✨ 1: udio
由音乐和科技界重量级人物支持的强大 AI 音乐生成器,被称为音乐界的另一个 ChatGPT。

Udio 由前 Google DeepMind的研究院和工程师创立,得到了a16z的支持,总部在伦敦和纽约。
目前是一个免费的V1测试版产品,每个人每个月可以生成最多 1200 首歌曲。
Udio是一个强大的AI音乐生成器,它背后有音乐和技术领域的重量级支持。它可以根据文本提示生成完整、高保真度的歌曲,特别是在真实听起来像人声的方面表现出色。Udio是由一群前谷歌DeepMind的员工创立的,迅速吸引了技术和音乐界大佬的投资,包括a16z(即Andreesen Horowitz)和Instagram联合创始人兼CTO迈克·克里格尔,以及音乐界的名人如Common、制作人Tay Keith等。
地址:https://www.udio.com/
✨ 2: Akuma Ai
能够实时通过操作动作骨骼生成动漫艺术图像的网站
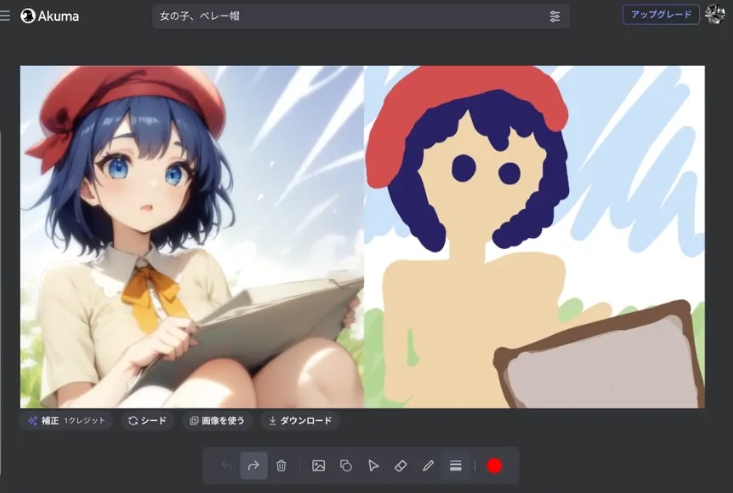
Akuma AI是一款免费并且能够实时操作的AI动漫艺术生成器,旨在帮助用户快速生成不同动作的动漫艺术图像。
Akuma AI是一个功能强大且易于上手的AI动漫艺术生成器,适用于广泛的应用场景,从个人兴趣到专业创作,都能提供实时、高效的动漫图像生成服务。
地址:https://heehel.com/aigc/akuma-ai.html
✨ 3: AutoCodeRover
又一个开源AI Devin 程序员
AutoCodeRover 是一个用来解决 GitHub 问题(比如修复漏洞和增加功能)的全自动程序改进工具。它通过结合大型语言模型(LLM)和分析调试能力,优先考虑修补位置以生成修补方案。这个工具在 SWE-bench lite 这个包含了 300 个真实世界 GitHub 问题的平台上,大约解决了 22% 的问题,这比现有的 AI 软件工程师的解决效率要高。
地址:https://github.com/nus-apr/auto-code-rover
✨ 4: op3 soccer
深度强化学习培养双足机器人灵活的足球技能,包括踢球、追球等

OP3 Soccer是一个先进的机器人足球项目,运用了深度强化学习技术(Deep Reinforcement Learning, 简称Deep RL)来教会低成本的双足行走机器人在动态环境中表现出敏捷的足球技巧。这项研究的主要目的是探索如何使机器人掌握像铲球、站立、踢球和追球等连贯动作。
地址:https://sites.google.com/view/op3-soccer
✨ 5: Parler-TTS
一个轻量级的文本到语音(TTS)模型

Parler-TTS是一个轻量级的文本到语音(TTS)模型,可以以特定说话者的风格(包括性别、音调、说话风格等)生成高质量、自然听起来的语音。这个模型是根据Dan Lyth和Simon King的论文《使用合成注解的高保真文本到语音的自然语言指导》而开发的,Dan Lyth属于Stability AI,Simon King来自爱丁堡大学。
与其他TTS模型不同,Parler-TTS是完全开源发布的。所有的数据集、预处理、训练代码和权重都是公开发布的,这使得社区能够在此基础上建立自己的强大TTS模型。
地址:https://github.com/huggingface/parler-tts

更多AI工具,参考国内AiBard123,Github-AiBard123










![[StartingPoint][Tier2]Vaccine](https://img-blog.csdnimg.cn/img_convert/b8d655cc6871374fa21f68a810b121b7.jpeg)