目录
引言:LLMs在强化学习中的探索能力探究
研究背景:LLMs的在情境中学习能力及其重要性
实验设计:多臂老虎机环境中的LLMs探索行为
实验结果概览:LLMs在探索任务中的普遍失败
成功案例分析:Gpt-4在特定配置下的探索成功
探索失败的原因分析
相关工作回顾:LLMs能力研究的相关文献
讨论与未来工作方向
总结
引言:LLMs在强化学习中的探索能力探究
在强化学习和决策制定的核心能力中,探索(exploration)扮演着至关重要的角色。探索能力指的是智能体为了评估不同选择并减少不确定性而有意识地收集信息的能力。近年来,大型语言模型(Large Language Models,简称LLMs)在多种任务中展现出了令人瞩目的性能,特别是在无需训练干预的情况下,通过上下文学习(in-context learning)来解决问题。然而,LLMs在没有额外训练干预的情况下是否能够展现出探索行为,尤其是在简单的多臂老虎机(multi-armed bandit,简称MAB)环境中,这一问题仍然不甚明了。
本研究通过将LLMs部署为代理,放置在MAB环境中,通过LLM提示(prompt)完全指定环境描述和交互历史,来探究LLMs的探索能力。实验结果显示,只有在使用了特定提示设计的情况下,LLMs才能表现出满意的探索行为。这一发现提示我们,为了在更复杂的环境中获得理想的行为,可能需要非平凡的算法干预,例如微调或数据集策划。本文的研究为理解LLMs作为决策制定代理的潜力提供了新的视角,并指出了未来研究的方向。
论文标题:Can large language models explore in-context?
机构:Microsoft Research, Carnegie Mellon University
论文链接:https://arxiv.org/pdf/2403.15371.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
研究背景:LLMs的在情境中学习能力及其重要性
在人工智能领域,大型语言模型(LLMs)的出现标志着一个新的时代。这些模型,如GPT-3.5、GPT-4和Llama2,已经展示了在没有参数更新的情况下,通过简单地在模型提示(prompt)中指定问题描述和相关数据,即所谓的“情境中学习”(in-context learning),来解决问题的能力。这种能力的出现并非由于模型被显式地训练来执行这些任务,而是因为这些算法能够从大规模训练语料库中提取出来,并在大规模应用时显现出来。
情境中学习的发现自GPT-3模型以来,已经成为研究的热点。尽管对于情境中的监督学习(ICSL)的理论进展仍处于初级阶段,但我们对如何在实践中使用ICSL的理解正在迅速形成。然而,除了监督学习之外,许多应用要求使用机器学习模型进行下游决策制定。因此,情境中的强化学习(ICRL)和序列决策制定成为了自然的下一个研究前沿。LLMs已经被用作从自然科学实验设计到游戏玩耍等应用的决策制定代理,但我们对ICRL的理论和操作理解远不如ICSL。
决策制定代理必须具备三个核心能力:泛化(对于监督学习是必需的)、探索(为了收集更多信息而做出可能在短期内不是最优的决策)和规划(考虑决策的长期后果)。本文关注探索,即有意识地收集信息以评估替代方案和减少不确定性的能力。最近的一系列论文证明了当LLMs被明确训练以产生包括探索在内的强化学习行为时,变换器模型会表现出情境中的强化学习行为。然而,这些发现并未阐明是否在标准训练方法下获得的通用LLMs中会表现出探索行为,这引出了以下基本问题:LLMs是否能够作为通用的决策制定代理。
