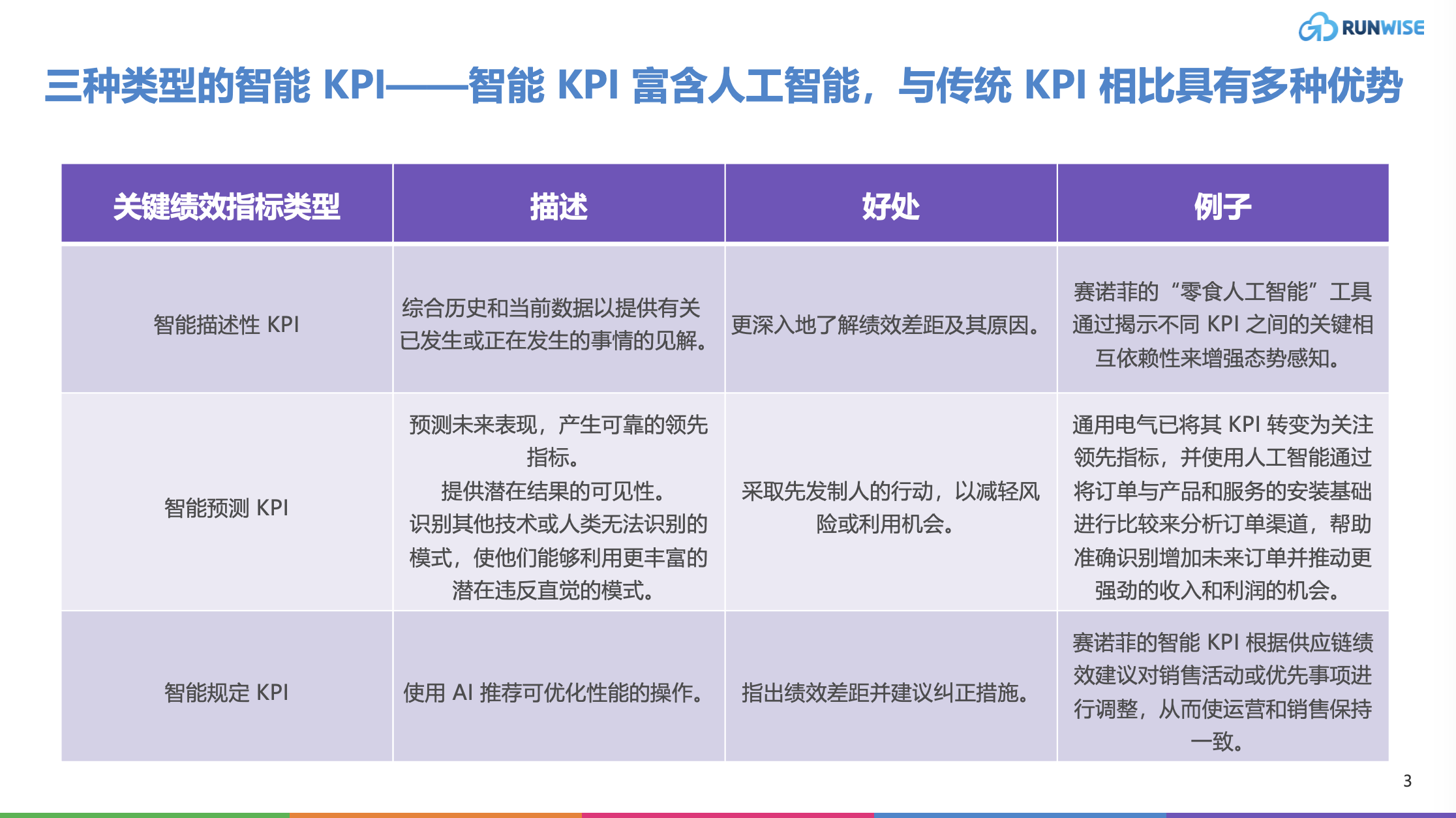
gradio简单搭建——关键词简单筛选[2024-4-11 优化]
- 新的思路:标签自动标注
- 界面搭建优化
- 数据处理与生成过程
- 交互界面展示
新的思路:标签自动标注
针对通过关键词,在文本数据中体现出主体的工作类型这一任务,这里使用展示工具gradio制作一个简单的交互平台。在前两天的优化后,我们可以通过无效关键词、单元素/多元素关键词顺序匹配的方式对文本数据进行约束,从而找出符合匹配条件的数据信息,并更加高效地执行下游的标注任务。
当对数据信息存在一定程度的了解后,我们可以找出一些针对性极强的关键词,就像上一节描述的低光速黑域一样——“简单、潦草”地看上一眼,就能知道主体的动作、行为大概率描述某一具体工作。例如:
某人对材料进行焊接过程中,不小心被烫伤。
分析:焊接这个词更多是电焊工/焊接工的专业动作;过程中则描述过去正在进行专业动作的状态。这两个词的组合成的关键词,可以极大概率指向电焊工/焊接工这个工种。
但是发现:如果仅仅是查找,单元素关键词匹配已经实现了,但标注工作还是要亲自去做。为了减少操作步骤、简化工作量,我们更希望:这类指向性强关键词,直接将对应标签标注上去。这也是本次优化目标:
- 添加一组标注相关的单选框,将单/多元素关键词匹配的查找结果对应的标签信息更新到原始数据中,最终输出完整数据;
- 给单选框设置默认值,减少
greet函数内的判断逻辑。
界面搭建优化
这里并没有强制性地赋予单/多元素匹配单选框默认选项。主要因为上一节关于该单选框均为空也可以执行.
