目录
一、Filebeat介绍
1、Filebeat简介
2、Filebeat的工作方式
3、filebeat工作流程
4、Filebeat的作用
5、filebeat的用途
1.为什么要用filebeat来收集日志?为什么不直接用logstash收集日志?
2.filebeat和logstash的区别
二、部署(ELFK)Filebeat+ELK
1、环境准备
2、安装Filebeat
3、设置filebeat的主配置文件
4、在Logstash组件所在节点新建一个Logstash配置文件
5、启动filebeat
6、启动Logstash
7、浏览器访问
一、Filebeat介绍
1、Filebeat简介
Filebeat由两个主要组成部分组成:prospector(探勘者)和 harvesters(矿车)。这些组件一起工作来读取文件并将事件数据发送到指定的output。
- prospector: 负责找到所有需要进行读取的数据源
- harvesters:负责读取单个文件的内容,并将内容发送到output中,负责文件的打开和关闭。
2、Filebeat的工作方式
Filebeat可以保持每个文件的状态,并且频繁地把文件状态从注册表里更新到磁盘。这里所说的文件状态是用来记录上一次Harvster读取文件时读取到的位置,以保证能把全部的日志数据都读取出来,然后发送给output。如果在某一时刻,作为output的ElasticSearch或者Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。
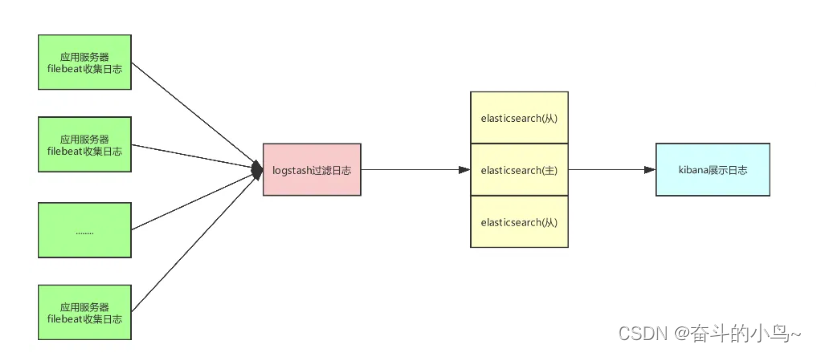
3、filebeat工作流程
- filebeat 将日志收集后交由 logstash 处理
- logstash 进行过滤、格式化等操作,满足过滤条件的数据将发送给 ES
- ES 对数据进行分片存储,并提供索引功能
- Kibana 对数据进行图形化的 web 展示,并提供索引接口
4、Filebeat的作用
- 由于 logstash 会大量占用系统的内存资源,一般我们会使用 filebeat 替换 logstash 收集日志的功能,组成 ELFK 架构
- 或用 fluentd 替代 logstash 组成 EFK(elasticsearch/fluentd/kibana),由于 fluentd 是由 Go 语言开发的,一般在 K8s 环境中使用较多
5、filebeat的用途
适用于集群环境下,服务多,且部署在不同的机器。
1.为什么要用filebeat来收集日志?为什么不直接用logstash收集日志?
