一、准备
系统:MacOS 14.3.1
ElasticSearch:8.13.2
Kibana:8.13.2
BGE是一个常见的文本转向量的模型,在很多大模型RAG应用中常常能见到,但是ElasticSearch中默认没有。BGE模型有很多版本,本次采用的是bge-large-zh-v1.5。下载地址:
HuggingFace:https://huggingface.co/BAAI/bge-large-zh-v1.5
Modelscope:魔搭社区
将bge-large-zh-v1.5导入ElasticSearch详见:Eland上传bge-large-zh-v1.5向量化模型到ElasticSearch中-CSDN博客
二、向量化简单测试
启动ES和Kibana
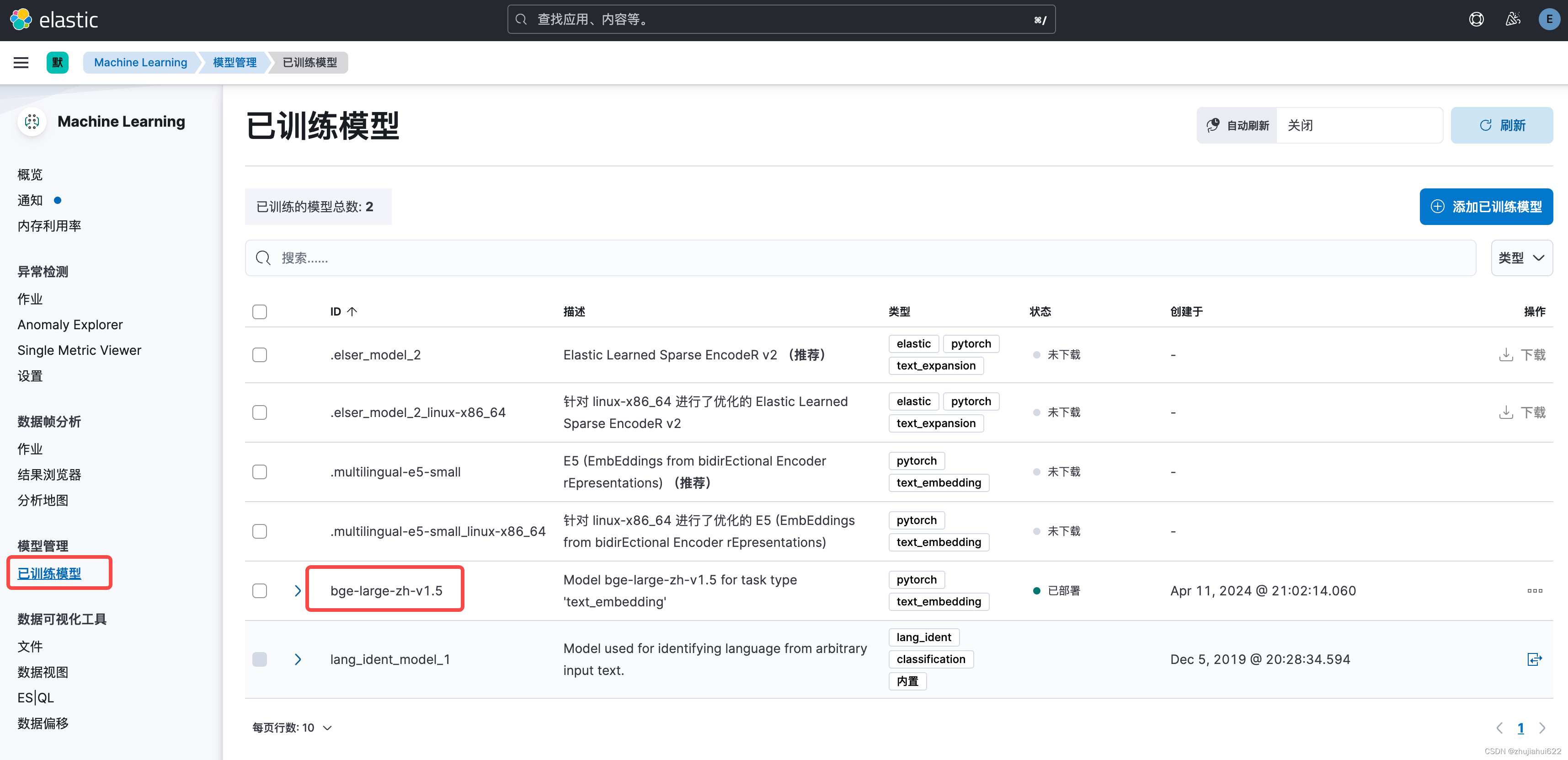
在Kibana的【机器学习】->【已训练模型】找到模型bge-large-zh-v1.5:
打开【开发工具】,简单测试:
POST _ml/trained_models/bge-large-zh-v1.5/_infer
{
"docs": [
{
"text_field": "我的第一个向量化模型"
}
]
}结果:
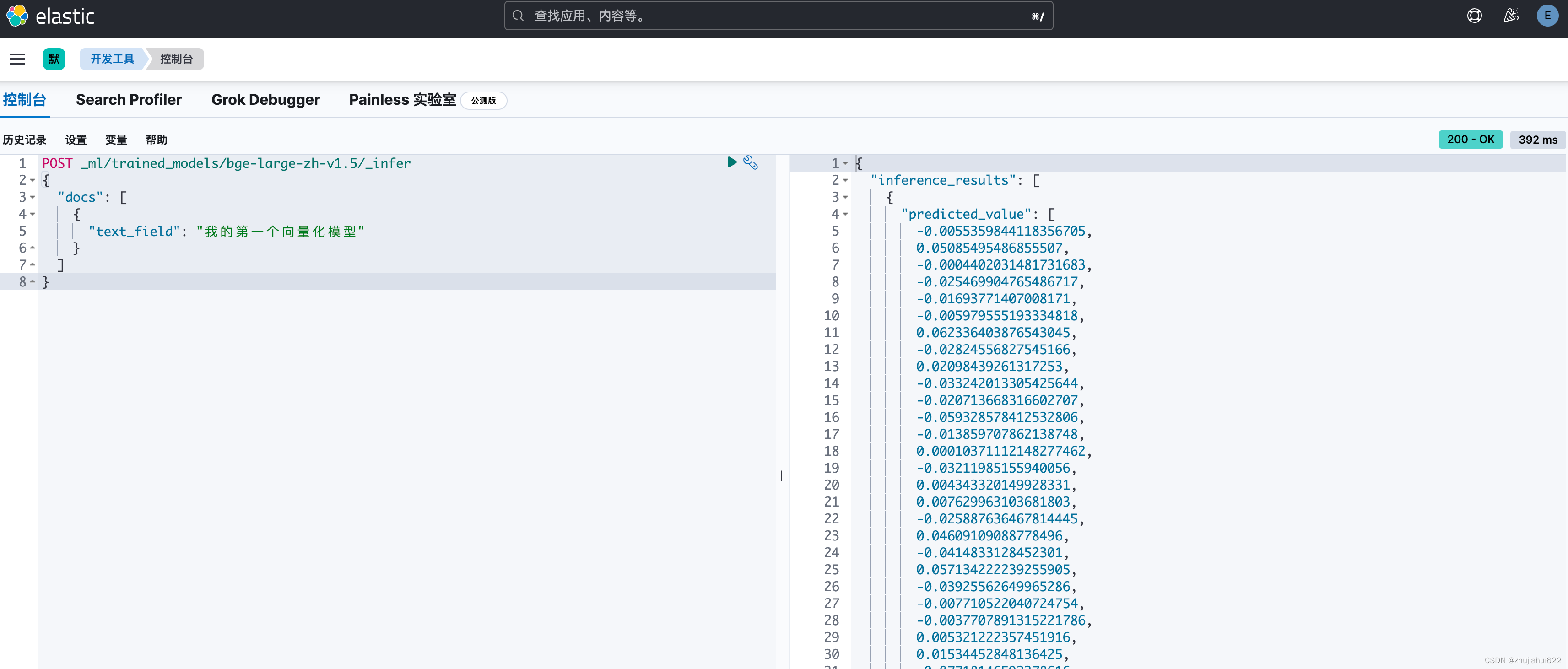
拉到最下面,显示向量的维数是1024,符合预期。
