文章目录
- 1.free查看总体的内存占用
- 2./proc/$PID/status 查看某进程状态
linux开发最重要的两个参数,分别是内存以及CPU使用率,若内存出现严重不足,则在需要使用内存时,可能出现申请不到的情况,导致 OOM,Linux系统主动杀死占用内存比较高的进程。
1.free查看总体的内存占用


free中的信息,其实都来自/proc/meminfo。
可以用free -k 则显示数据的单位是KB,free -m 则看到的单位是MB
total:物理内存的总大小
计算方式:total = used + free + buff/cache
used:真正被使用内存的大小,其中包括shared共享内存大小
计算方式:used = total - free - buff/cache
free:未使用内存的大小
计算方式:free = total - buff/cache - used
shared:共享内存大小,包括mmap申请的共享内存,以及加载的动态链接库以及程序的代码段等。
这个值以及包含在used中
buff/cache:缓存和缓冲区的大小,主要目的是为了提升IO的性能,加快IO的速度,当系统内存不足时,会尝试从这边借用内存。Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
之所以buff/cache能加快IO性能,是因为实际场景中,从内存读取数据的效率远远大于从磁盘读取,如果频繁从磁盘读取数据,会影响CPU工作效率,所以Linux系统在内存中开辟缓存空间,把要用到的数据提前加载到内存中,提升CPU工作效率。
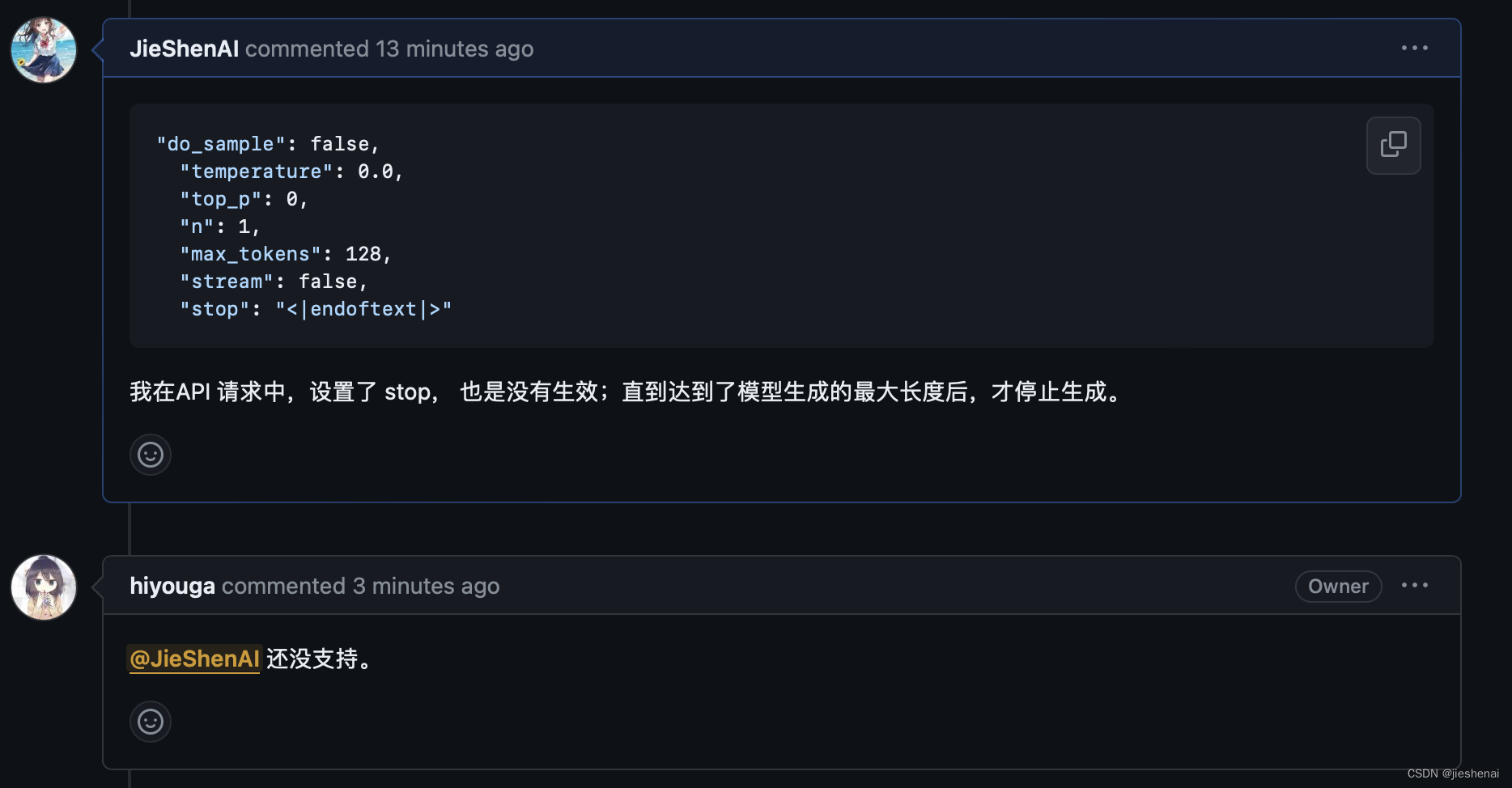
Linux系统读文件数据,首先判断数据是否在cache,如果在则从cache中读取,如果不在,则从磁盘中读取,并且次数会将读取的数据缓存到cache中,下次读取数据则会更快。
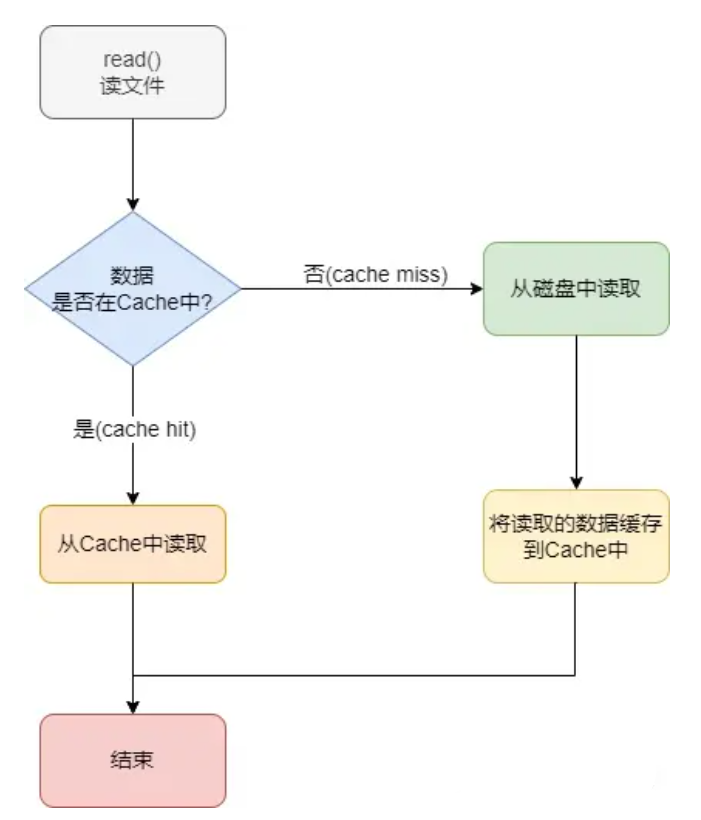
Linux系统写文件数据,首先是往cache中写入数据,此时将写入的cache页标记为脏页,也就是标记cache上还有数据没有同步到磁盘上,待内核在合适的时机将数据统一刷新到磁盘上,如果cache中的数据已经同步到磁盘上,我们就叫它干净页。
avaliable:剩余可使用的内存 ,理论上total - used就是剩下的内存,但实际上并不是所有剩余内存都可使用,所以 available <(total - used)即available < ( buff/cache + free),但比较接近这个值。
2./proc/$PID/status 查看某进程状态
当看到整体内存不足时,一般都需要去分析是哪个进程占用的内存比较多,并且确认该进程的内存是否一直在增长,如果是的话,则可能发生了内存泄漏。
xzx@ubuntu:~/share/project_ipc/hm3001/70mai/mike$ cat /proc/128622/status
Name: fwupd
Umask: 0022
State: S (sleeping)
Tgid: 128622
Ngid: 0
Pid: 128622
PPid: 1
