一、MySQL通配符模糊查询(%,_)
1.1.通配符的分类
1.“%”百分号通配符:表示任何字符出现任意次数(可以是0次)
2.“_”下划线通配符:表示只能匹配单个字符,不能多也不能少,就是一个字符。当然也可以like "张__",多个"_",数量不限。
3.like操作符:LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较;但如果like后面没出现通配符,则在SQL执行优化时将like默认为"="执行
1.2.通配符的使用
1.“%”通配符
--模糊匹配含有“嵩”字的数据
select * from table where name like '%嵩%';--模糊匹配以“嵩”字结尾的数据
select * from table where name like '%嵩';--模糊匹配以“嵩”字开头的数据
select * from table where name like '嵩%';--模糊匹配含有“xxx网xxx车xxx”的数据,如“滴滴网约车司机端,网络约车平台”
select * from table where name like '%网%车%';2.“_”通配符
--查询以“网”为结尾的,长度为三个字的数据,如:“链家网”
select * from app_info where appname like '__网'注意:'%__网、__%网'等同于'%网'
--查询前三个字符为xx网,后面任意匹配,如:“城通网盘、模具网平台”
select * from app_info where appname like '__网%';--模糊匹配含义“xx网x车xxx”的数据,如:“携程网约车客户端”
select * from app_info where appname like '__网_车%';注意:%通配符可以匹配任意字符,但是不能匹配NULL,也就是说SELECT * FROM blog where title_name like '%';是匹配不到title_name为NULL的的记录。
1.3.技巧与建议
MySQL的通配符很有用,但是这种功能是有代价的:通配符搜索的处理一般要比其他搜索所花时间更长,消耗更多的内存等资源。
- 不要过度使用通配符,如果其他操作符能达到相同的目的,应该使用其他操作符
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。因为MySQL在where后面的执行顺序是从左往右执行的,如果把通配符置于搜索模式的开始处,搜索起来是最慢的(因为要对全库进行扫描)
- 仔细注意通配符的位置,如果放错位置,可能不会返回想要的数据。
1.4.数据中的“%”、“_”等符合和通配符冲突
使用escape关键字进行转义
如下:escape后面跟着一个字符,里面写着什么,MySQL就把那个符号当做转义符,一般就写成“/”;然后就像c语言中转义字符一样,例如'\n','\t',把这个字符写在需要转义的那个%号前就可以了
SELECT * from app_info where appName LIKE '%/_%' ESCAPE '/'; 二、MySQL内置函数检索(locate,position,instr)
通过内置函数locate,position,instr进行匹配,相当于Java中的str.contains()方法,返回的是匹配内容在字符串中的位置,效率和可用性上都优于通配符匹配。
SELECT * from app_info where INSTR(`appName`, '%') > 0;
SELECT * from app_info where LOCATE('%', `appName`) > 0;
SELECT * from app_info where POSITION( '%' IN `appName`) > 0;如上,三种内置函数默认都是:>0,所以下列>0可加可不加,加上可读性更好
注意:MySQL中的角标从左往右是从1开始的,不像java最左边第一位角标是0,因此在MySQL中角标为0时说明不存在。
2.1.locate()函数
locate(substr,str)返回substr在str中第一次出现的位置。如果substr在str中不存在,返回值为0,如果substr在str中存在,返回值为substr中第一次出现的位置。
locate(substr,str,[pos])从位置pos开始的字符串str中第一次出现子字符串substr的位置。如果substr不在str中,则返回0.如果substr或str为NULL,则返回NULL
SELECT locate('a', 'banana'); -- 2
SELECT locate('a', 'banana', 3); -- 4
SELECT locate('z', 'banana'); -- 0
SELECT locate(10, 'banana'); -- 0
SELECT locate(NULL , 'banana'); -- null
SELECT locate('a' , NULL ); -- null实例:
--用locate关键字进行模糊匹配,等同于:“like '%网%'”
SELECT * from app_info where LOCATE('网', `appName`) > 0;--用locate关键字进行模糊匹配,从第二个字符开始匹配“网”,则“网易云游戏,网来商家”等数据就被过滤了
SELECT * from app_info where LOCATE('网', `appName`, 2) > 0;2.2.position()函数
position(substr in substr)这个方法可以理解为locate(substr,str)方法的别名,因为它和locate(substr,str)方法的作用是一样的。
实例:
--用position关键字进行模糊匹配,等同于:"like '%网%'"
SELECT * from app_info where POSITION( '网' IN `appName`);2.3.instr()函数
instr(str,substr)返回字符串str中第一次出现子字符串substr的位置。instr()和locate()的双参数形式相同,只是参数的顺序相反
实例:
--用instr关键字进行模糊匹配,功能跟like一样,等同于:"like '%网%'"
SELECT * from app_info where INSTR(`appName`, '网');三、MySQL基于regexp、rlike的正则匹配查询(like查询比正则表达式查询略微快一点,但是正则表达式较灵活)
MySQL中的regexp和rlike关键字属于同义词,功能相同。
语法:
属性名 regexp '匹配方式'regexp不支持通配符,支持正则匹配规则,是一种更细粒度且优雅的匹配方式。
| 选项 | 说明 | 例子 | 匹配值实例 |
| ^ | 匹配文本的开始字符 | '^b'匹配以字母b开头的字符串 | book、big、bike |
| $ | 匹配文本的结束字符 | 'st$'匹配以字母st结尾的字符串 | test、resist |
| . | 匹配任何单个字符 | 'b.t'匹配任何b和t之间有一个字符 | bit、bat、but |
| * | 匹配前面的字符0次或多次 | ‘f*n’ 匹配字符 n 前面有任意个字符 f | fn、fan、faan、abcn |
| + | 匹配前面的字符1次或多次 | ‘ba+’ 匹配以 b 开头,后面至少紧跟一个 a | ba、bay、bare、battle |
| ? | 匹配前面的字符0次或1次 | 'sa?'匹配0个或1个a字符 | sa、s |
| 字符串 | 匹配包含指定字符的文本 | ‘fa’ 匹配包含‘fa’的文本 | fan、afa、faad |
| [字符集合] | 匹配字符集合中的任何一个字符 | ‘[xz]’ 匹配 x 或者 z | dizzy、zebra、x-ray、extra |
| [^] | 匹配不在括号中的任何字符 | ‘[^abc]’ 匹配任何不包含 a、b 或 c 的字符串 | desk、fox、f8ke |
| 字符串{n,} | 匹配前面的字符串至少n次 | ‘b{2}’ 匹配 2 个或更多的 b | bbb、bbbb、bbbbbbb |
| 字符串{n,m} | 匹配前面的字符串至少n次,至多m次 | ‘b{2,4}’ 匹配最少 2 个,最多 4 个 b | bbb、bbbb |
实例:
SELECT * from app_info where appName REGEXP '网';
-- 等同于
SELECT * from app_info where appName like '%网%';3.1.regexp中的OR:|
功能:可以搜索多个字符串之一,相当于or
--匹配包含"中国"或"互联网"或"大学"的数据,支持叠加多个
SELECT * from app_info where appName REGEXP '中国|互联网|大学';--匹配同时命中"中国"、"网"的数据可以用".+"连接,代表中国xxxx网,中间允许有任意个字符,顺序不能反。
SELECT * from app_info where appName REGEXP '中国.+网';3.2.regexp中的正则匹配:[]
功能:匹配[]符号中几个字符之一,支持解析正则表达式
--匹配包含英文字符的数据,默认不区分大小写情况下
SELECT * from app_info where appName REGEXP '[a-z]';-- 跟like一样,取反集加 "not REGEXP" 即可,下面不再赘述
SELECT * from app_info where appName not REGEXP '[a-z]';--匹配包含大写英文字符的数据,默认忽略大小写,需要加上"binary"关键字。如
SELECT * from app_info where appName REGEXP BINARY '[A-Z]';
注意:MySQL中正则表达式匹配(从版本3.23.4后)不区分大小写--匹配包含数字的数据
SELECT * from app_info where appName REGEXP '[0-9]';--匹配包含数字或英文的数据