三、向量索引构建
我们直接基于ElasticSearch以及bge-large-zh-v1.5模型即时生成向量,因此核心主要分三步:
1. 创建原始文本索引
2. 创建原始文本索引对应的向量索引
3. 创建向量化的Pipeline并应用
创建原始文本索引
首先创建一个用于示例的原始文本类型索引article:
PUT /article
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"brief": {
"type": "text"
},
"author": {
"type": "keyword"
},
"content": {
"type": "text"
},
"readNumber": {
"type": "integer"
}
}
}
}写入3条测试数据
POST /article/_doc/001
{
"title": "浙江丽水:住房公积金贷款最高限额拟提至100万元",
"brief": "【浙江丽水:住房公积金贷款最高限额拟提至100万元】财联社3月21日电,浙江省丽水市住房公积金管理中心就《关于进一步完善住房公积金政策的通知(征求意见稿)》公开征求意见。",
"author": "黄宁",
"content": "【浙江丽水:住房公积金贷款最高限额拟提至100万元】财联社3月21日电,浙江省丽水市住房公积金管理中心就《关于进一步完善住房公积金政策的通知(征求意见稿)》公开征求意见,职工首次申请住房公积金贷款购买首套自住住房的,双缴存职工最高限额由80万元上调为100万元;单缴存职工最高限额由40万元上调为60万元。职工二次申请住房公积金贷款或购买第二套自住住房的,双缴存职工最高限额由60万元上调为80万元;单缴存职工最高限额由30万元上调为50万元。同一对夫妻符合国家政策生育二孩、三孩的职工家庭购买自住住房申请住房公积金贷款的,住房公积金贷款最高限额上浮20%。同一对夫妻符合国家政策生育二孩、三孩的职工家庭市场租赁自住住房的,提取限额上浮50%。在个人住房公积金贷款最高限额内,贷款申请人实际可贷额度由不超过贷款申请人夫妻双方近12月(含申请贷款当月)住房公积金账户月均余额的10倍调整为20倍。支持新市民、青年人贷款需求,全市住房公积金贷款保底额度调整为每户30万元。",
"readNumber": "188"
}POST /article/_doc/002
{
"title": "今年新疆两口岸通行中欧(中亚)班列已突破4000列",
"brief": "昨天(9日),一列满载汽车、机电产品、服装的中欧班列在办理完霍尔果斯海关放行手续后从霍尔果斯口岸出境,开往波兰马拉舍维奇。今年新疆霍尔果斯和阿拉山口口岸通行的中欧(中亚)班列已突破4000列。",
"author": "央视新闻客户端",
