(全局唯一ID的解决方案有很多种,这里主要是介绍和学习Snowflake算法)
什么是雪花算法(Snowflake)
雪花算法(Snowflake Algorithm)是由Twitter公司在2010年左右提出的一种分布式ID生成算法,主要用于生成全局唯一且趋势递增的ID。这种算法生成的ID是一个64位的长整型数字,具有很高的性能与扩展性,特别适合于分布式环境下的主键生成场景,比如数据库表主键、消息队列的Message ID等。
实现原理
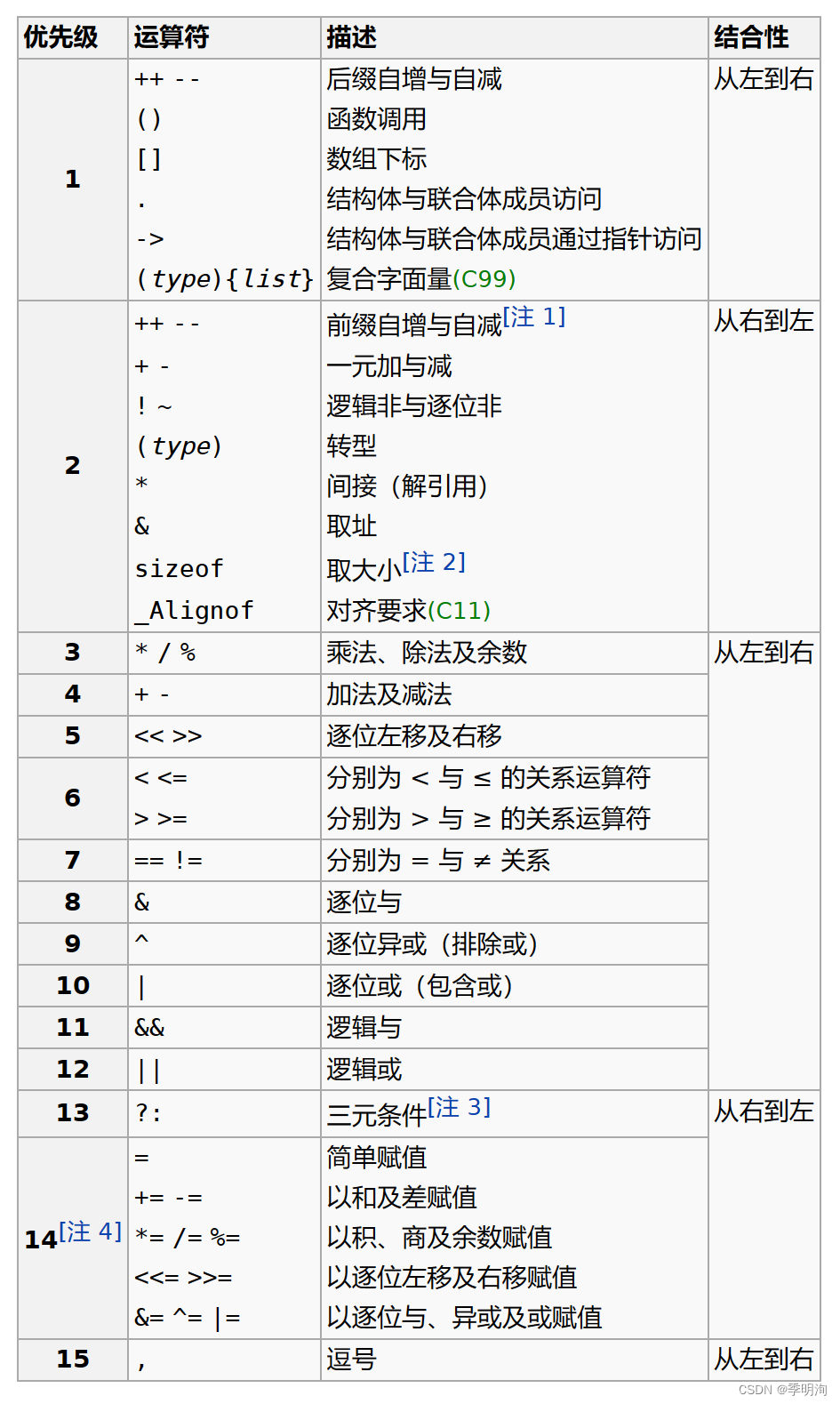
Snowflake算法的原理主要体现在它生成64位ID的结构上,主要划分为如下几个部分:
0 | 00000000000000000000000000000000000000000 | 00000 | 00000 | 000000000000
- 1bit-符号位:
第1位通常固定为0,表示生成的ID都是正数。
- 41bit-时间戳部分:
从第2位到第42位(共41位)存储时间戳信息,精确到毫秒级别。时间戳可以是自定义的一个起始时间点(如Twitter使用的是2010-11-04的某一时刻),这样可以通过比较ID中的时间戳部分来判断事件发生的先后顺序。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69。
- 10bit-工作机器ID(5bit数据中心ID+5bit机器ID):
从第43位到第52位(共10位)存储工作机器ID或者数据中心ID。这部分可以进一步细分为两部分,例如前5位标识数据中心ID,后5位标识工作节点ID。这样可以支持32(0~31)个数据中心以及每个数据中心内部的32(0~31)个工作节点,足够覆盖大规模分布式系统的节点标识。
- 12bit-序列号部分:
从第53位到第64位(共12位)存储同一节点同一毫秒内生成的序列号,这意味着同一个节点在同毫秒内可以生成最多4096个不同的ID(2^12)。
当生成ID时,首先获取当前时间戳,然后加上工作节点ID以及序列号。如果在同一毫秒内有新的请求,则序列号加1。若序列号达到最大值,则等待下一毫秒再进行分配,从而确保在同一节点内生成的ID是唯一的
雪花算法的优缺点
优点:
-
全局唯一性:雪花算法生成的ID是全局唯一的,这在分布式系统中非常重要,可以避免因ID冲突而导致的数据不一致问题。
-
递增有序:由于ID中包含时间戳部分,所以生成的ID是递增有序的。这有助于数据库插入性能的优化,因为有序的ID可以减少数据库的页分裂,提高写入效率。
-
灵活性:雪花算法允许自定义配置工作机器ID和数据中心ID的位数,可以根据实际部署环境调整这些配置,以支持不同规模的分布式系统。
-
高效性:算法本身实现简单,生成ID的速度快,能够满足高并发场景下的需求。
缺点:
-
时钟依赖:雪花算法依赖于系统时钟来生成时间戳部分。如果系统时钟出现回拨或漂移,可能会导致生成的ID不唯一或有序性受到破坏。虽然可以通过一些机制来处理时钟回拨问题,但时钟漂移仍然是一个潜在的风险。
-
机器ID冲突:如果部署的工作节点数量超过了算法中定义的机器ID位数所能表示的范围,就会发生机器ID冲突。这需要在设计系统时预先规划好机器ID的分配和管理。
-
缺乏安全性:雪花算法生成的ID本身并不包含加密或签名信息,因此容易受到恶意篡改。如果ID的安全性要求较高,需要在生成ID后添加额外的加密或签名措施。
-
扩展性限制:由于雪花算法的ID结构是固定的,因此在某些情况下可能会受到扩展性的限制。例如,如果未来需要添加更多的元数据到ID中,或者需要支持更大的分布式系统规模,可能需要重新设计ID生成算法。
因此,为了更全面地解决雪花算法的缺陷问题,可能需要采取额外的措施,例如:
-
增强时钟同步:使用NTP(Network Time Protocol)或其他时钟同步机制来确保各个节点之间的时钟尽可能准确同步。
-
增加机器ID的灵活性:设计一种更灵活的方式来分配和管理机器ID,以便支持更多的工作节点和数据中心。
-
安全性考虑:对生成的ID进行加密或签名,以防止恶意篡改。
综上所述,雪花算法在分布式系统中具有广泛的应用价值,其全局唯一性和递增有序性使得它成为生成唯一ID的优选方案之一。然而,在使用雪花算法时也需要注意其潜在的缺点,并根据实际需求进行配置和优化。
