目录
前言
一、概述
二、Model
三、Prompt
五、Output Parsers
总结
前言
随着人工智能技术的不断进步,大模型的应用场景越来越广泛。LangChain框架作为一个创新的解决方案,专为处理大型语言模型的输入输出而设计。其中,Model IO(输入输出)模块扮演着至关重要的角色,负责构建和管理数据交互的通道。本文将深入剖析ModelIO模块的工作原理、功能特性,以及如何通过该模块提升数据处理效率,进而加速AI大模型应用的开发。
一、概述
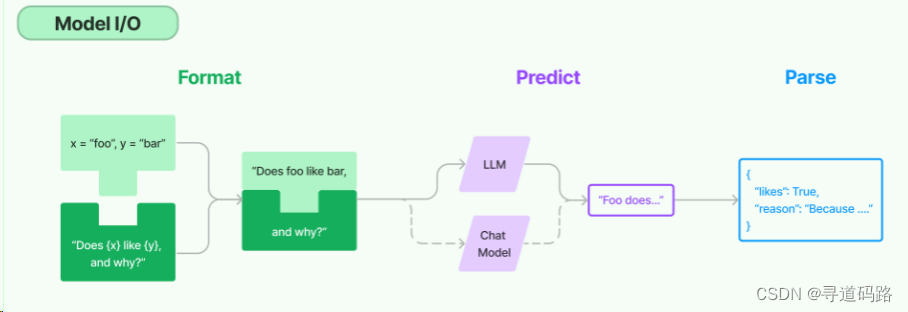
Model IO模块是LangChain框架的数据交互中枢;它不仅负责准备和处理模型的输入数据,还管理模型产出的结果。主要包括一下3部分:
- 提示词格式化(Input):接收原始输入数据到将其转换为模型可理解的格式
- 大模型调用(Model ):调用大语言模型API获得返回结果
- 结果解析处理(Output):将大语言模型返回的结果进行解析处理。
二、Model
1、LLMs
LLMs是LangChain 的核心组件,但LangChain并不提供自己的LLMs,它主要允许开发者使用统一的方式与不同的大型语言模型进行交互。这包括与OpenAI、Cohere、Hugging Face等流行的LLMs服务进行接口对接。(类似于Completion,属于文本生成类模型API的支持)
from langchain_openai import OpenAI
llm = OpenAI()
llm.invoke("奥巴马当了几年总统?")2、Chat Model
对于需要复杂对话管理能力的应用,LangChain框架提供了ChatModels模块。这个模块利用特殊的语言模型变体,优化了聊天场景下的信息交换和处理流程。(类似于Chat Completion,属于聊天会话类模型API的支持)
from langchain_openai import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-3.5-turbo-0125")
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage
)
# 设置模型角色,同时设置样例
messages = [SystemMessage(content="你是一个智能助手"),
HumanMessage(content="第二十一届世界杯在哪儿举行的?"),
AIMessage(content="在俄罗斯"),
HumanMessage(content="冠军是哪个球队")]
# chat_model.invoke(messages)
chat_model.invoke(messages).content三、Prompt
通过Prompts模块提供了灵活的提示词模板和处理机制,允许用户高效地定义和格式化这些提示,以便与LLMs进行有效的交互。
1、Prompt Template
用于创建动态的提示词模板,可以基于一定规则插入变量。例如:
## 可以动态传入参数
from langchain.prompts import PromptTemplate
# 定义提示词模板
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 传入参数,格式化提示词模板
prompt_template.format(adjective="funny", content="chickens")
## 也可以不传参数
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke")
prompt_template.format()2、ChatPromptTemplate
专门用于支持聊天场景,模拟多轮对话中的上下文交换。例如:
from langchain.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
chat_model.invoke(messages)3、Few-shot prompt templates
利用有限示例来丰富大型语言模型(LLMs)的知识基础,并指导其推理过程。向模型提供针对性的样本集合,这些样本作为参考点,有效地提升模型在处理新颖问题时的逻辑推理能力和答案生成的精确度;同时还增强了模型在面对未知或复杂情境下的思维连贯性和适应性。
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "富兰克林·德拉诺·罗斯福和亚伯拉罕·林肯中哪个担任总统的时间更长?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:富兰克林·德拉诺·罗斯福担任了几年总统?
中间答案:富兰克林·德拉诺·罗斯福担任了12年的总统。
后续问题:亚伯拉罕·林肯则担任了几年总统?
中间答案:亚伯拉罕·林肯则担任了5年的总统。
因此最终答案是:富兰克林·德拉诺·罗斯福
"""
},
{
"question": "百度的创始人是何时出生的?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:百度的创始人是谁?