因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存(这就是为什么logstash启动特别慢的原因),而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,logstash根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。
2.filebeat和logstash的区别
| logstash | Filebeat | |
|---|---|---|
| 内存 | 大 | 小 |
| CPU | 大 | 小 |
| 插件 | 多 | 多 |
| 功能 | 从多种输入端采集并实时解析和转换数据并输出到多种输出端 | 传输 |
| 过滤能力 | 强大的过滤能力 | 有过滤能力但是弱 |
| 轻重 | 相对较重 | 轻量级二进制文件 |
| 进程 | 一台服务器只允许一个logstash进程,挂掉之后需要手动启动 | |
| 集群 | 单节点 | 单节点 |
| 原理 | Logstash使用管道的方式进行日志的搜集和输出,分为输入input处理filter(不是必须的)输出output,每个阶段都有不同的替代方式 | 开启进程后会启动一个或多个探测器(prospectors)去检测指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester) ,每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的 |
二、部署(ELFK)Filebeat+ELK
1、环境准备
在 ELK 的服务配置的基础上,增加一台 Filebeat 服务器,其余不变
| 服务器类型 | 系统和IP地址 | 需要安装的组件 |
|---|---|---|
| node1节点 | 192.168.10.100 | Elasticsearch 、 Kibana |
| node2节点 | 192.168.10.101 | Elasticsearch |
| Logstash节点 | 192.168.10.102 | Logstash、Apache |
| Filebeat节点 | 192.168.10.103 | Filebeat |
更改filebeat节点的主机名
[root@localhost ~]#hostnamectl set-hostname filebeat
[root@localhost ~]#bash
2、安装Filebeat
[root@filebeat ~]#cd /opt/
[root@filebeat opt]#rz -E
rz waiting to receive.
[root@filebeat opt]#ls
filebeat-6.6.1-x86_64.rpm rh
[root@filebeat opt]#rpm -ivh filebeat-6.6.1-x86_64.rpm