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 256
Groups:
NStgid: 128622
NSpid: 128622
NSpgid: 128622
NSsid: 128622
VmPeak: 633144 kB
VmSize: 567608 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 24532 kB
VmRSS: 24532 kB
RssAnon: 4244 kB
RssFile: 20288 kB
RssShmem: 0 kB
VmData: 45180 kB
VmStk: 132 kB
VmExe: 332 kB
VmLib: 57656 kB
VmPTE: 540 kB
VmSwap: 0 kB
HugetlbPages: 0 kB
CoreDumping: 0
THP_enabled: 1
Threads: 5
SigQ: 0/23440
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000001000
SigCgt: 0000000180004000
CapInh: 0000000000000000
CapPrm: 0000003ffffeffff
CapEff: 0000003ffffeffff
CapBnd: 0000003ffffeffff
CapAmb: 0000000000000000
NoNewPrivs: 0
Seccomp: 2
Speculation_Store_Bypass: thread force mitigated
Cpus_allowed: ffffffff,ffffffff,ffffffff,ffffffff
Cpus_allowed_list: 0-127
Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001
Mems_allowed_list: 0
voluntary_ctxt_switches: 66
nonvoluntary_ctxt_switches: 7
Pid:当前进程id
PPid:当前进程的父进程ID
VmPeak:当前进程运行过程中占用内存的峰值
VmSize:进程当前使用的虚拟内存的大小,包括了进程使用的所有虚拟内存区域的大小,包括未分配的、已分配但尚未使用的、已使用的以及共享的内存区域等。虚拟内存大小包含了进程可访问的所有虚拟地址空间,但不一定都会被实际占用。
VmLck:当前进程已经锁住的物理内存的大小.锁住的物理内存不能交换到硬盘
VmHWM:进程所使用的物理内存的峰值
VmRSS:进程当前使用物理内存的大小
VmData: 进程占用的数据段大小
VmStk:进程占用的栈大小
VmExe:进程占用的代码段大小
VmLib:进程所加载的动态库所占用的内存大小
VmPTE:进程占用的页表大小
VmSwap:进程所使用的交换区的大小
一般是看VmRSS的增长情况来确认是否发生了内存泄漏,如果VmRss即真实物理内存大小不断在增长,则代表内存发生了泄漏。而VmHWM代表物理占用内存峰值,能看到该进程对内存的需求情况,如果峰值很高,代表这个进程存在内存需求比较多的情况。