"content": """今年霍尔果斯铁路口岸通行中欧(中亚)班列数量达2031列,阿拉山口铁路口岸通行中欧(中亚)班列数量达2014列,双口岸中欧班列通行数量占全国的四成以上,越来越多的日用百货、机电设备、电子产品、农副产品等“中国制造”选择从新疆铁路口岸走向中亚、欧洲市场。
霍尔果斯站安全生产指挥中心调度员 杨利业:今年一季度,共计1.2万辆商品车搭载中欧班列出口到哈萨克斯坦、乌兹别克斯坦等国家,助力‘新三样’走俏海外。
霍尔果斯海关监管三科副科长 赵远凤:现在每天经霍尔果斯口岸通行的班列保持在20列以上。""",
"readNumber": "208"
}POST /article/_doc/003
{
"title": "新疆巴州逾300万亩棉花机械化种植助力棉农节本增效",
"brief": "2024年,新疆巴州棉花的种植面积预计达300万亩以上,播种时间将从4月初持续至5月初。",
"author": "央视新闻客户端",
"content": """中新网乌鲁木齐4月9日电 (刘雨珊 申凯龙 康兴平)进入四月,新疆巴州逾300万亩棉花正式进入春播阶段,田间地头处处都是一片热火朝天的春播景象。
在新疆巴州轮台县群巴克镇迪那尔村的高标准农田里,两台装有北斗卫星定位导航系统的大型棉花播种机正缓缓前行。(吐尔逊·吾斯曼拍 摄)
