1. 引言
c++的内存模型主要解决的问题是多线程的问题。怎么理解多线程呢?单核时候,只有1个CPU内核处理多线程,各线程之间随着时间的推进,会不断的切换,如下图形便于理解。
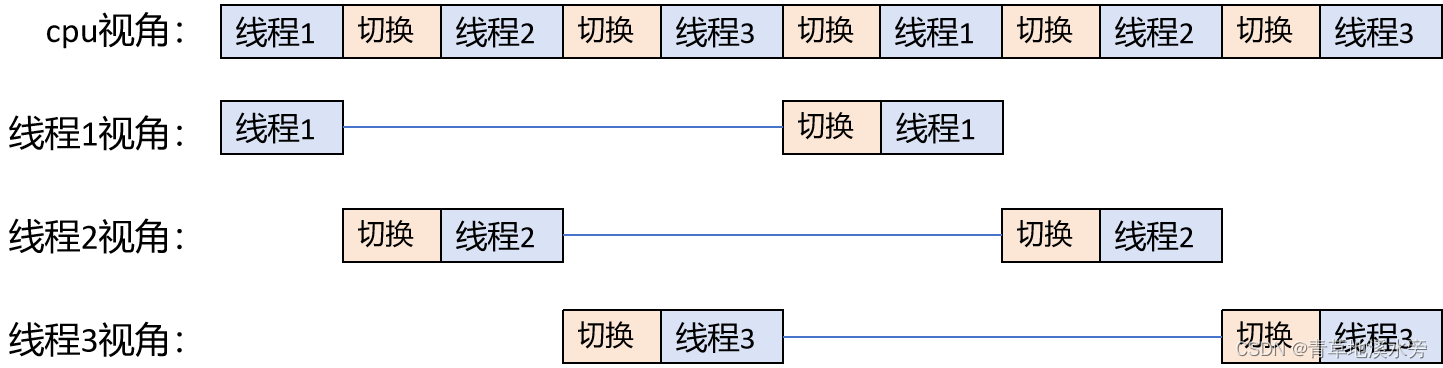
实际上线程间的切换是非常快的,所以从人感受的视角,感觉到3个进程独占cpu在执行各自的任务。如果每个线程的变量是独立的,那么多个线程间的运行结果则不会出现问题。但是,如果有一个变量同时被多个线程更改,那么就可能出现问题。
实际上,高级语言的一行代码,编译成机器码,则需要多个机器码指令。当线程切换时,CPU会保存上个线程的一套通用寄存器和状态寄存器,之后切换到下一个线程的通用寄存器和状态寄存器。打个比方,a的初始值5,线程1执行到以下高级语言代码时,切换下一线程2,此时通用寄存器会保存现场,a变量在线程1中通用寄存器值为5。
a += 10; (线程1中更改变量a))
恰巧线程2会执行以下代码也修改了变量a。
a + =20; (线程2中更改变量a)
线程2完整的执行了以上代码,此时a的值为25。但是再次切换到线程1的时候,恢复线程1的现场,保存变量a的通用寄存器并不知道a的值已经被改变成25了,它仍然以为变量a的值为5,经过运行后,把变量的值变成了15。然而,编写代码的人的预期值可能是35,因为他认为变量a的初始值为5,线程1执行+10指令,线程2执行+20指令,所以他认为a的值为35。
出现以上不符合预期的结果,总结如下,
多个线程同时修改同一个变量,且在更改变量的时刻,发生了线程切换的事情,cpu内部的通用寄存器保存了现场,而再次返回现场时,这个共享变量已经被别的线程修改过了,不再是原来的值了,但是,当前线程并不知道。
2. CPU和编译器的优化
