1. 常见的锁策略
所谓"策略",也可以理解为做法."锁策略"就是用来描述一把锁面对加锁/解锁时的做法.
1.1 乐观锁 vs 悲观锁
要区分一把锁是乐观锁还是悲观锁,就要预测当前这把锁冲突的概率高不高.
如果冲突概率高,后续要做的工作往往会更多,加锁的开销就大,这就是悲观锁.
如果冲突概率不高,后续要做的工作往往就会少,加锁的开销就少,这就是乐观锁.
那么java中的synchronized是属于哪种锁呢? 答:既是乐观锁,又是悲观锁.
这是因为synchronized支持自适应,能够自己统计出当前锁冲突的次数,进行判定当前锁冲突概率高不高.如果冲突概率高,就按照悲观锁的方式执行;如果冲突概率低,就按照乐观锁的方式执行.
1.2 重量级锁 vs 轻量级锁
区分一把锁是重量级锁还是轻量级锁看的是:对这把锁加锁过程中做的事情多不多.
如果做的事情多,就是重量级锁;如果做的事情少,就是轻量级锁.
一般来说,悲观锁往往是重量级锁;乐观锁往往是轻量级锁.也许以后我们再使用时会混着用这两对概念,但是我们要理解这两对概念的出发点时不同的.
1.3 自旋锁 vs 挂起等待锁
自旋锁,是轻量级锁的一种典型的实现方式.
内部的过程,我们这里用伪代码演示一下:
void lock() {
while(true) {
if(锁被占用) {
continue;
}
获取到锁
break;
}
}这个过程中,cpu在空转忙等.消耗了更多的cpu资源.但是,一旦锁被释放,就可以第一时间拿到锁,拿到锁的速度更快.
挂起等待锁,是重量级锁一种典型的实现方式.
所谓"挂起等待',就是在发生锁冲突的时候,进入阻塞等待状态.直到这把锁被释放,系统才能唤醒这个线程去获取这把锁.在这个过程中,由于这个线程说明时候被唤醒是不确定的,因此会花费更长的时间去获取到这把锁,但是cpu不会进行空转,节省了cpu资源.
synchronized的轻量级锁部分,通过自旋锁实现;重量级锁部分,通过挂起等待锁实现.
1.4 可重入锁 vs 不可重入锁
所谓"可重入"和"不可重入"就是同一个线程对这把锁加锁两次,看会不会发生死锁.
不会死锁的就是"可重入锁",会死锁的就是"不可重入锁".
synchronized就是一种可重入锁.这一点我们在之前的博客中已经介绍过了,这里就不过多介绍.
1.5 公平锁 vs 非公平锁
对于公平锁,讲究的是"先来后到",哪个线程等待这把锁的时间最长,哪个线程先获取到这把锁.
对于非公平锁,讲究的是"各凭本事",当这把锁被释放后,哪个线程竞争力强,就哪个线程先获取到这把锁.
synchronized是非公平锁,当这把锁被释放时,多个线程获取到这把锁的概率是被均分的.如果要实现公平锁,需要设置一个线程队列,这样才能排出个"先来后到".
1.6 互斥锁 vs 读写锁
synchronized就是普通的互斥锁.操作:加锁/解锁.
读写锁时一种更特殊的锁.操作:加读锁/加写锁/解锁.
java中的读写锁主要可以由三句话概括:
1. 读锁和读锁之间不互斥
2. 读锁和写锁之间互斥
3. 写锁和写锁之间互斥
主要突出的是,读操作可以同时进行,共享数据.有利于降低锁冲突率,提高并发能力.因为,在日常某些场景中,写操作进行得少,而读操作会进行许多次,这是使用读写锁的优势便能够体现出来.
2. 锁优化
我们刚才提到了synchronized既是悲观锁,也是乐观锁;既是轻量级锁,也是重量级锁;是可重入锁;是非公平锁;是互斥锁.我们这里来了解synchronized的优化过程.
2.1 锁升级
对于synchronized,会自适应地进行"锁升级",锁升级的过程如下:
未加锁状态->偏向锁->轻量级锁->重量级锁
我们来模拟一下这个过程:
原来线程是未加锁状态,执行synchronized语句升级为偏向锁;如果,遭遇了锁冲突,从偏向锁升级为轻量级锁;如果锁冲突进一步加剧,从轻量级锁升级为重量级锁.
