java集合框架总览
Java集合框架是一个用来代表和操纵集合的统一架构,它为管理和组织对象的集合提供了一组类和接口。这个框架包含三个主要部分:接口、实现和算法。
接口:
- Collection:这是集合框架的根接口,定义了集合的基本操作,如添加、删除、遍历等。
- List:表示一个有序的集合(元素可以重复),它继承了Collection接口。
- Queue:代表一种特殊的线性表,只允许在表的前端进行删除操作,而在表的后端进行插入操作。
- Map:存储键值对(key-value pair)的集合。
- Set:一个不包含重复元素的集合。
实现:
- ArrayList:List接口的一个实现,它使用一个数组来存储元素。ArrayList提供了快速的随机访问,但插入和删除操作可能较慢。
- LinkedList:基于链表实现的List和Queue。它提供了快速的插入和删除操作,但随机访问可能较慢。
- HashMap:基于哈希表实现的Map,提供了快速的键值对存储和检索。
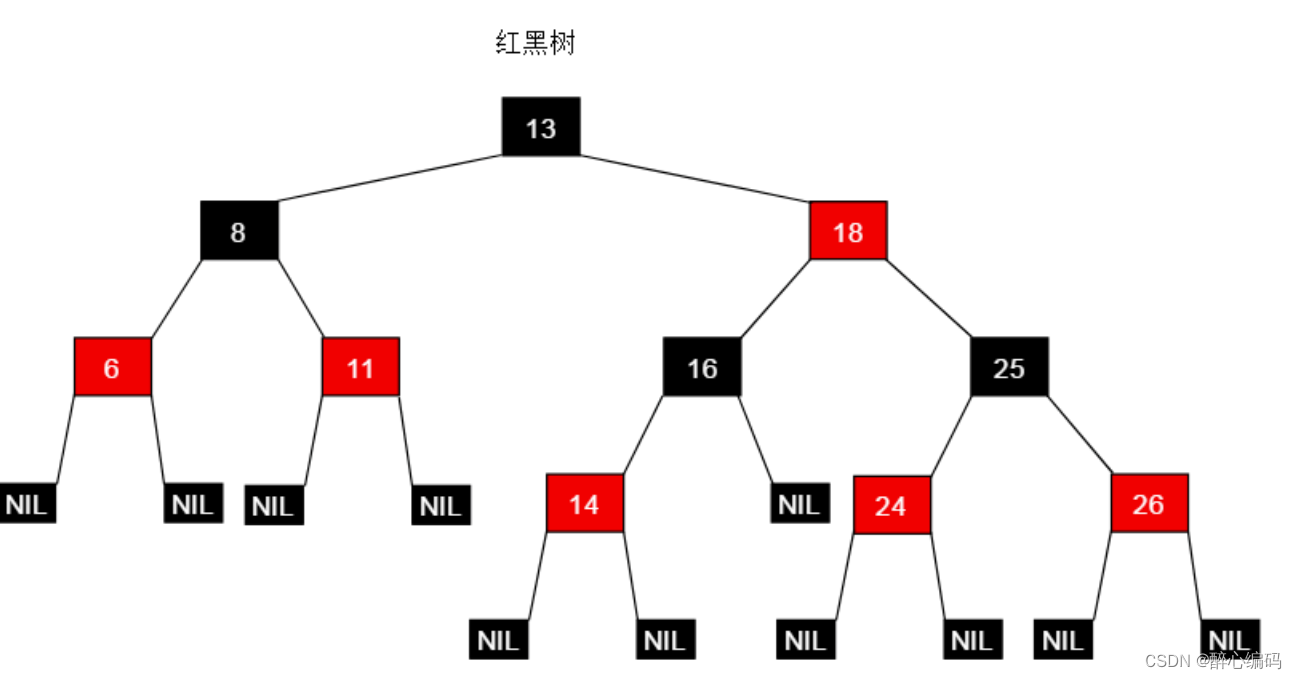
- TreeMap:基于红黑树实现的Map,可以对键进行排序。
- HashSet和TreeSet:都是Set接口的实现,其中HashSet基于哈希表,而TreeSet基于红黑树,可以对元素进行排序。
算法:
- 集合框架中的算法是指实现集合接口对象里的方法执行的一些有用的计算,例如搜索和排序。这些算法被称为多态,因为相同的方法可以在相似的接口上有着不同的实现。
此外,Java集合框架还提供了一些其他重要的数据结构,如栈(Stack)和哈希表(Hash Table)。栈是一种后进先出(LIFO)的数据结构,Java中的Stack类或Deque接口的实现类(如ArrayDeque)可以用来实现栈的功能。哈希表则是一种以键值对形式存储数据的数据结构,Java中的HashMap和Hashtable等类提供了哈希表的实现。
Java集合框架的作用不仅在于提供了一种灵活且高效的方式来处理各种数据结构,包括列表、集合、映射等,还提供了丰富的数据操作和算法支持,如排序、过滤、映射、归约等,这对于数据处理非常重要。同时,它还有助于避免并发访问问题,提高程序的稳定性。
总的来说,Java集合框架是一个强大且灵活的工具,它使得Java编程在处理集合数据时更加高效和便捷。
java.util.LinkedList
/**
* Doubly-linked list implementation of the {@code List} and {@code Deque}
* interfaces. Implements all optional list operations, and permits all
* elements (including {@code null}).
