
# file.write(html_source)
# 4、解析出每一个帖子的下载url downlod_url
download_pattern = r'href="(https://scontent[^"]+)"'
matches = re.findall(download_pattern, part)
# # 输出匹配到的结果
download_file=[]
for i, match in enumerate(matches, start=1):
downlod_url = match.replace("amp;", "")
download_file.append(downloader(logger,downlod_url,file_dir,file_name))
# 文件名
desc_pattern = r'<div class="desc">([^"]+)follow'
desc_matches = re.findall(desc_pattern, html_source)
desc=""
for match in desc_matches:
desc=match
logger.info(f"desc:{match}")
return desc,download_file
parts = total_html_source.split('class="item">')
posts_number = len(parts) - 2
logger.info(f"posts number:{posts_number} ")
for post_index, part in enumerate(parts, start=0):
id = ""
post_type = ""
post_time = ""
if post_index == 0 or post_index == len(parts) - 1:
continue
logger.info(f"==================== post {post_index} =====================================")
# 解析出每个帖子的时间和 ID
time_pattern = r'class="time">([^"]+)</div>'
matches = re.findall(time_pattern, part)
for match in matches:
post_time = match
logger.info(f"time:{match}")
id_pattern = r'<a href="([^"]+)">'
id_matches = re.findall(id_pattern, part)
for match in id_matches:
id = match
logger.info(f"id:{id}")
# 根据帖子类型进行下载
if '#ffffff' in part:
post_type = "Image Set"
logger.info("post_type: Image Set")
image_name_pex = "img" + str(post_index)
desc, post_contents = image_set_downloader(logger, id, image_dir, image_name_pex)
elif "video" in part:
post_type = "Video"
logger.info("post_type: Video")
video_name = "video" + str(post_index) + ".mp4"
desc, post_contents = image_or_video_downloader(logger, id, video_dir, video_name)
else:
logger.info("post_type: Image")
post_type = "Image"
img_name = "img" + str(post_index) + ".jpg"
desc, post_contents = image_or_video_downloader(logger, id, image_dir, img_name)
# 将信息写入 Excel 文件
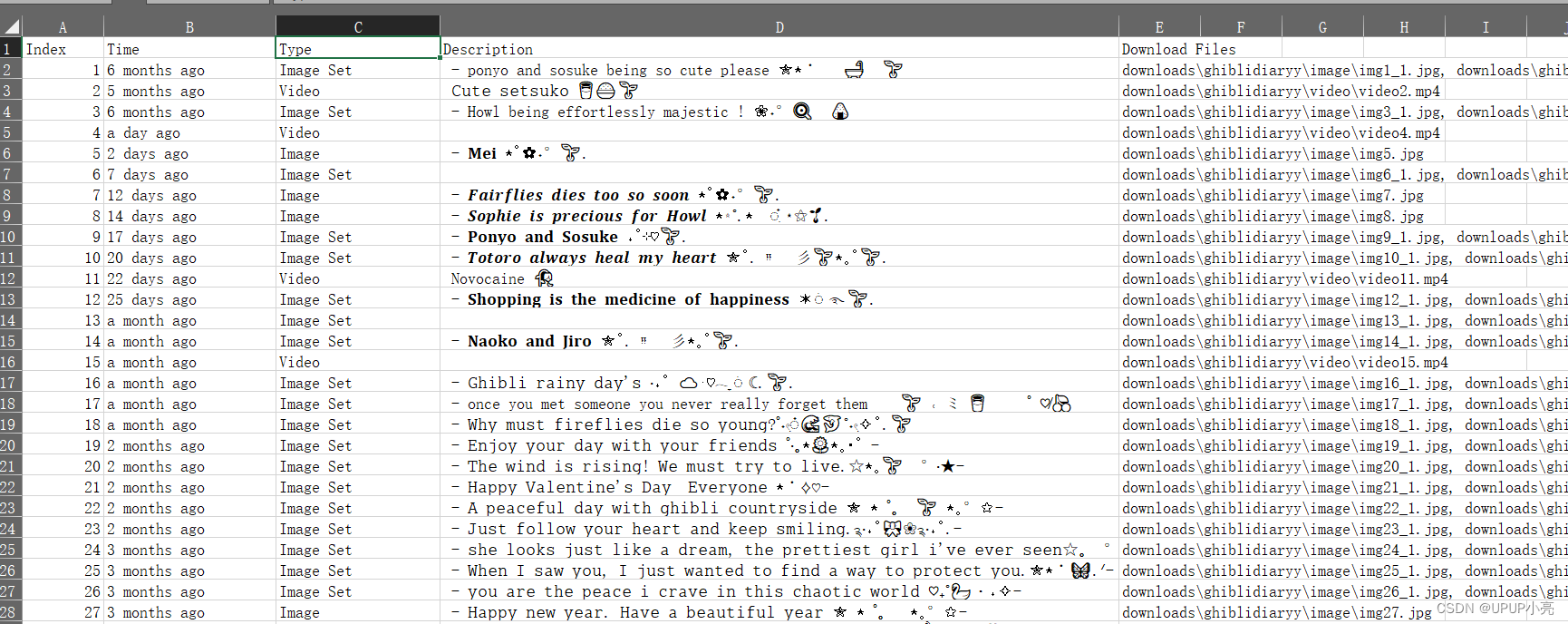
exceller.write_row((post_index, post_time, post_type, desc, ', '.join(post_contents)))
最后,我们调用上述定义的函数,实现图片/视频的下载和 Excel 文件的写入。
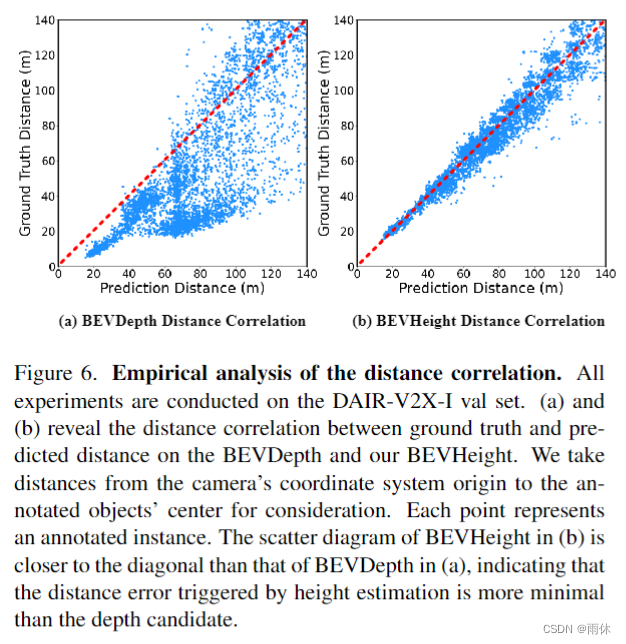
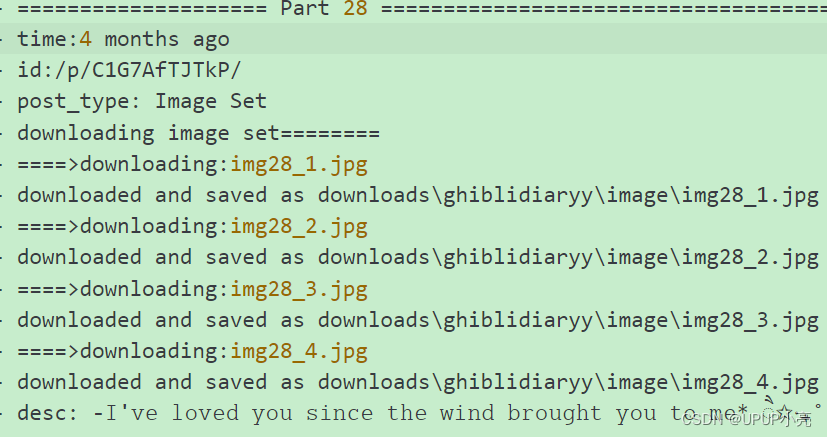
结果展示
源码
想要获取源码的小伙伴加v:15818739505 ,手把手教你部署使用哦