中间答案:百度的创始人是李彦宏。
后续问题:李彦宏是什么时候出生的?
中间答案:李彦宏于1968年11月17日出生。
因此最终答案是:1968年11月17日
"""
},
{
"question": "特雷西·麦克格雷迪和姚明,谁在NBA打的赛季多?",
"answer":
"""
这里需要后续问题吗:是。
后续问题:特雷西·麦克格雷迪在NBA打了几个赛季?
中间答案:特雷西·麦克格雷迪在NBA打了9个赛季。
后续问题:姚明在NBA打了几个赛季?
中间答案:姚明在NBA打了8个赛季。
因此最终答案是:特雷西·麦克格雷迪
"""
}
]1)使用一个样本
# 定义提示词模板
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template="Question: {question}\n{answer}")
# 使用第一个样例作为参数 并输出打印
print(example_prompt.format(**examples[0]))
#输出结果
Question: 富兰克林·德拉诺·罗斯福和亚伯拉罕·林肯中哪个担任总统的时间更长?
这里需要后续问题吗:是。
后续问题:富兰克林·德拉诺·罗斯福担任了几年总统?
中间答案:富兰克林·德拉诺·罗斯福担任了12年的总统。
后续问题:亚伯拉罕·林肯则担任了几年总统?
中间答案:亚伯拉罕·林肯则担任了5年的总统。
因此最终答案是:富兰克林·德拉诺·罗斯福
2)使用所有样本
# 使用所有的样例
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt.format(input="马云比马化腾大几岁?"))
Question: 富兰克林·德拉诺·罗斯福和亚伯拉罕·林肯中哪个担任总统的时间更长?
这里需要后续问题吗:是。
后续问题:富兰克林·德拉诺·罗斯福担任了几年总统?
中间答案:富兰克林·德拉诺·罗斯福担任了12年的总统。
后续问题:亚伯拉罕·林肯则担任了几年总统?
中间答案:亚伯拉罕·林肯则担任了5年的总统。
因此最终答案是:富兰克林·德拉诺·罗斯福
Question: 百度的创始人是何时出生的?
这里需要后续问题吗:是。
后续问题:百度的创始人是谁?
中间答案:百度的创始人是李彦宏。
后续问题:李彦宏是什么时候出生的?
中间答案:李彦宏于1968年11月17日出生。
因此最终答案是:1968年11月17日
Question: 特雷西·麦克格雷迪和姚明,谁在NBA打的赛季多?
这里需要后续问题吗:是。
后续问题:特雷西·麦克格雷迪在NBA打了几个赛季?
中间答案:特雷西·麦克格雷迪在NBA打了9个赛季。
后续问题:姚明在NBA打了几个赛季?
中间答案:姚明在NBA打了8个赛季。
因此最终答案是:特雷西·麦克格雷迪
Question: 马云比马化腾大几岁?3)调用测试
llm.invoke(prompt.format(input="特朗普的爸爸的女儿的兄弟是谁?"))
'
这里需要后续问题吗:是。
后续问题:特朗普的爸爸是谁?
中间答案:特朗普的爸爸是弗雷德·特朗普。
后续问题:弗雷德·特朗普的女儿是谁?
中间答案:弗雷德·特朗普的女儿是玛丽·安娜·特朗普。
后续问题:玛丽·安娜·特朗普的兄弟是谁?
中间答案:玛丽·安娜·特朗普的兄弟是唐纳德·特朗普。
因此最终答案是:唐纳德·特朗普'五、Output Parsers
为了进一步处理和解析LLMs的输出结果,LangChain提供了一系列的Output Parsers。这些解析器能够将模型的文本输出转换为更加结构化的格式,便于后续的处理和使用。
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
model = OpenAI()
# 将输出解析为逗号分隔的列表
parser = CommaSeparatedListOutputParser()
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
## LCEL 链式表达式语言用法 (前一个的输入,作为后一个的输出)
chain = prompt | model | parser
chain.invoke({"subject": "ice cream flavors"})
输出:
['chocolate',
'vanilla',
'strawberry',
'mint chocolate chip',
'cookies and cream']总结
通过以上相关的功能模块,LangChain框架的Model IO模块为大型语言模型的数据交互提供了强大支持。其精心设计的接口和工具让开发者能够更加专注于模型的实际应用,同时简化了大模型调用数据流的管理细节。降低了大模型开发门槛,使得开发者可以便捷地实现高级的AI应用能力。
探索未知,分享所知;点击关注,码路同行,寻道人生!