实验设计:多臂老虎机环境中的LLMs探索行为
1. 多臂老虎机问题简介
多臂老虎机(MAB)是一种经典且被广泛研究的强化学习问题,它突出了探索与利用之间的权衡,即根据可用数据做出最佳决策。MAB的简单性、对RL的中心性以及对探索与利用的关注使其成为系统研究LLMs情境中探索能力的自然选择。
2. 实验中的提示设计多样性
我们使用LLMs作为在MAB环境中操作的决策制定代理,通过提示来与MAB实例进行交互。我们的提示设计允许多种独立选择,包括“场景”(例如作为选择按钮的代理或作为向用户显示广告的推荐引擎)、“框架”(明确提示需要平衡探索和利用的需要或保持中立)、历史呈现方式(作为一系列原始列表或通过每个臂的播放次数和平均奖励进行总结)、最终答案的请求方式(单个臂或臂的分布)以及是否允许LLM提供“思维链”(CoT)解释。这些选择共同导致了32种提示设计。
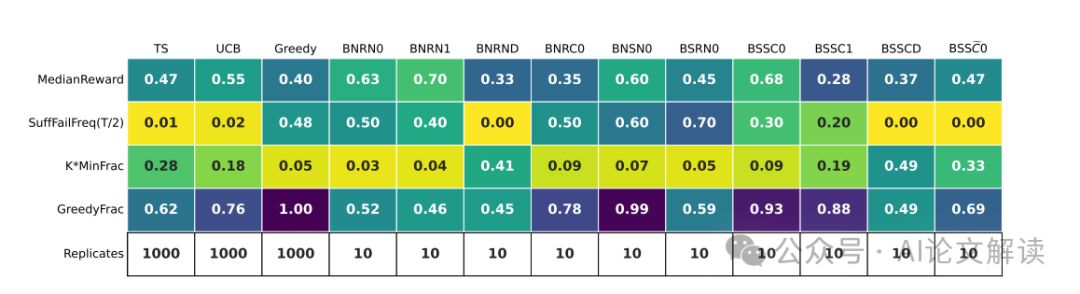
我们发现,只有一种配置(即提示设计和LLM配对)在我们的实验中表现出令人满意的探索行为。所有其他配置都表现出探索失败,未能显著概率地收敛到最佳决策(臂)。我们得出结论,尽管当前一代LLMs在适当的提示工程下或许可以在简单的RL环境中探索,但可能需要进一步的训练干预,例如微调或数据集策划,以赋予LLMs在更复杂环境中所需的更复杂的探索能力。
实验结果概览:LLMs在探索任务中的普遍失败
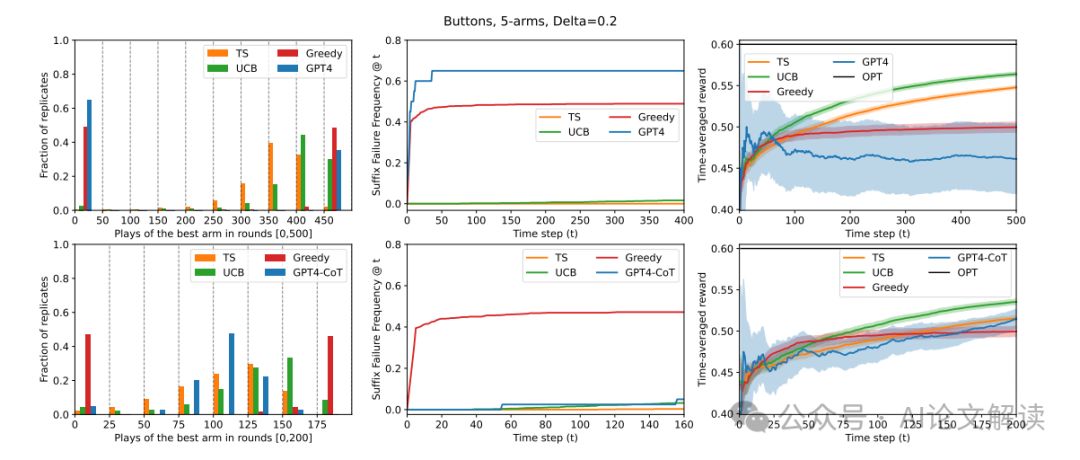
在研究大型语言模型(LLMs)在探索任务中的表现时,我们发现它们在没有额外训练干预的情况下普遍无法有效地进行探索。我们使用了多种提示设计,部署了Gpt-3.5、Gpt-4和Llama2作为代理,在多臂老虎机环境中进行实验。实验结果显示,除了一种特定配置外,其他所有配置都未能展现出稳健的探索行为。这些配置中,即使包含了链式推理(chain-of-thought reasoning)但没有经过外部总结的历史记录,也未能成功引导模型进行有效探索。这表明在更复杂的环境中,如果无法进行外部总结,LLMs可能无法进行有效的探索。
成功案例分析:Gpt-4在特定配置下的探索成功
成功配置的详细介绍
在我们的实验中,唯一一种成功的配置涉及到Gpt-4模型,结合了增强型提示设计。这种配置包括:使用按钮场景(buttons scenario)、建议性框架(suggestive framing)、外部总结的互动历史(summarized interaction history),以及要求模型使用零次射击链式推理(zero-shot chain-of-thought reasoning)。此外,该配置使用了温度参数为0,以确保模型的确定性行为,从而隔离了模型自身的“有意”探索行为。
成功配置与基线算法的对比
与基线算法相比,Gpt-4在这种配置下的表现与UCB(上置信界算法)和TS(汤普森采样算法)等具有理论保证的标准多臂老虎机算法有着根本的不同。在实验中,Gpt-4的这种配置避免了后缀失败(suffix failures),并且在奖励方面与TS相当。这表明,通过精心设计提示,最新的LLMs确实具备稳健探索的能力。然而,这种配置如果没有外部总结,就会失败,这进一步表明在需要外部算法设计的复杂环境中,LLMs可能无法进行有效探索。因此,我们得出结论,为了在复杂环境中赋予LLMs更复杂的探索能力,可能需要进行非平凡的算法干预,如微调或数据集策划。
探索失败的原因分析
1. 后缀失败与均匀失败的定义与检测
