高效实现红黑树范围查询:RB-ENUMERATE操作的设计与分析
- 一、RB-ENUMERATE操作的需求分析
- 二、RB-ENUMERATE操作的设计思路
- 三、RB-ENUMERATE操作的具体实现
- 四、性能分析
- 五、结论
在红黑树的广泛应用中,我们经常需要对树中的元素进行查询和操作。除了基本的插入、删除和查找操作之外,有时还需要对树中的元素进行范围查询。本文将详细阐述如何设计一个名为RB-ENUMERATE的操作,该操作能够在保持红黑树原有属性不变的情况下,对树进行扩展,以实现在以x为根的红黑树中输出所有满足a≤k≤b条件的关键字k。
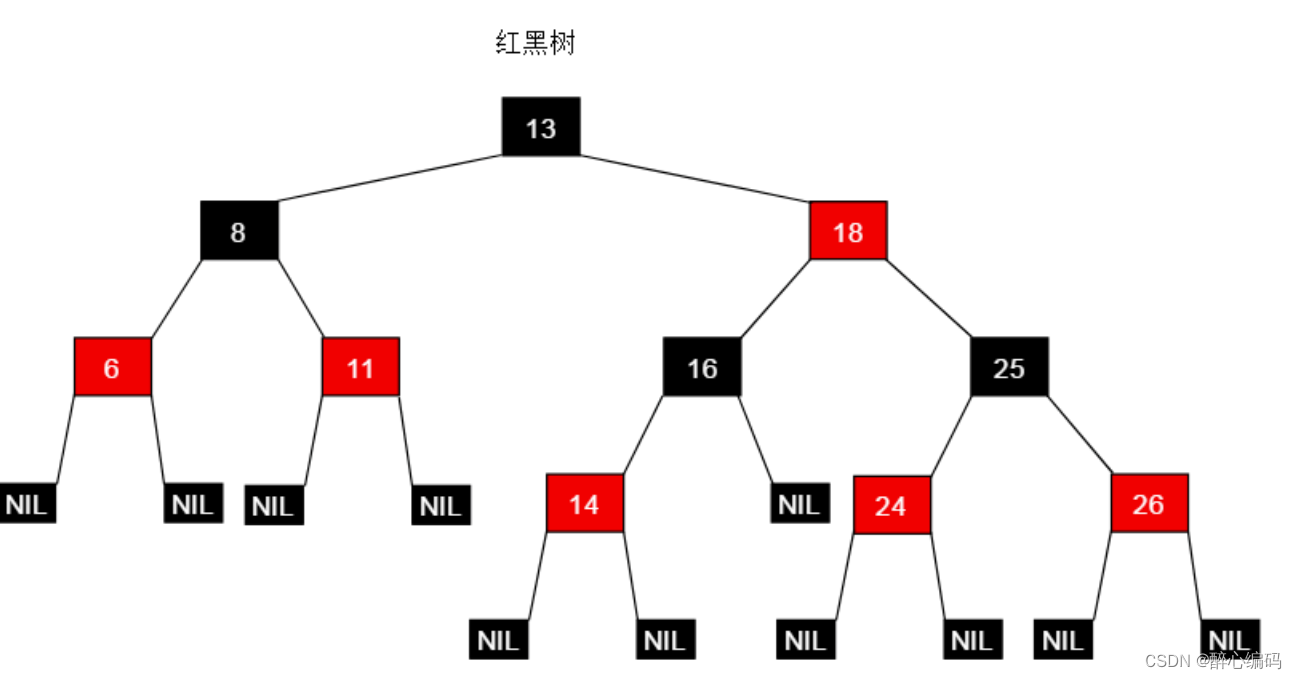
一、RB-ENUMERATE操作的需求分析
RB-ENUMERATE操作的目标是在对红黑树进行最小的改动的前提下,实现对树中特定范围元素的快速查询。这个操作需要满足以下条件:
- 高效性:操作的时间复杂度需要控制在O(m+lgn),其中m是输出关键字的数目,n是树中内部结点的数量。
- 无需扩展属性:在实现RB-ENUMERATE操作时,不能向红黑树的结点中添加新的属性,这意味着我们需要利用红黑树已有的信息来完成操作。
- 稳定性:操作不应该破坏红黑树的平衡性和其他操作的性能。
二、RB-ENUMERATE操作的设计思路
为了实现RB-ENUMERATE操作,我们可以采用以下设计思路:
- 利用已有结构:红黑树的每个结点已经包含了关键字和指向子结点的指针。我们可以利用这些已有的结构来辅助我们的查询。
- 递归遍历:从结点x开始,我们递归地遍历红黑树,对于每个结点,我们检查其关键字是否落在给定的范围[a, b]内。
- 中序遍历的性质:由于红黑树是有序的,我们可以利用中序遍历的性质来确保我们按照顺序输出关键字。
- 剪枝优化:在遍历过程中,当遇到不满足范围条件的子树时,我们可以提前停止对该子树的遍历,从而减少不必要的操作。
三、RB-ENUMERATE操作的具体实现
以下是RB-ENUMERATE操作的具体实现步骤:
- 初始化:设置一个指针current指向结点x,同时设置一个输出列表output。
- 递归遍历:执行以下递归函数:
void enumerate(Node* current, int a, int b, list<int>& output) { if (!current) return; // 遍历左子树 enumerate(current->left, a, b, output); // 检查当前结点是否在范围内 if (a <= current->key && current->key <= b) { output.push_back(current->key); } // 遍历右子树 enumerate(current->right, a, b, output); } - 调用递归函数:从结点x开始调用enumerate函数,并将结果存储在output中。
list<int> result; enumerate(x, a, b, result); - 输出结果:返回output列表作为RB-ENUMERATE操作的结果。
四、性能分析
RB-ENUMERATE操作的时间复杂度分析如下:
- 递归遍历会访问红黑树中的每个内部结点,因此时间复杂度为O(lgn)。
- 对于每个结点,我们进行常数时间的检查和可能的输出操作。
- 由于我们利用了红黑树的有序性,一旦确定一个子树的所有结点都不在范围内,我们就可以停止对该子树的遍历,这就是剪枝优化。
- 因此,总的时间复杂度为O(m+lgn),其中m是输出关键字的数目,n是树中内部结点的数量。
五、结论
通过上述设计和实现,我们成功地扩展了红黑树,使其具备了RB-ENUMERATE操作的能力。这个操作能够在保持红黑树原有性能的同时,高效地输出指定范围内的所有关键字。这种方法充分利用了红黑树的有序性和已有结构,无需添加新的属性,满足了操作的需求和性能要求。


![[react] useRef场景](https://img-blog.csdnimg.cn/direct/f476275eacb04745b59fc9556c55e340.png)