import gradio as gr
from file_generator import generate_file
class CONST:
file_type_list = ['xlsx']
def submit(input_file,
invalid_task,
invalid_keyword_input,
task,
keyword_input,
mask_task,
mask_keyword,
desc):
print(f'task:{task}')
print(f'keyword_input:{keyword_input}')
print(f'invalid_task:{invalid_task}')
print(f'invalid_keyword_input:{invalid_keyword_input}')
# 输入文件格式设置
if not input_file:
raise gr.Error('请上传文件')
if '\\' in input_file:
input_file = input_file.replace('\\','/')
suf = input_file.split('.')[-1]
if suf not in CONST.file_type_list:
raise gr.Error('不支持的格式:{},请检查文件格式'.format(suf))
# 2024-4-11 优化:添加了无效元素匹配单选框的默认选项,减少一部分判断操作
if invalid_keyword_input:
if invalid_task == '禁用':
raise gr.Error('无效元素匹配[禁用]时,无法输入无效元素') # 选择禁用时,文本框不可用
else:
if ',' in invalid_keyword_input:
invalid_keyword_input = invalid_keyword_input.replace(',',',')
if ',' in invalid_keyword_input:
invalid_keyword_list = invalid_keyword_input.split(',')
else:
invalid_keyword_list = [invalid_keyword_input]
else:
if invalid_task == '启用':
raise gr.Error('无效元素匹配[启用]时,请输入无效元素') # 选择启用时,文本框内必须输入无效元素
else:
invalid_keyword_list = list()
# [单/多元素匹配]逻辑描述
# 暂未添加单选框的[默认]选项
if task:
if not keyword_input:
raise gr.Error('请输入匹配关键词') # 已选择[单/多元素匹配]条件下,文本框内必须输入匹配元素
else:
if ',' in keyword_input:
keyword_input = keyword_input.replace(',',',')
if ',' in keyword_input:
if task == '单元素匹配':
raise gr.Error('单元素匹配模式不支持输入多个关键词')
else:
keyword_list = keyword_input.split(',')
else:
if task == '多元素匹配':
raise gr.Error('多元素匹配模式不支持输入单个关键词')
else:
keyword_list = [keyword_input]
else:
task = '无元素匹配'
keyword_list = list() # 未选择使用[单/多元素匹配]
# [仅执行查找,填充]逻辑操作
if mask_keyword:
if mask_task == '仅执行查找':
raise gr.Error('仅执行查找模式不支持输入标注关键词')
# bug修改:必须保证[元素匹配关键词]中有值
else:
try:
assert len(keyword_list)
except AssertionError:
raise gr.Error('填充状态下,匹配关键词文本框不能为空')
else:
if mask_task == '填充':
raise gr.Error('填充模式,请输入标注关键词')
output = generate_file(input_file,
task,
invalid_task,
mask_task,
keyword_list,
invalid_keyword_list,
mask_keyword)
return output
description = """
1. 单元素匹配:筛选出包含输入元素的样本;
2. 多元素匹配:筛选出按输入元素顺序,包含输入元素的样本;
2024/4/10
3. 无效元素匹配:元素匹配过程中,一旦出现无效元素,则不包含该样本;
一次性可以输入多个元素,使用逗号(英文)分隔;
例: 上班途中,下班途中,...