警告:filebeat-6.6.1-x86_64.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:filebeat-6.6.1-1 ################################# [100%]
[root@filebeat opt]#ls
filebeat-6.6.1-x86_64.rpm rh
3、设置filebeat的主配置文件
[root@filebeat opt]#cd /etc/filebeat/
[root@filebeat filebeat]#ls
fields.yml filebeat.reference.yml filebeat.yml modules.d
[root@filebeat filebeat]#cp filebeat.yml filebeat.yml.bak
[root@filebeat filebeat]#vim filebeat.yml
filebeat.inputs: ##15行
- type: log ##21行
enabled: true ##24行
paths: ##27行
- /var/log/messages ##28行
- /var/log/*.log ##29行
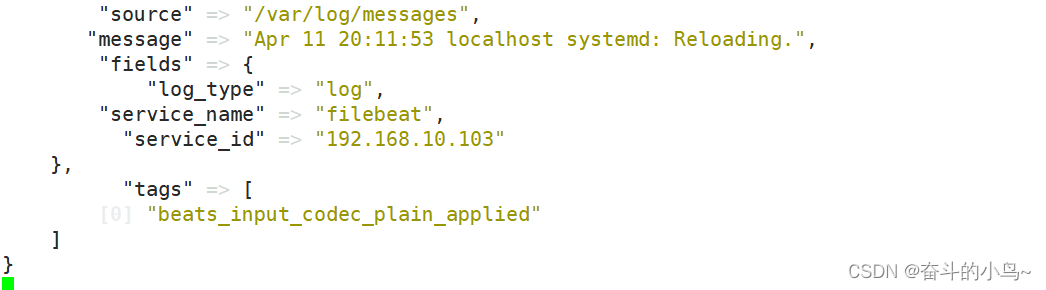
fields: ##46行
service_name: filebeat ##47行
log_type: log ##48行
service_id: 192.168.10.103 ##49行
#output.elasticsearch: ##152行,注释起来
# hosts: ["localhost:9200"] ##154行,注释起来
output.logstash: ##165行,取消注释
hosts: ["192.168.10.102:5044"] ##167行,取消注释,然后将localhost改为Logstash的IP地址




4、在Logstash组件所在节点新建一个Logstash配置文件
[root@logstash ~]#cd /etc/logstash/conf.d/
[root@logstash conf.d]#vim fb_logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.10.100"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}

[root@filebeat filebeat]#systemctl start filebeat.service
[root@filebeat filebeat]#systemctl enable filebeat.service
[root@filebeat filebeat]#systemctl status filebeat.service 5、启动filebeat