SELECT * from app_info where appName REGEXP '[a-z0-9]';a-z、0-9都认定为一个单位,不要加多余符号
--查询以5、6、7其中一个为开头的数据
SELECT * from app_info where appName REGEXP '^[5|6|7]';--查询以5、6、7其中一个为结尾的数据
SELECT * from app_info where appName REGEXP '[5|6|7]$';--查询appname字节长度为10,任意内容的数据
SELECT * from app_info where appName REGEXP '^.{10}$';-- 查询appName字节长度为10,且都为英文的数据
SELECT * from app_info where appName REGEXP '^[a-z]{10}$' ;-- 查询appName字节长度为10,且都为大写英文的数据,加上BINARY即可
SELECT * from app_info where appName REGEXP BINARY '^[A-Z]{10}$';-- 查询version_name字节长度为6,且都为数字或"." 的数据
SELECT * from app_info where version_name REGEXP '^[0-9.]{6}$';-- 查询version_name字节长度为6,且都为数字或"." 的数据;要求首位为1
SELECT * from app_info where version_name REGEXP '^1[0-9.]{5}$' ;- 查询version_name字节长度为6,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4}7$' ;-- 查询version_name字节长度为6位以上,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,}7$' ;-- 查询version_name字节长度为 6 - 8 位,且都为数字或"." 的数据;要求首位为1,末位为7
SELECT * from app_info where version_name REGEXP '^1[0-9.]{4,6}7$' ;-- 首位字符不是中文的
SELECT * from app_info where appName REGEXP '^[ -~]';-- 首位字符是中文的
SELECT * from app_info where appName REGEXP '^[^ -~]';-- 查询不包含中文的数据
SELECT * from app_info where appName REGEXP '^([a-z]|[0-9]|[A-Z])+$';-- 以5或F开头的,且包含英文的数据
SELECT * from app_info where appName REGEXP BINARY '^[5F][a-zA-Z].';特殊符号的匹配,例如.,需要加\\(注意是两个斜杠),但是如果在[]中可以不加:
-- 匹配name中含有.的
select * from app_info where appName regexp '\\.';
-- 匹配name中含有.的
select * from app_info where appName regexp '[.]';3.3.字符类匹配(posix)
mysql中有一些特殊含义的符号,可以代表不同类型的匹配:
-- 匹配name中含有数字的
select * from app_info where appName regexp '[[:digit:]]';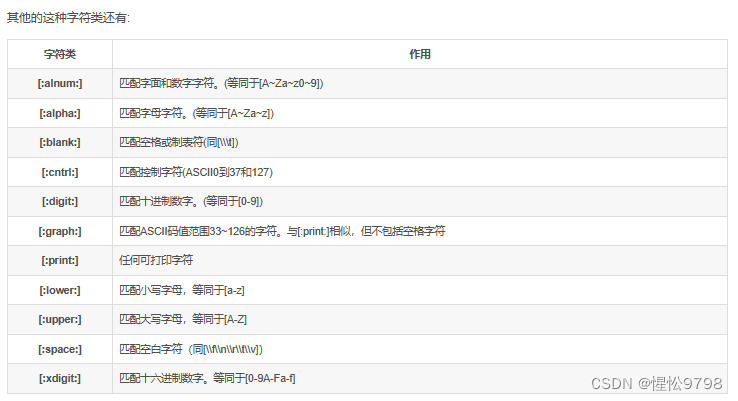
这种字符类需要主要的外层要加一层[]。
3.4.[:<:]和[:>:]
上面的字符类中有两个比较特殊的,这两个是关于位置的,[:<:]匹配词的开始,[:>:]匹配词的结束,它们和 ^、$ 不同。
后者是匹配整个整体的开头和结束,而前者是匹配一个单词的开始和结束。
-- 只能匹配整体以a开头的,例如abcd
select * from app_info where appName regexp '^a';-- 能匹配整体以a开头的,也能匹配中间的单词以a开头,如:dance after。
select * from app_info where appName regexp '[[:<:]]a';[[:<:]] 、 [[:>:]] 分别匹配一个单词开头和结尾的空的字符串,这个单词开头和结尾都不是包含在alnum中的字符也不能是下划线。
select "a word a" REGEXP "[[:<:]]word[[:>:]]"; -- 1(表示匹配)
select "a xword a" REGEXP "[[:<:]]word[[:>:]]"; -- 0(表示不匹配)
select "weeknights" REGEXP "^(wee|week)(knights|nights)$"; -- 1(表示匹配)