Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集群管理器)。
下面介绍Local模式(单机模式)、跟Spark On Yarn模式(使用YARN作为集群管理器)的简单部署。
提前环境:已经部署好hadoop\hive\yarn等。
1、安装anaconda
清华镜像源下载地址:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择想要安装的版本下载,然后通过Linux客户端Xshell等上传到主机。
执行安装命令:
sh Anaconda3-2023.03-Linux-x86_64.sh
一路回车,输入yes即可。
安装后创建.condarc文件:
vim ~/.condarc
更换地址源:
annels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
保存后退出,创建环境:
conda create -n pyspark python=3.10
激活环境:
conda activate pyspark
anaconda3安装完成。
2、安装spark
下载上传主机指定路径
解压:
tar -zxvf spark-3.2.4-bin-hadoop3.2.tzg
软连接:
ln -s /usr/local/apps/spark-3.2.4-bin-hadoop3.2 spark
修改文件配置:
进入到spark的conf目录:
cd spark/conf/
新建环境变量配置文件spark-env.sh:
vim spark-env.sh
填入配置信息:
## 设置JAVA安装目录
JAVA_HOME=/usr/local/apps/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/usr/local/apps/hadoop/etc/hadoop
YARN_CONF_DIR=/usr/local/apps/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=2
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true";
保存退出。
由于配置日志输出路径,需要在hdfs新建日志目录:
hdfs dfs -mkdir /sparklog
配置系统环境变量:
vim /etc/profile
填入:
# 配置spark环境变量
export SPARK_HOME=/usr/local/apps/spark
export PYSPARK_PYTHON=/usr/local/apps/anaconda3/envs/pyspark/bin/python # python路径即为刚才新建的conda环境pyspark的路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
刷新使得系统环境变量生效:
source /etc/profile
再配置用户环境变量:
vim ~/.bashrc
添加:
# 配置spark环境变量
export JAVA_HOME=/usr/local/apps/jdk
export PYSPARK_PYTHON=/usr/local/apps/anaconda3/envs/pyspark/bin/python # python路径即为刚才新建的conda环境pyspark的路径
分发到其他主机重复配置即可。
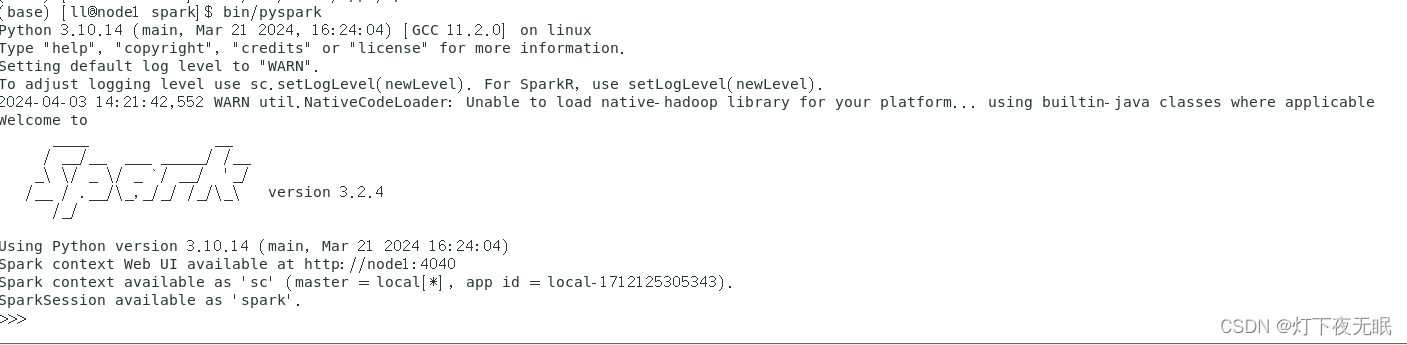
3、启动pyspark
cd到spark目录,启动pyspark:
bin/pyspark # local模式
yarn集群模式,必须先启动yarn集群:
bin/pyspark --master yarn
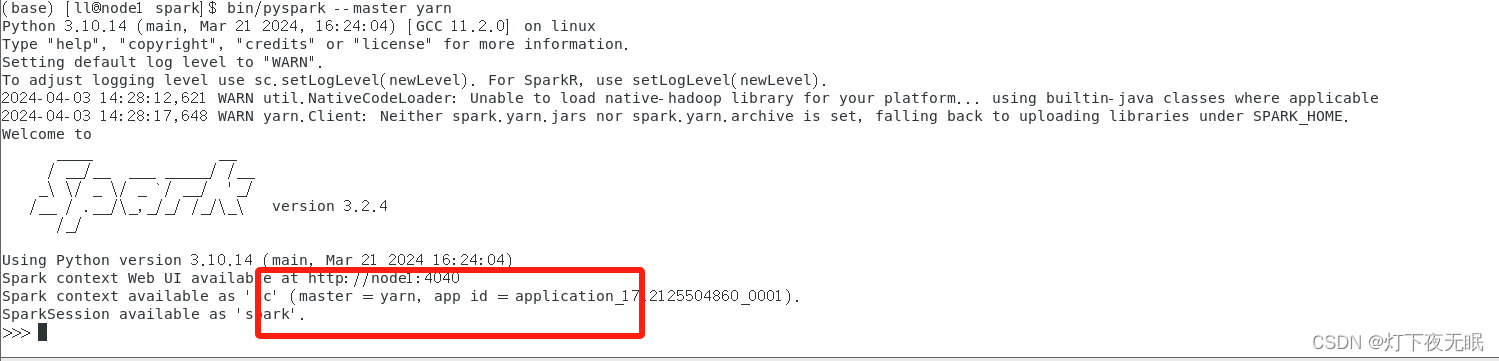
spark on local模式以及spark on yarn模式部署完成。