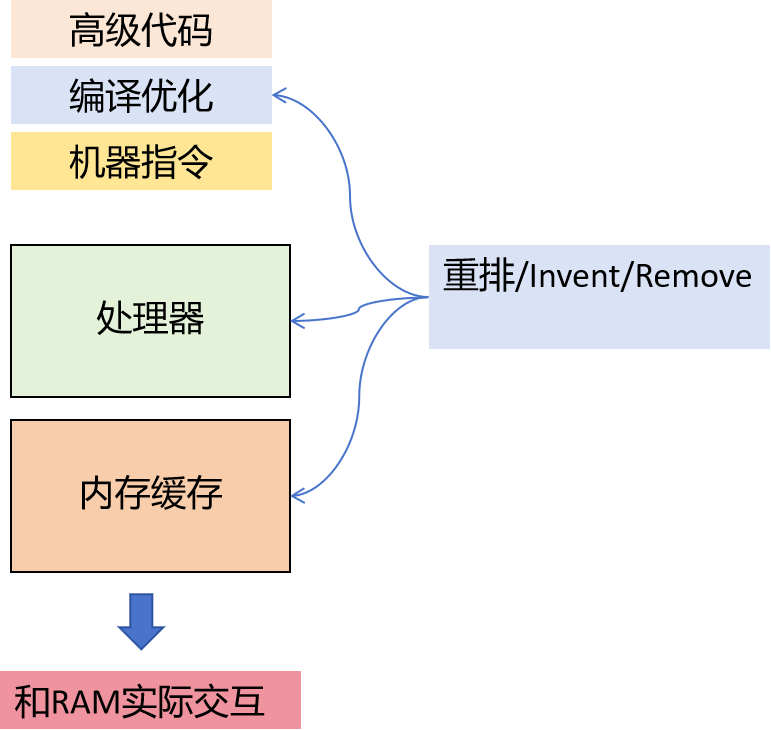
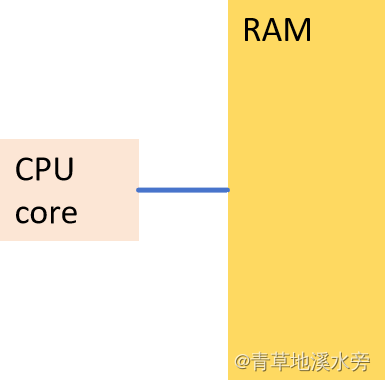
然而,高级语言的代码逻辑和实际执行的机器码指令情况并不相同,但是产生的效果是一样。先从CPU架构的硬件差异性说起。一般而言,单核的CPU的理想原型如下:
多核的CPU的理想原型如下
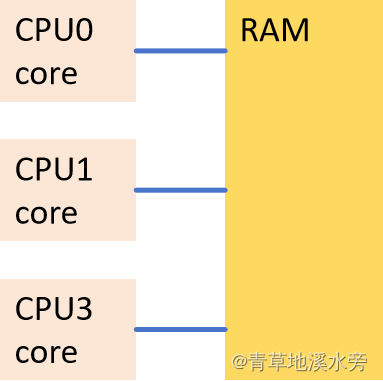
实际上,CPU核中大面积的集成电路是内核Cache。 在CPU Core和RAM之间,还有共三层的Cache结构(L1/L2/L3),此外还有Store Buffer (SB),且SB和L1 是每个Core独享,而L2是两个Core共享,L3是所有Core共享,模型总结如下

引入Cache也是有原因了,CPU执行指令速度非常快,只占用几个指令周期,但是从RAM加载机器指令的几百个指令周期。如果CPU直接从RAM中加载机器指令的话,会严重的拖慢CPU的效率,因为CPU等待指令加载。
引入了Cache,解决了CPU等待的问题,但却产生了很多新的问题,例如Cache的一致性,Cache的缺失,Cache的乒乓效应等等,为了解决这些问题,各CPU平台( X86 / IA64 / ARM / Power…)都有自己的解决方案,软件层面(编译器)也会有对应的优化。这导致了CPU执行的程序,并不是你写的那个版本,只是从结果上看不出差别而已。如果你曾经单步调试过一个release版本的程序,你会发现运行过程很怪异,居然没有沿着你的代码顺序执行。因为,要是严格按照你的代码顺序执行,编译器和CPU都会抱怨,说执行效率很低速度很慢。
要了解内存模型,还是要先谈谈一些重要的优化,包括编译器和CPU/Cache方面。优化主要包括
- Reorder
- Invent
- Remove