Snowflake算法生成ID的Java代码示例
以下是Snowflake算法的一个java简化版实现:
public class SnowflakeIdWorker {
// 起始的时间戳(自定义,例如系统上线时间)
private final long twepoch = 1288834974657L;
// 机器id所占的位数
private final long workerIdBits = 5L;
// 数据标识id所占的位数
private final long datacenterIdBits = 5L;
// 最大机器ID
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 最大数据标识ID
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 序列在id中占的位数
private final long sequenceBits = 12L;
// 机器ID左移12位
private final long workerIdShift = sequenceBits;
// 数据标识id左移17位(12+5)
private final long datacenterIdShift = sequenceBits + workerIdBits;
// 时间截左移22位(5+5+12)
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 序列的掩码,这里为4095 (0b111111111111=4095)
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
// 上次生成ID的时间截
private long lastTimestamp = -1L;
// 序列号
private long sequence = 0L;
// 工作机器ID
private final long workerId;
// 数据中心ID
private final long datacenterId;
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// 生成ID
public synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退,抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// 如果时间戳相同,则序列号自增
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// 序列号溢出,等待下一毫秒
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 时间戳改变,序列号重置为0
sequence = 0L;
}
// 更新最后的时间戳
lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
// 获取当前时间戳
protected long timeGen() {
return System.currentTimeMillis();
}
// 等待下一个毫秒
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1, 1);
for (int i = 0; i < 5; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}代码输出:
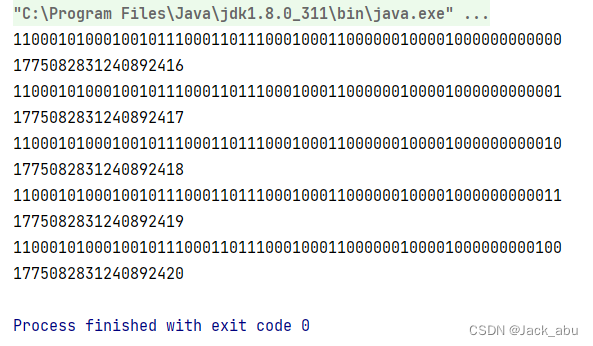
这段代码实现了雪花算法的核心逻辑。在nextId()方法中,它首先获取当前时间戳,然后检查时间戳是否小于上一次生成ID时的时间戳,如果是,则抛出异常,因为这意味着系统时钟回退,可能会导致ID生成出现混乱。如果时间戳相同,则序列号自增,并检查是否溢出,如果溢出则等待下一个毫秒。如果时间戳不同,则重置序列号。最后,将时间戳、数据中心ID、机器ID和序列号按照各自的偏移量左移,然后进行位或运算,组合成一个64位的ID。
(注:关于数据中心ID、机器ID,根据实际情况来进行配置。)