4. [无效元素匹配]与[单/多元素匹配]操作之间可单独使用,也可混用;
2024/4/11
5. 仅执行查找:仅找出与1,2,3,4步骤的筛选结果;最终返回[仅包含筛选结果]的数据文件;
6. 填充:将待填充关键词写入文本框中,最终返回[填充筛选结果]对应标注信息的[完整数据文件];
"""
demo = gr.Interface(
fn=submit,
inputs = [
gr.File(
file_count="single",
label="上传文件",
file_types=CONST.file_type_list
),
# 无效元素匹配单选框
gr.Radio(
choices=['启用','禁用'],
label='无效元素匹配',
value='禁用',
),
gr.Textbox(
label='无效关键词',
placeholder='可以一次输入多个数据,使用逗号(英文)间隔;若选择禁用,文本框为空',
),
# 匹配单元素,多元素单选框
gr.Radio(
choices=['单元素匹配','多元素匹配'],
label='选择元素匹配模式',
),
gr.Textbox(
label='匹配关键词',
placeholder='请输入匹配关键词'
),
# 仅执行查找,填充单选框
gr.Radio(
choices=['仅执行查找','填充'],
label='选择填充模式',
value='填充'
),
gr.Textbox(
label='输入标准标注',
placeholder='若选择填充,请输入对应标准标注(唯一);若选择仅执行查找,文本框为空',
),
gr.Text(
description,
label='使用说明'
)],
outputs=gr.File(label='输出文件'),
title='单元素/多元素匹配筛选数据',
examples=[['测试文件.xlsx','启用','上班途中','单元素匹配','焊接过程中','填充','焊接工']]
)
demo.launch(share=False, server_name='192.168.11.115',server_port=8706)
数据处理与生成过程
update方法更新df
import pandas as pd
import time
import os
def sorted_keywords_update(df, task, invalid_task, mask_task, keyword_list, invalid_keyword_list, mask_keyword):
def sorted_keywords(str_input,sorted_word_list):
"""查找列表中的关键词,如果关键词有序地匹配成功返回True,否则返回False"""
count = 0
while count < len(sorted_word_list):
if sorted_word_list[count] in str_input:
str_input = "".join(str_input.split(sorted_word_list[count])[1:])
count += 1
else:
break
if count == len(sorted_word_list):
return True
else:
return False
def eliminate_invalid(df_input,invalid_keyword_list):
"""无效元素匹配[启用]状态下,筛除包含invalid_keyword_list内词对应的行"""
for invalid_word in invalid_keyword_list:
df_input = df_input[~df_input['文本信息'].str.contains(invalid_word)]
return df_input
def mode_2_rules(row):
"""多元素匹配模式规则"""
return sorted_keywords(row['文本信息'],keyword_list) == True
def mode_1_rules(df_input, keyword_list):
"""单元素匹配模式规则"""
assert len(keyword_list) == 1
contain_df = df_input[df_input['文本信息'].str.contains(keyword_list[0])]
return contain_df
# 去除已标注过的数据
sub_df = df[df['标注信息'].isna()]
# 去除数据中的nan值
sub_df = sub_df[~sub_df['文本信息'].isna()]
# 筛选无效元素过程
if invalid_task == '启用':
invalid_sub_df = eliminate_invalid(sub_df,invalid_keyword_list)
else:
invalid_sub_df = sub_df
# 元素匹配过程
if task == '单元素匹配':
contain_df = mode_1_rules(invalid_sub_df,keyword_list)
elif task == '多元素匹配':
contain_df = invalid_sub_df[invalid_sub_df.apply(mode_2_rules,axis=1)]
else:
contain_df = invalid_sub_df
# 创建输出文件夹
output_dir = f'./output/match_keyword/{task}'
output_path = f'{output_dir}/{task}_res.xlsx'
os.makedirs(output_dir, exist_ok=True)
# 标准标注填充与写入过程并输出完整数据
if mask_task == '填充':
start = time.time()
contain_copy = contain_df.copy()
contain_copy['标注信息'] = mask_keyword
df.update(contain_copy) # 注意,在选择扩充时,返回完整数据;
end = time.time()
print(f'spend time:{round(end - start,4)}')
df.to_excel(output_path, index=False)
# 查找状态下,仅输出查找相关的数据
else:
contain_df.to_excel(output_path, index=False)
return output_path
def generate_file(file_path, task, invalid_task, mask_task, keyword_input, invalid_keyword_input, mask_keyword):
"""
file_path: 待优化数据文件路径
task: 匹配模式:[单模式匹配,多模式匹配]
invalid_task: 无效匹配模式:[启用,禁用]
mask_task:标准标注填充模式:[仅执行查找,填充]
keyword_input: 匹配关键词
invalid_keyword_input: 无效匹配关键词
mask_keyword: 标准标注关键词
"""
df = pd.read_excel(file_path)
# 数据生成平台
output_file_path = sorted_keywords_update(df, task, invalid_task, mask_task, keyword_input, invalid_keyword_input, mask_keyword)
return output_file_path
交互界面展示