*
* <p>All of the operations perform as could be expected for a doubly-linked
* list. Operations that index into the list will traverse the list from
* the beginning or the end, whichever is closer to the specified index.
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a linked list concurrently, and at least
* one of the threads modifies the list structurally, it <i>must</i> be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more elements; merely setting the value of
* an element is not a structural modification.) This is typically
* accomplished by synchronizing on some object that naturally
* encapsulates the list.
*
* If no such object exists, the list should be "wrapped" using the
* {@link Collections#synchronizedList Collections.synchronizedList}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the list:<pre>
* List list = Collections.synchronizedList(new LinkedList(...));</pre>
*
* <p>The iterators returned by this class's {@code iterator} and
* {@code listIterator} methods are <i>fail-fast</i>: if the list is
* structurally modified at any time after the iterator is created, in
* any way except through the Iterator's own {@code remove} or
* {@code add} methods, the iterator will throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than
* risking arbitrary, non-deterministic behavior at an undetermined
* time in the future.
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @author Josh Bloch
* @see List
* @see ArrayList
* @since 1.2
* @param <E> the type of elements held in this collection
*/
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable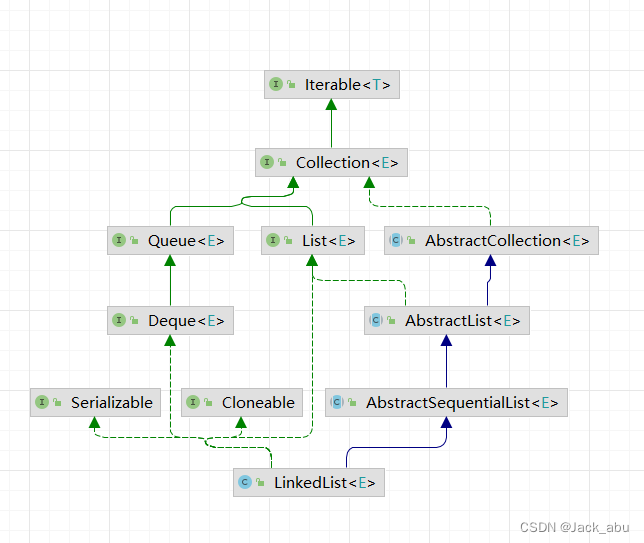
java.util.LinkedList 是 Java 集合框架中的一部分,它实现了 List 接口和 Deque 接口,用于表示一个双向链表。与 ArrayList 不同的是,LinkedList 的内部元素不是连续存储的,而是通过节点(Node)来连接各个元素。这种结构使得 LinkedList 在插入、删除操作上具有较高的效率,但在访问元素时,其效率可能较低,因为需要从头节点或尾节点开始遍历。
以下是 java.util.LinkedList 的一些主要特性和方法:
主要特性
- 双向链表:
LinkedList实现了双向链表,因此可以从头部或尾部进行插入和删除操作。 - 动态大小:链表的大小可以动态增长和缩小,以适应添加或删除元素的需求。
- 线程不安全:与