如果使用tar包安装使用它启动 /usr/local/filebeat/filebeat -e -c filebeat.yml 或 ./filebeat -e -c filebeat.yml
如果使用rpm包安装使用systemctl start filebeat.service启动filebeat
[root@filebeat filebeat]#systemctl start filebeat.service
[root@filebeat filebeat]#systemctl enable filebeat.service
[root@filebeat filebeat]#systemctl status filebeat.service 
6、启动Logstash
[root@logstash conf.d]#ls
apache_log.conf fb_logstash.conf system.conf
[root@logstash conf.d]#logstash -f fb_logstash.conf
稍等片刻,还会出来数据
7、浏览器访问
http://192.168.10.100:9100

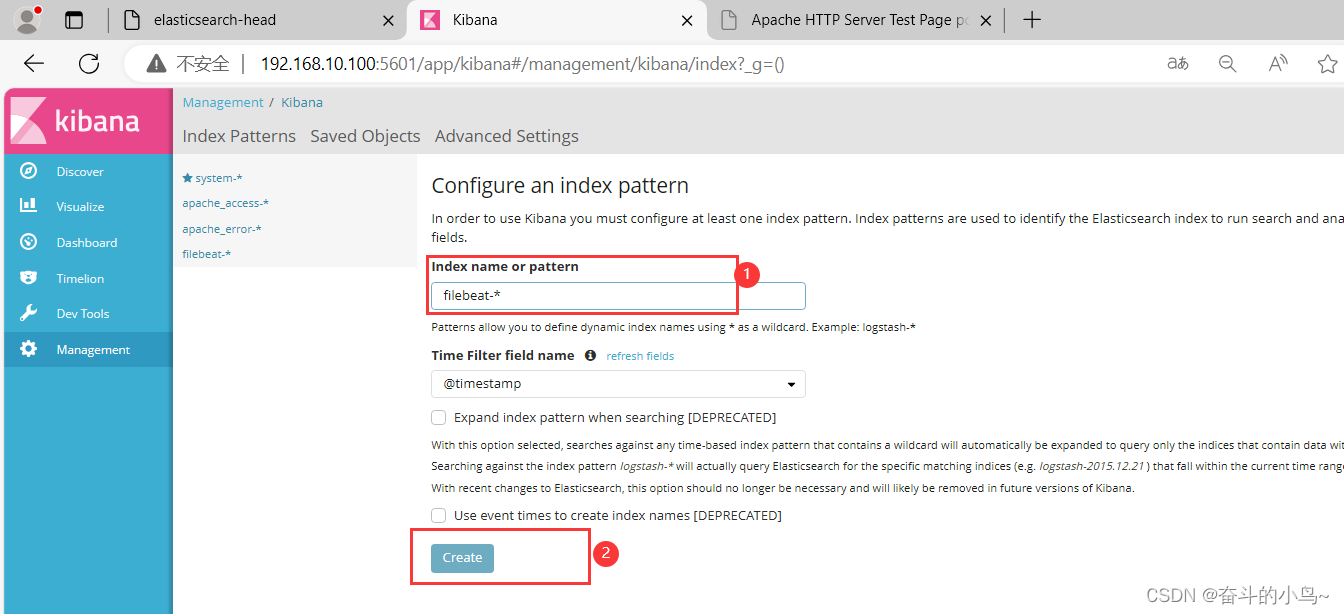
8、浏览器访问 http://192.168.10.100:5601 登录 Kibana
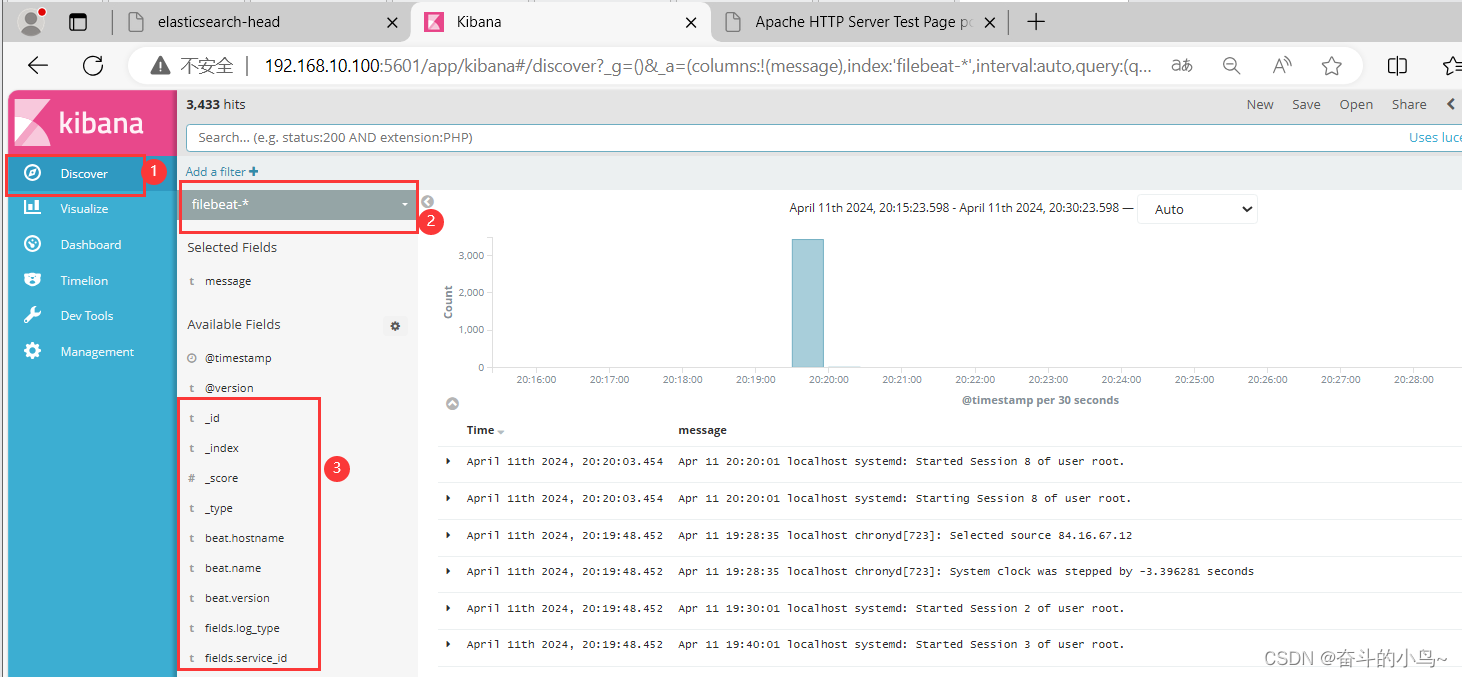
单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息


总结:
1、一般用什么来代替logstash?为什么?
一般使用Filebeat代替logstash
因为logstash是由Java开发的,需要运行在JVM上,耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患;而filebeat是一款轻量级的开源日志文件数据搜集器,能快速收集数据,并发送给 logstash 进行解析,性能上相比运行于 JVM 上的 logstash 优势明显。
2、feilbeat +Logstash + Elasticsearch +Kibana模式
这是一种更加完善和灵活的架构,适合处理复杂的日志数据
并将其发送到Elasticsearch进行索引。kibana则可以用来查看和分析日志数据
在这种模式下,filebeat (beats)负责收日志文件,并将其发送到logstash进行处理。logstash可以对日志数据进行更多的过滤、转换和增强的操作,并将其发送到Elasticsearch进行索引。kibana则可以用来查看和分析日志数据
3、feilbeat+缓存/消息队列+Logstash + Elasticsearch + Kibana 模式
这是一种加健壮高效的架构,适合处理海量复杂的日志数据,在这种模式下,filebeat和logstach之间加入缓存或消息队列组件,如redis、kafka或RabbitMQ等 ,这样可以降低对日志源主机的影响 ,提高日志传输的稳定性和可靠性,以及实现负载均衡和高可用