4月9日,在新疆巴州轮台县群巴克镇迪那尔村的高标准农田里,两台装有北斗卫星定位导航系统的大型棉花播种机正缓缓前行,农民在进行棉花播种时借助北斗导航系统实现无人驾驶作业,可一次性完成铺膜、铺滴灌带、播种、覆土等工作,且播行端直、耕作精准,作业率高,也方便棉花成熟后机械化采收。""",
"readNumber": "308"
}创建向量索引
再创建一个新的包含向量的索引article_embeddings(相比于article新增text_embedding字段):
PUT /article_embeddings
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"brief": {
"type": "text"
},
"author": {
"type": "keyword"
},
"content": {
"type": "text"
},
"readNumber": {
"type": "integer"
},
"text_embedding": {
"properties": {
"model_id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"predicted_value": {
"type": "dense_vector",
"dims": 1024,
"index": true,
"similarity": "cosine"
}
}
}
}
}
}其中text_embedding.predicted_value为文本转向量后的向量字段。dims指定向量的维数,必须与BGE模型中的保持一致。
创建向量化Pipeline
创建文本->向量的Pipeline,对article索引中的title标题字段进行向量化:
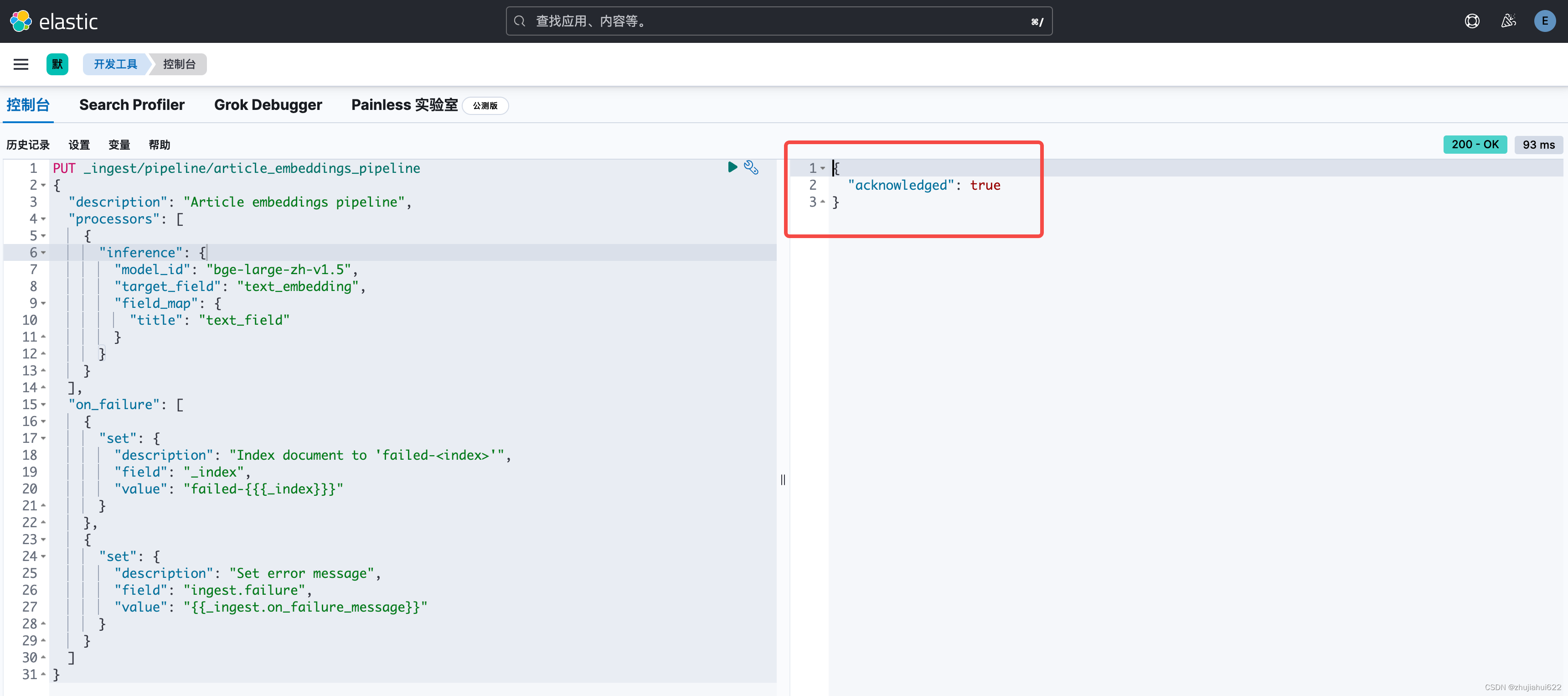
PUT _ingest/pipeline/article_embeddings_pipeline
{
"description": "Article embeddings pipeline",
"processors": [
{
"inference": {
"model_id": "bge-large-zh-v1.5",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
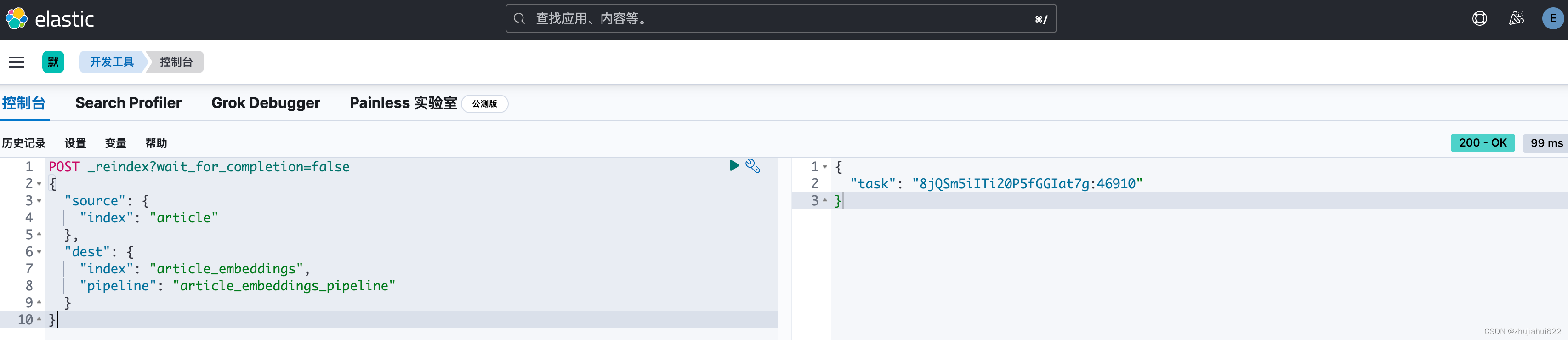
创建后对索引article执行article_embeddings_pipeline,将向量化后的数据放到索引article_embeddings上:
POST _reindex?wait_for_completion=false
{
"source": {
"index": "article"
},
"dest": {
"index": "article_embeddings",