这里我们要对偏向锁这个概念,进行一定的介绍:
这里的偏向锁,就是:加锁了吗?答:如加.实际上就是对这把锁进行一个标记,如果在运行过程中,没有别的线程来获取这把锁,就不对这个线程加锁了;如果有别的线程来获取这把锁,再真正对这个线程加锁(轻量级锁).
锁升级,避免了过度消耗系统的资源.
2.2 锁消除
这是一种编译器优化策略.当我们在代码中使用了synchronized,JVM就会进行判断,这个地方到底需不需要加锁.如果这里不需要加锁,编译器就会自动地把这里的加锁操作给优化掉.
这里最典型的情况就是,在只有一个线程的代码中使用synchronized,这里的加锁操作就会被优化掉.
但是,编译器优化前后要保证代码的逻辑是等价的,因此这里的优化起到的作用是十分有限的.
2.3 锁粗化
锁的粒度:加锁的范围内包含的代码多少.
包含的代码多,锁的粒度就粗;包含的代码少,锁的粒度就细.
在有些逻辑中,需要频繁的加锁和解锁,编译器就会把多个细粒度的锁合并成一把粗粒度的锁,这样在保证等价逻辑的前提下,减少了系统资源的消耗.
3. CAS
CAS的全称是compare and swap,意为比较和交换.这是cpu的一条指令,体现了原子性.
我们可以把CAS的过程想象成一个方法,可以结合下面的伪代码分析:
boolean cas(address,reg1,reg2) {
if(*address == reg1) {
把address内存地址的值和reg2寄存器的值进行交换.
return true;
}
return false;
}address表示获取内存地址,reg指的是cpu的寄存器.这里虽然说的是交换,实际上更多的是用来赋值,而且更关心内存中交换后的值,而不是寄存器里交换后的值.
操作系统内核可以通过cpu的这条指令提供CAS的API;JVM又对系统的CAS API进一步封装,在java代码中也就可以使用CAS操作了.典型的就是"原子类".
原子类的使用
在java.util.concurrent.atomic这个包下,就封装好了许多原子类.
如下图:
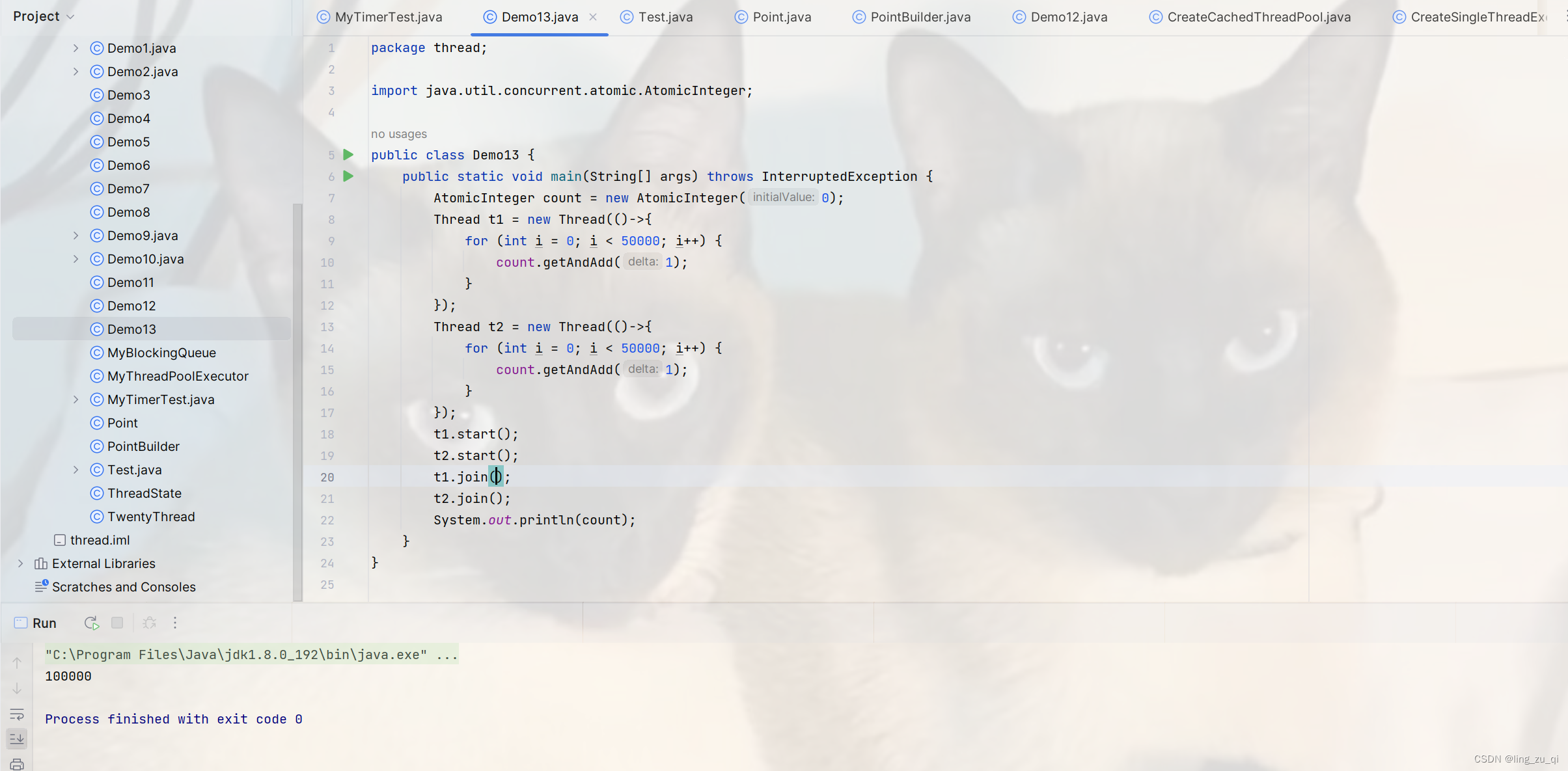
比如我们之前提过的案例:使用两个线程交替对同一个变量进行自增.我们分析过,如果不加锁去实现这个代码,会引发线程安全问题.现在我们使用原子类来操作一下:
public static void main(String[] args) throws InterruptedException {
AtomicInteger count = new AtomicInteger(0);
Thread t1 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndAdd(1);
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndAdd(1);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
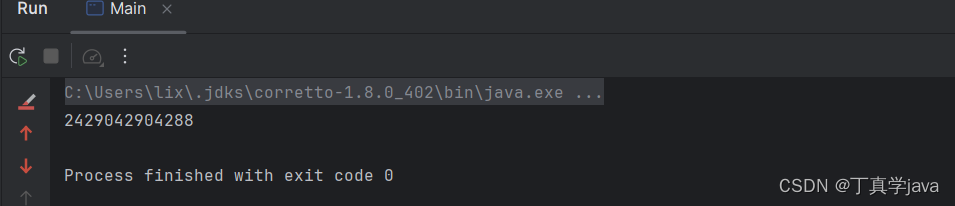
System.out.println(count);
}效果如下:
这一套操作被称为"无锁编程",虽然在这种情况下运行效率高了,但是在某些场景下,CAS并不适用.
ABA问题
当前有两个线程并发执行修改变量num的操作,num的初始值为A.
线程t1想要把num的值修改成Z,t1就先读取到num的值存储到oldNum中,然后使用CAS判断,如果当前num的值为A就把他修改成Z.
但是在t1读取到num的值到判断是否要修改的过程中.线程t2进行了修改操作,它先把A改成了B,再把B改成了A.这样看上去好像就没有修改.但是 没有修改 != 修改前后一样.
这样等到线程t1进行判断时,发现num的值仍然是A,会进行修改.但是这与t1操作原先的期望(num的值一直为A就修改为Z)不同,就出现了bug.这就是CAS容易引起bug的"ABA问题".
时间线:
t1获取到num的值A->t2修改num的值为B->t2修改num的值为A->t1判断num的值为A,修改为Z
解决方法:
引入一个只能增加的版本号变量,我们对其中的值每进行一次修改,就让版本号加一.在判断时不仅仅判断值是否相等,同时要判断版本号是否一致.我们引入版本号再来分析一次上面的过程.
假设初始的版本号为1,t1获取到num的值为A,版本号为1;t2修改num的值为B,版本号变为2;t2修改num的值为A,版本号变为3;t1进行判断,值为A,匹配成功,版本号为3 != 1,匹配失败,不进行修改.