ArrayList一样,LinkedList的非同步实现也是线程不安全的。如果多个线程同时修改链表,可能会导致数据不一致。在多线程环境中,可以考虑使用Collections.synchronizedList方法来包装LinkedList,或者使用CopyOnWriteArrayList作为线程安全的替代方案。
主要方法
-
构造方法:
LinkedList():创建一个空的双向链表。LinkedList(Collection<? extends E> c):使用指定集合的元素来创建双向链表。
-
添加元素:
add(E e):在链表末尾添加元素。add(int index, E element):在指定位置插入元素。addAll(Collection<? extends E> c):在链表末尾添加指定集合的所有元素。addAll(int index, Collection<? extends E> c):从指定位置开始,将指定集合的所有元素插入链表。addFirst(E e)和addLast(E e)(通过Deque接口):在链表头部或尾部添加元素。
-
删除元素:
remove(int index):删除指定位置的元素。remove(Object o):删除链表中第一个出现的指定元素。removeAll(Collection<?> c):删除链表中所有包含在指定集合中的元素。removeFirst()和removeLast()(通过Deque接口):删除链表头部或尾部的元素。
-
查找和访问元素:
get(int index):返回指定位置的元素。getFirst()和getLast()(通过Deque接口):返回链表头部或尾部的元素。indexOf(Object o)和lastIndexOf(Object o):返回指定元素在链表中首次或最后出现的位置。
-
其他常用方法:
size():返回链表中元素的数量。isEmpty():检查链表是否为空。clear():删除链表中的所有元素。contains(Object o):检查链表中是否包含指定元素。iterator()和descendingIterator():返回链表的迭代器,用于遍历链表。listIterator(int index)和listIterator():返回链表的列表迭代器,用于在链表中双向遍历。
使用示例
下面是一个简单的示例,演示了如何使用 LinkedList:
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
// 添加元素
list.add("A");
list.add("B");
list.add("C");
// 访问元素
System.out.println(list.get(1)); // 输出 "B"
// 删除元素
list.remove("B");
// 遍历元素
for (String item : list) {
System.out.println(item);
}
}
} 这个示例展示了如何创建一个 LinkedList,添加元素,访问元素,删除元素以及遍历元素。需要注意的是,在实际开发中,应根据具体需求选择合适的集合类型,并考虑线程安全性和性能问题。
躲不掉的ArrayList与LinkedList对比
ArrayList和LinkedList在Java集合框架中都是用于存储元素的线性列表,但它们之间存在几个关键的区别,这些区别主要体现在内部数据结构、性能特性、内存占用以及线程安全性等方面。
内部数据结构:
- ArrayList:ArrayList是基于动态数组实现的。它使用一个可增长的数组来存储元素。由于数组在内存中是连续存储的,因此ArrayList在随机访问元素时非常高效。
- LinkedList:LinkedList是基于双向链表实现的。它使用节点来存储元素,每个节点包含数据和指向前后节点的引用。这种结构使得LinkedList在插入和删除元素时更加灵活。
性能特性:
- 访问元素:由于ArrayList是基于数组的,所以通过索引访问元素(get和set操作)非常快,时间复杂度为O(1)。而LinkedList需要从头或尾开始遍历才能访问到特定位置的元素,因此其访问操作的时间复杂度为O(n)。
- 插入和删除元素:在ArrayList中,如果在列表的中间位置插入或删除元素,可能需要移动大量的元素以保持数组的连续性,这会导致性能下降。相比之下,LinkedList的插入和删除操作只需要修改相关节点的指针指向,因此性能更好。特别是在列表的头尾位置进行插入和删除时,LinkedList的效率非常高。
内存占用:
- ArrayList在内存中占用连续的空间,因此其内存利用率相对较高。而LinkedList的每个节点除了存储数据外,还需要存储指向前后节点的引用,这增加了额外的内存开销。
线程安全性:
- ArrayList和LinkedList都不是线程安全的。如果在多线程环境下使用它们,需要手动进行同步处理或使用线程安全的替代品,如
Collections.synchronizedList()或CopyOnWriteArrayList。
扩容机制:
- 当ArrayList的容量不足以容纳更多元素时,它会创建一个新的更大的数组,并将原数组中的元素复制到新数组中。这个过程可能会涉及大量的数据移动。而LinkedList则没有扩容的问题,因为它是基于链表的,可以动态地添加和删除节点。
ArrayList基于数组实现,其元素在内存中是连续存储的。这种连续性存储有助于节省空间,因为数组元素之间没有额外的指针或引用。然而,当ArrayList需要扩容时(即当添加元素导致当前数组容量不足时),它会创建一个新的更大的数组,并将原数组中的元素复制到新数组中。这个扩容过程可能会涉及到一定的内存开销。
LinkedList则基于链表实现,其每个节点包含数据和指向前后节点的引用。这种结构使得LinkedList在内存占用上相对较为分散。由于每个节点除了存储数据本身外,还需要额外的空间来存储指针或引用,因此LinkedList在存储相同数量的元素时,可能会占用更多的内存。此外,由于链表不是连续存储的,所以可能会存在内存碎片的问题,进一步增加了内存管理的复杂性。
然而,需要注意的是,内存占用的比较并不只是简单的“ArrayList比LinkedList更节省内存”或“LinkedList比ArrayList占用更多内存”。实际情况取决于多个因素,包括元素的数量、元素的大小、ArrayList的扩容频率以及具体应用场景等。在某些情况下,ArrayList可能由于减少了指针的开销而更节省内存;而在其他情况下,LinkedList可能由于更好的空间利用率而占用更少的内存。
关于ArrayList与LinkedList的选择
在实际应用中,选择ArrayList还是LinkedList并没有绝对的“哪种更好”的答案,而是取决于具体的应用场景和需求。下面是一些指导原则,可以帮助你做出选择:
访问模式:
- 如果你需要频繁地访问列表中的元素,特别是通过索引访问,那么ArrayList通常会是更好的选择。由于ArrayList是基于数组的,通过索引访问元素非常快速。
- 相反,如果你主要是从头或尾开始遍历列表,或者进行插入和删除操作,那么LinkedList可能更合适。LinkedList的双向链表结构使得这些操作更加高效。
插入和删除操作:
- 如果你需要在列表的中间位置频繁地插入或删除元素,LinkedList的性能通常优于ArrayList。因为ArrayList在插入或删除元素时可能需要移动大量的元素以保持数组的连续性,而LinkedList只需要修改相关节点的指针指向。
- 然而,如果你在列表的末尾添加元素,ArrayList的
add方法通常比LinkedList更快,因为ArrayList的容量可以预先分配,而LinkedList则需要创建新的节点并更新指针。
内存占用:
- 在内存占用方面,ArrayList通常比LinkedList更紧凑,因为它在内存中是连续存储的。但是,当ArrayList需要扩容时,会涉及到创建新数组和复制元素的过程,这可能会增加临时的内存开销。
- LinkedList由于每个节点都需要存储数据和指针,因此可能会占用更多的内存。然而,如果元素数量很大且ArrayList频繁扩容,那么LinkedList的内存占用可能会相对更稳定。
线程安全性:
- ArrayList和LinkedList都不是线程安全的。如果你在多线程环境下使用它们,需要手动进行同步处理或使用线程安全的替代品。因此,在选择数据结构时,还需要考虑线程安全性的需求。
其他考虑因素:
- 如果你正在处理大量数据且内存使用是一个关键问题,那么可能需要考虑使用更高效的数据结构或库,如Java中的
ArrayDeque或第三方库提供的数据结构。 - 如果你正在编写性能敏感的代码,那么最好进行基准测试以比较不同数据结构在实际应用中的性能表现。
综上所述,选择ArrayList还是LinkedList取决于你的具体需求和应用场景。在实际应用中,建议根据访问模式、插入和删除操作的频率、内存占用以及线程安全性等因素进行综合考虑,并可能需要进行基准测试来确定最佳的选择。







![[react] useRef场景](https://img-blog.csdnimg.cn/direct/f476275eacb04745b59fc9556c55e340.png)