游客可以领取七天vip,愉快的开始爬取吧!
首先从单章入手:逆天邪神漫画 第1话 两世为人 - 漫客栈
一章有很多图片,每一张图片都有自己的地址,目标就是找到一个包,包含这一章所有图片的地址。
打开开发者工具——刷新,找到图片的位置,复制图片链接的关键参数,进行搜索。

 找到这个数据包,那么就开始发送请求,获取图片链接,进行保存吧。
找到这个数据包,那么就开始发送请求,获取图片链接,进行保存吧。
代码展现:
import requests
import os
filename = 'img\\'
if not os.path.exists(filename):
os.mkdir(filename)
def get_response(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
return response
def save_img(title,img_url):
img_content = get_response(img_url).content
with open(filename+str(title)+'.jpg','wb') as f:
f.write(img_content)
if __name__ == '__main__':
url = 'https://comic.mkzcdn.com/chapter/content/v1/?chapter_id=735749&comic_id=213295&format=1&quality=1&type=1'
response = get_response(url)
img_url_list = [page['image'] for page in response.json()['data']['page']] #列表推导式,获取所有图片的链接地址
title = 0
for img_url in img_url_list:
title = title+1
print(title)
save_img(title,img_url)结果展现:

比较第一章和第二章的载荷参数的不同


发现就只有chapter_id是不同的,故目前的目标就是找到每一章节的chapter_id,那么如何找呢,谨记在目录页可以找到。

找到数据包,那么开始解析数据吧

获取章节的id和章节的名字
def get_info():
url = 'https://www.mkzhan.com/213295/'
response = get_response(url).text
selector = parsel.Selector(response)
title = selector.css('.comic-title::text').get()
lis = selector.css('.j-chapter-item')
print(title)
for li in lis:
chapter_id = li.css('a::attr(data-chapterid)').get()
chapter_title = li.css('a::text').getall()[-1].strip()
print(chapter_id,chapter_title)结果展现:

现在跟前面的联系起来,完整代码展现:
import parsel
import requests
import os
def create_filename(title):
filename = f'{title}\\'
if not os.path.exists(filename):
os.mkdir(filename)
def create_title_filename(filename,title):
filename = filename+f'{title}\\'
if not os.path.exists(filename):
os.mkdir(filename)
def get_response(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
return response
def save_img(filename,chapter_title,num,img_url):
img_content = get_response(img_url).content
with open(filename+chapter_title+'\\'+str(num)+'.jpg','wb') as f:
f.write(img_content)
def get_info():
url = 'https://www.mkzhan.com/213295/'
response = get_response(url).text
selector = parsel.Selector(response)
title = selector.css('.comic-title::text').get()
lis = selector.css('.j-chapter-item')
chapterid_list = []
chapter_title_list = []
print(title)
for li in lis:
chapter_id = li.css('a::attr(data-chapterid)').get()
chapter_title = li.css('a::text').getall()[-1].strip()
chapterid_list.append(chapter_id)
chapter_title_list.append(chapter_title)
chapterid_list.reverse()
chapter_title_list.reverse()
print(chapterid_list)
print(chapter_title_list)
return title,chapterid_list,chapter_title_list
if __name__ == '__main__':
title,chapter_id_list,chapter_title_list = get_info()
create_filename(title)
filename = f'{title}\\'
for chapter_id,chapter_title in zip(chapter_id_list,chapter_title_list):
print(f'正在保存第{chapter_title}的内容')
create_title_filename(filename,chapter_title)
url = f'https://comic.mkzcdn.com/chapter/content/v1/?chapter_id={chapter_id}&comic_id=213295&format=1&quality=1&type=1'
response = get_response(url)
img_url_list = [page['image'] for page in response.json()['data']['page']] #列表推导式,获取所有图片的链接地址
num = 0
for img_url in img_url_list:
num = num + 1
save_img(filename, chapter_title, num, img_url)结果展现:
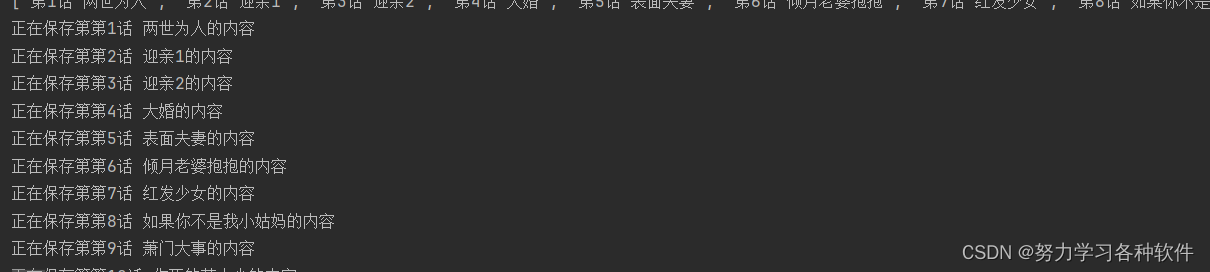
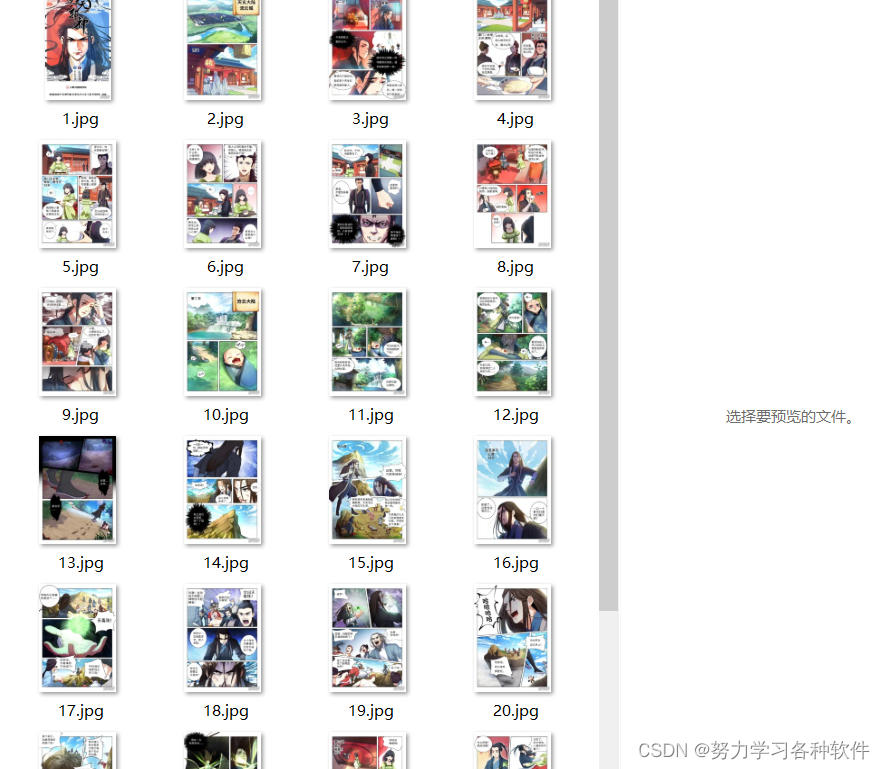
这就是这个案例啦,其实如果它狠心一点,大可以在载荷设置加密参数,或者在请求头要求cookie或者token。



![[react] useRef场景](https://img-blog.csdnimg.cn/direct/f476275eacb04745b59fc9556c55e340.png)