离了个大谱,弱智吧登上正经AI论文,还成了最好的中文训练数据?中国科学院、北京大学、中国科学技术大学、滑铁卢大学以及01.ai等十家知名机构联合推出了一款专注于中文的高质量指令调优数据集——COIG-CQIA。
在大型语言模型的研究领域,英文数据长期以来一直是训练这些模型的主要资源。然而,由于中英文在语法结构、文化背景以及表达习惯上的显著差异,简单地将英文数据集翻译成中文并不能取得理想的效果。为了解决高质量中文数据集匮乏的问题,研究者们开发了COIG-CQIA数据集。
COIG-CQIA数据集广泛搜集了中文互联网上的内容,包括论坛、网站、百度贴吧、以及其他问答社区等,确保了数据的丰富性和多样性。研究人员利用这个数据集对Yi-6B和Yi-34B这两个中文大型语言模型进行了指令调优,随后在BELLE-EVAL这一评估平台上测试了这些模型的性能。
令人惊讶的是,在对比不同来源的数据质量时,原本被认为内容质量较低的“弱智贴吧”在数据质量上竟然显著超越了知乎、豆瓣、是否等知名知识社区。这一发现颠覆了人们对不同平台内容质量的传统认知,也提醒我们,有时候所谓的“低端”或“俗气”的内容也可能蕴含着未被充分挖掘的价值。
弱智吧
一个充满荒谬、离奇、不合常理发言的中文社区,画风通常是这样的:

弱智吧AI代码能力也超过了使用专业技术问答社区思否数据训练的AI,这下贴吧中中网友炸开了锅,更有之怀疑自我:
数据质量
下面我们具体来看看弱智吧的数据如何能够立足于ai界,看看这300万的“病友”如何交流
-
内裤翻过来穿,是不是代表世界都在内裤之中
-
智商很弱叫弱智,那智商很牛是不是叫牛智呢?
-
明明是我们走向死亡的道路,却被叫做人生
-
一个半小时,是不是三个半小时?
-
梦里什么都有,穷人为什么不把现实当做梦来活?
-
如果猪肾虚,那它的腰子还补吗?

当初网友为了调戏大模型专门搜集的弱智吧问题测试集,没想到有一天也能摇身一变,成了训练集。

COIG-CQIA数据集介绍
在通识百科方面,研究人员从中文互联网上广泛收集了涵盖自然科学、人文社科等多个领域的概念解释和指导性文章。这些数据源包括了知名的中文百科网站,如百度百科和维基百科等。通过解析HTML并设计多种提示模板,研究人员将原始数据转化为高质量的指令-输出对。这样的处理方式使得数据更加贴合真实场景,有助于提高人工智能系统的理解和应用能力。
在社交媒体和论坛数据方面,研究人员从知乎、小红书、豆瓣、是否等热门中文社区精心挑选了高质量的问答和长文本内容。针对这些社区的特点,研究人员分别采取了筛选高赞回答、评分过滤、人工审核等方式,以确保所保留的数据具有高质量且符合真实场景。
此外,研究人员还从其他种类的数据源中收集了STEM(科学、技术、工程和数学)领域的数据,以及人文领域的数据。这些数据源包括问答社区、内容创作平台、考试题库等。通过综合多个领域的数据,研究人员能够为人工智能系统提供更全面的知识背景和应用场景。
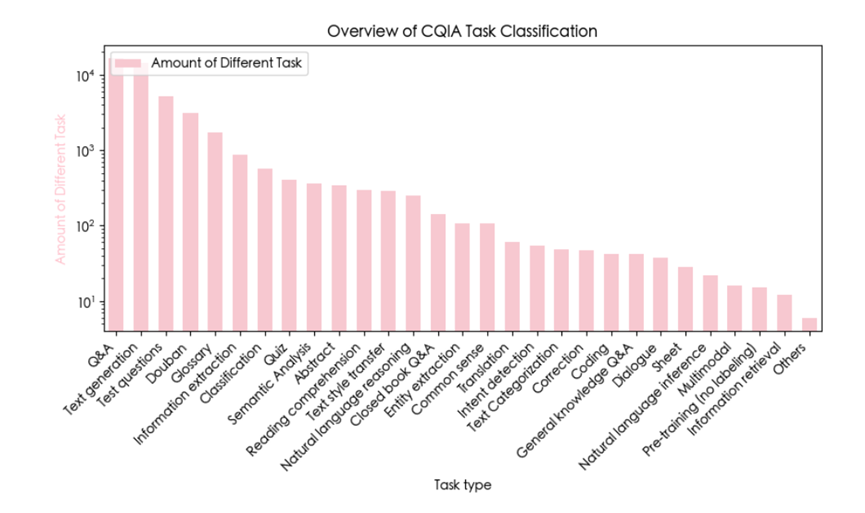
专业知识部分的采集工作涉及了金融、电子、医学、农业等专业垂直网站。研究人员从这些网站中提取了结构化数据,并按照人工设计的提示模板构造出专业性指令-输出对。这样的处理方式使得数据更加贴合专业领域的真实场景,有助于提高人工智能系统在特定领域的理解和应用能力。
此外,研究人员还将国内中学生、研究生的历年入学考试真题纳入了数据集中。这些真题涵盖了各个学科领域,能够显著提升模型的逻辑推理和知识综合能力。通过将这些真题纳入数据集,人工智能系统可以更好地理解和应对各种学科领域的知识和问题。
在完成数据收集和分类整理后,研究人员对每一类数据进行深度清洗、重构和人工审查,以确保数据质量、多样性和对真实人机交互的贴合度。
包括格式规范、答案审查、无关内容删除等。最终,精心构建了一个包含48,375条指令-输出对的高质量中文指令微调数据集。
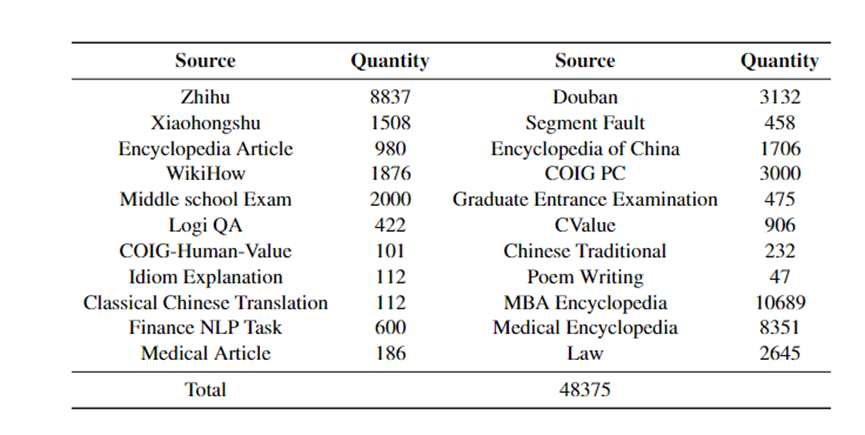
为了测试数据集性能,用COIG-CQIA对Yi系列、Qwen-72B等国内知名模型进行了微调,结果显示,COIG-CQIA比现有开源中文数据集对大模型的帮助更好。