"pipeline": "article_embeddings_pipeline"
}
}
成功后查看article_embeddings的数据,已经成功加上了向量字段:
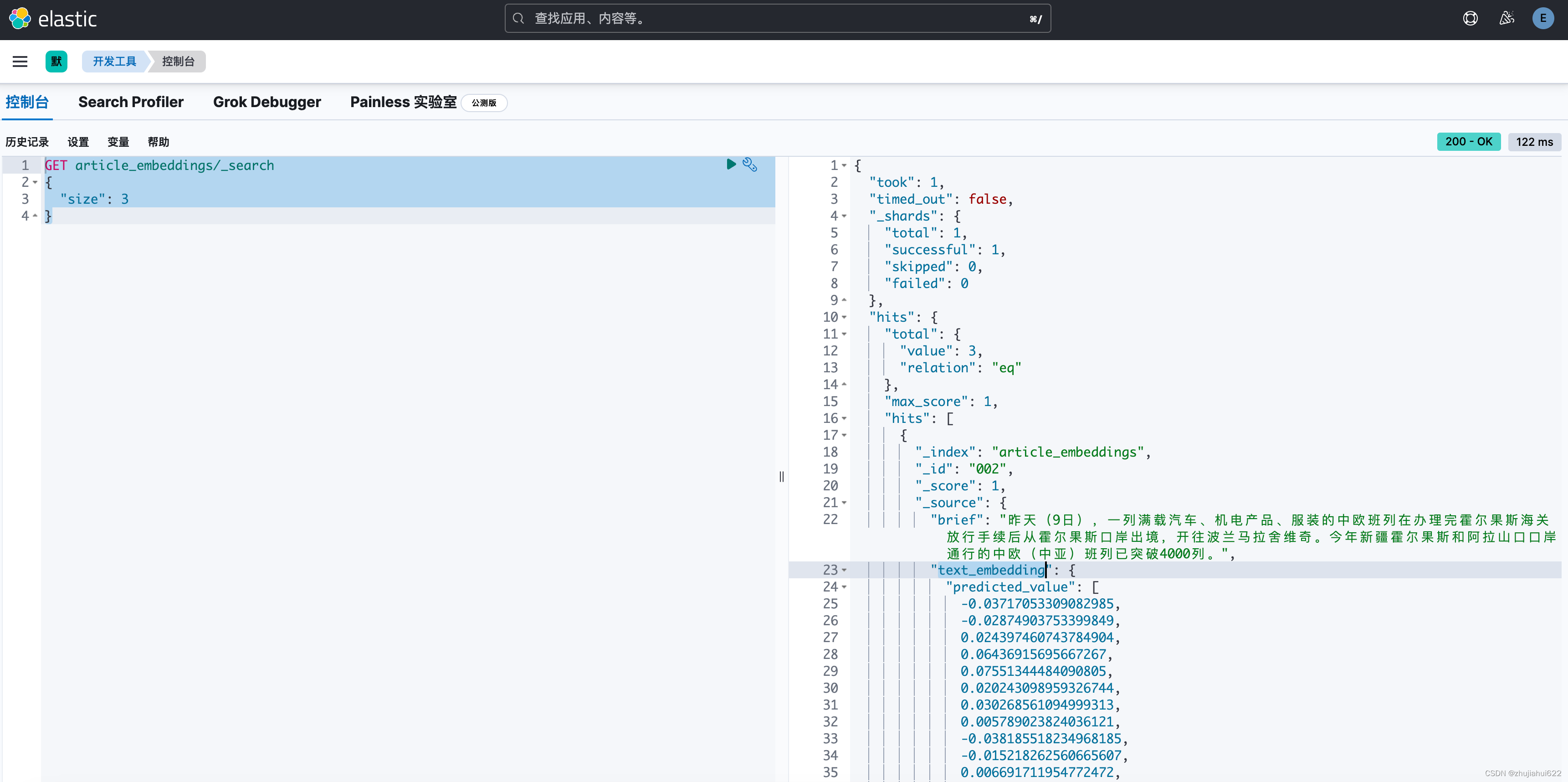
四、向量检索
假设要对用户query“中欧班列”进行向量化检索,先使用如下命令获得其BGE向量:
POST _ml/trained_models/bge-large-zh-v1.5/_infer
{
"docs": [
{
"text_field": "中欧班列"
}
]
}结果如下:
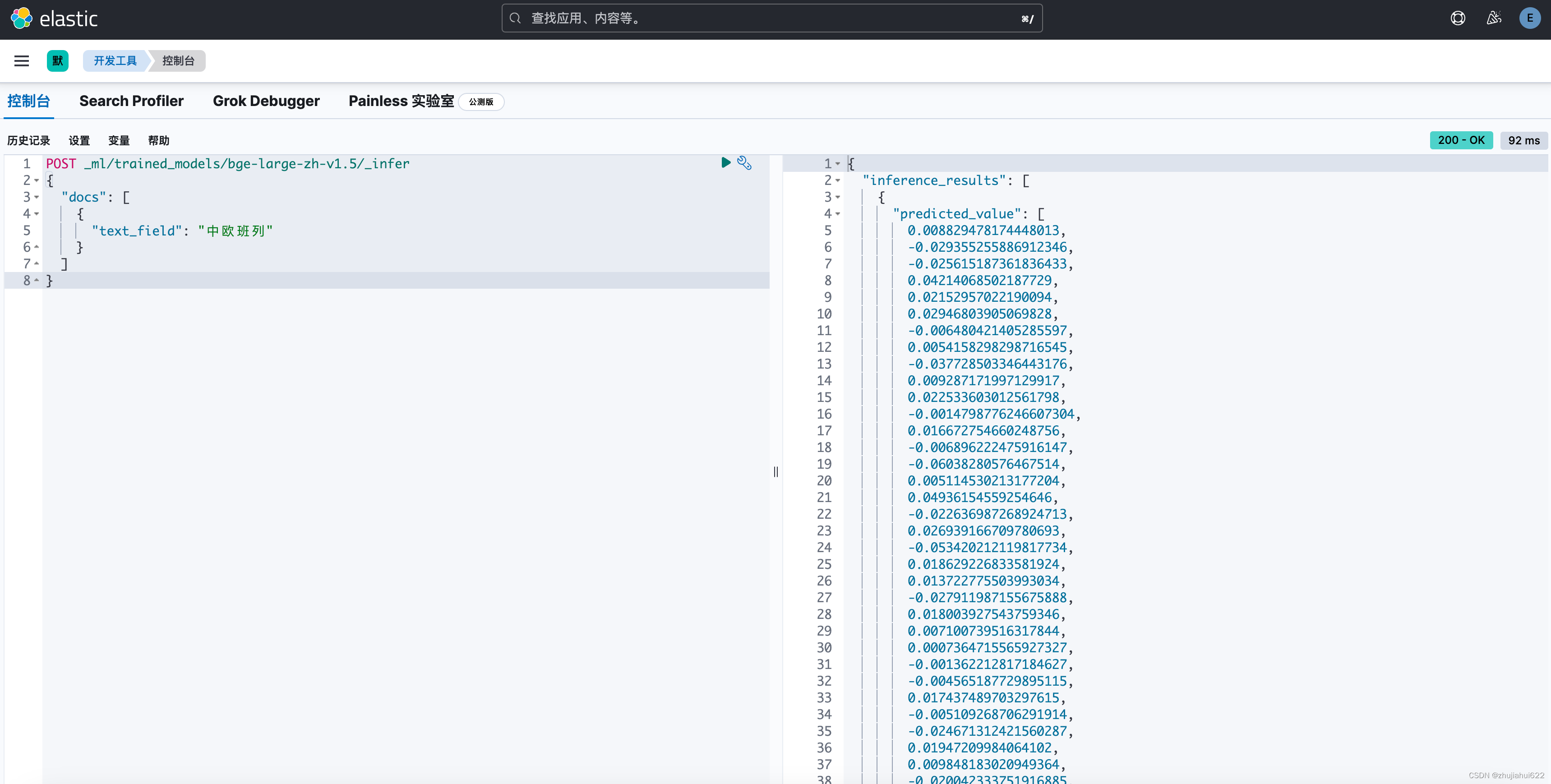
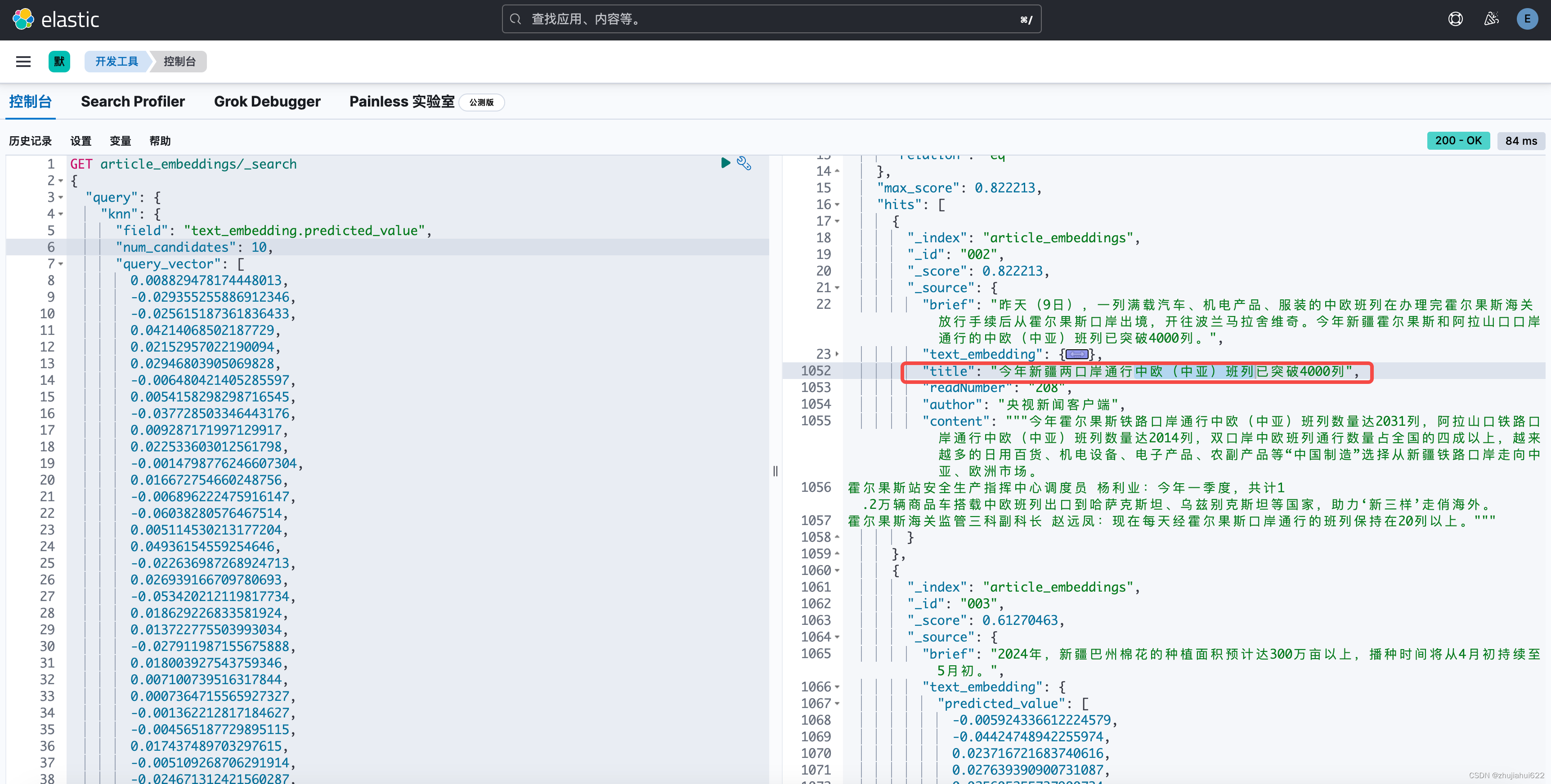
把生成的向量作为查询的一部分,再利用ElasticSearch中的KNN向量相似度检索来搜索相似标题的文本:
GET article_embeddings/_search
{
"query": {
"knn": {
"field": "text_embedding.predicted_value",
"num_candidates": 10,
"query_vector": [
0.008829478174448013,
-0.029355255886912346,