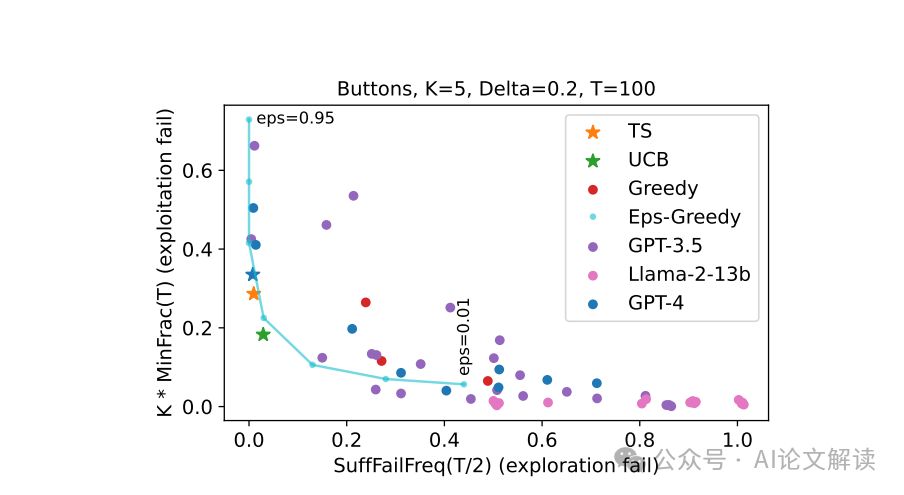
在研究大型语言模型(LLMs)的探索能力时,我们发现了两种主要的失败模式:后缀失败和均匀失败。后缀失败指的是在一系列尝试之后,模型未能选择最佳选项,即使在后续的尝试中也是如此。这种情况通常发生在某个时间段的后半部分,表明模型在初期的探索之后未能继续探索。例如,Gpt-4在基本提示设计下的后缀失败率超过60%。均匀失败则是指模型在选择时表现出近似均匀的行为,未能区分表现好的和表现差的选项。
为了检测这些失败模式,我们引入了两个代理统计量:SuffFailFreq和MinFrac。SuffFailFreq衡量的是在一定时间段内未选择最佳选项的频率,而MinFrac则衡量的是模型选择每个选项的最小比例。通过这些统计量,我们可以在实验的适度规模下检测长期探索失败,即使在标准性能度量(如奖励)过于嘈杂时也是如此。
2. 失败配置的行为模式
我们发现,除了一种特定的配置外,大多数LLM配置都表现出探索失败。这些配置未能在显著的概率下收敛到最佳选项。唯一的例外是Gpt-4结合增强提示、外部总结的交互历史和零次射击链式推理(chain-of-thought reasoning)的配置。这表明,只有在提示设计得当时,LLMs才能表现出强大的探索能力。然而,没有外部总结的相同配置失败了,这表明在更复杂的环境中,LLMs可能无法进行探索,因为在这些环境中外部总结历史是一个非平凡的算法设计问题。
相关工作回顾:LLMs能力研究的相关文献
在研究LLMs的能力时,已有大量文献集中于探索这些模型的各种能力。例如,Brown等人(2020)发现了LLMs的在上下文中学习(in-context learning)的能力,这是一种使得预训练的LLM能够通过在LLM提示中完全指定问题描述和相关数据来解决问题的能力。Garg等人(2022)通过在提示中包含数值协变量向量和标量目标,然后在提示中包含新的协变量向量来获得类似回归的预测,展示了LLMs的这一能力。
讨论与未来工作方向
对LLMs探索能力的启示
在探索Large Language Models(LLMs)在强化学习和决策制定中的探索能力时,我们发现现有的LLMs并不能在没有显著干预的情况下稳定地进行探索。在多臂老虎机(multi-armed bandit, MAB)环境中,只有Gpt-4结合链式推理(chain-of-thought reasoning)和外部总结的交互历史,表现出了令人满意的探索行为。这一发现提示我们,尽管LLMs在设计合适的提示(prompt)时能够表现出探索能力,但在更复杂的环境中,这种能力可能会受限,因为外部总结历史在这些环境中可能是一个复杂的算法设计问题。
提高LLMs决策能力的潜在干预措施
为了提高LLMs在复杂环境中的决策能力,可能需要采取非平凡的算法干预措施,例如微调(fine-tuning)或数据集策展(dataset curation)。这些干预措施的目的是为LLMs赋予更复杂的探索能力,使其能够在更具挑战性的设置中有效地作为决策代理。此外,我们可能需要进一步的方法论或统计进步,以便成本效益地诊断和理解LLM代理的行为。
总结
本文的研究表明,当前代LLMs在没有适当的提示工程或训练干预的情况下,可能无法在简单的强化学习环境中进行探索。尽管Gpt-4在特定配置下展现了一定的探索能力,但这一成功配置依赖于外部总结的交互历史和增强的链式推理提示,这在更复杂的环境中可能不可行。因此,我们得出结论,为了在复杂环境中赋予LLMs更高级的探索能力,可能需要进行更深入的算法干预研究。