-0.025615187361836433,
此处省略
]
}
}
}
其中text_embedding.predicted_value是向量的字段,num_candidates是返回的数目
结果符合预期:
参考:Elasticsearch:介绍 kNN query,这是进行 kNN 搜索的专家方法_elasticsearch knnquery-CSDN博客
其他
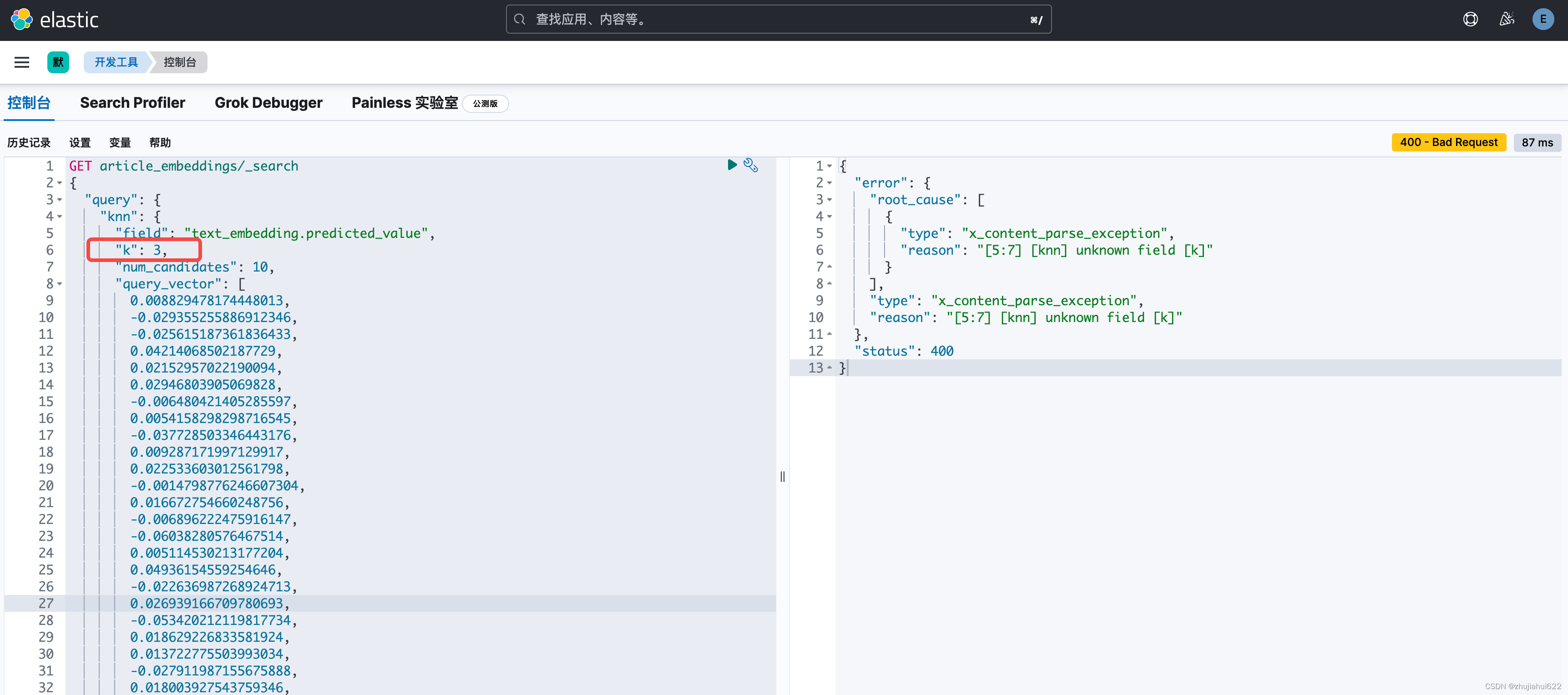
注意:目前高版本已经不支持_knn_search了:

其他问题:
报错:
{
"error": {
"root_cause": [
{
"type": "x_content_parse_exception",
"reason": "[5:7] [knn] unknown field [k]"
}
],
"type": "x_content_parse_exception",
"reason": "[5:7] [knn] unknown field [k]"
},
"status": 400
}
原因:目前高版本已经不支持设置"k"了,无需设置"k"。








![[BT]BUUCTF刷题第16天(4.12)](https://img-blog.csdnimg.cn/direct/6c8d074bde144ebd8c886a8d62e9cd64.png)