我们现在将讨论如何使用迄今为止讨论过的 DBMS 组件来执行查询。
1 查询计划【Query Plan】
我们首先来看当一个查询【Query】被解析【Parsed】后会发生什么?
当 SQL 查询被提供给数据库执行引擎,它将通过语法解析器进行检查,然后它会被转换成关系的代数表示,需要注意的是,这个代数表示是得到优化过后的。
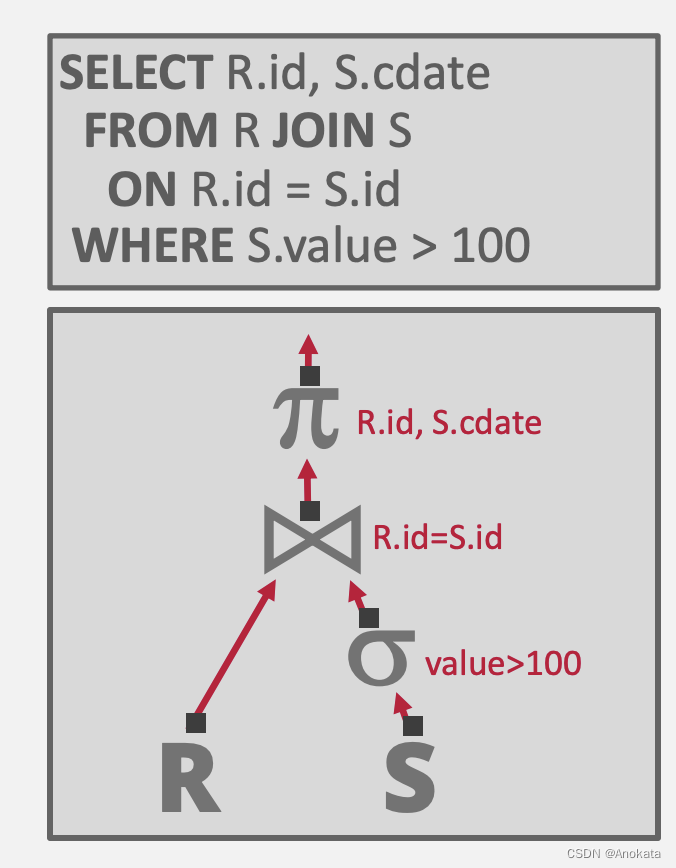
大概解释一下这棵树:
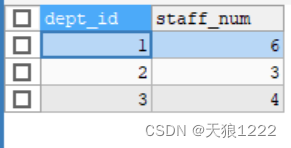
- R 和 S 是两张表,也可以说是两个关系
- 首先对 S 表做查询,条件谓词 value > 100
- 然后将 S 表与 R 表做 join ,连接的条件是 S.id = R.id
- 最后对联表生成的关系做映射,只取R.id和S.cdata两列输出的到结果中
我们得到了用树形表示的查询,树的每一个节点都是一个操作符。数据从树的叶子向上流向根,根节点的输出就是查询的结果。
那么我们想用算法对这些操作符做什么呢??
- 就像不能假设表完全可以被内存容纳下来一样,面向磁盘的 DBMS 也不能假设查询结果(设置时中间结果)可以被内存容纳。
- 我们将使用缓冲池来实现需要溢出到磁盘的算法,即内存不足以承载(中间)结果集时。
- 我们还将更喜欢能够最大化顺序 I/O 量的算法。
2 为什么我们需要排序
关系型模型【Relational model/】/SQL 是无序的【unsorted】。
但是查询【Query】可能要求元组以特定方式排序(ORDER BY)。
但即使查询没有指定顺序,我们可能仍然想要排序来做其他事情:
- 轻松支持重复消除(DISTINCT)。
- 将排序元组【sorted tuples】批量加载到 B+Tree 索引中的速度更快。
- 聚合(GROUP BY)。
3 内存排序
如果内存足以容纳数据,那么我们可以使用标准排序算法,例如快速排序。
大多数数据库系统使用快速排序进行内存排序。
在其他数据平台中,尤其是 Python,默认排序算法是 TimSort。 它是插入排序和二元归并排序的结合。 通常在真实数据上效果很好。
如果内存不足以容纳数据,那么我们需要使用一种能够感知读取和写入磁盘页面成本的技术。
4 排序算法
今天我们主要讲下面几个算法:
- Top-N 堆排序【Top-N Heap Sort】
- 外部归并排序【External Merge Sort】
- 聚合【Aggregations】
4.1 Top-N 堆排序【Top-N Heap Sort】
如果查询【Query】中包含带有 LIMIT 的 ORDER BY,则 DBMS 只需扫描数据一次即可找到前 N 个元素。
堆排序的理想场景:如果 topN 元素适合内存。
- 扫描一次数据,在内存中维护一个排序的优先级队列。
1️⃣ 我们扫描数据
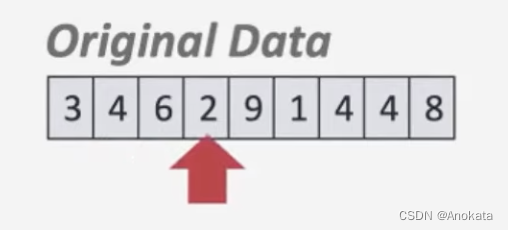
2️⃣ 并将其设置到堆排序的数组中

3️⃣ 当我们扫描到 9 时,由于我们只取最小的 4 个元素,因此9直接在内存中被跳过

4️⃣ 而碰到元素1后,他会改变我们的堆排序数组

4.2 外部归并排序
分而治之算法,将数据分成单独的 runs ,分别对它们进行排序,然后将它们组合成更长的排序了的 runs。
第 1 阶段 – 排序
- 对适合内存的数据块进行排序,然后将排序后的数据块写回到磁盘上的文件中。
第 2 阶段 – 合并
- 将排序后的 runs 合并成更大的 chunks。
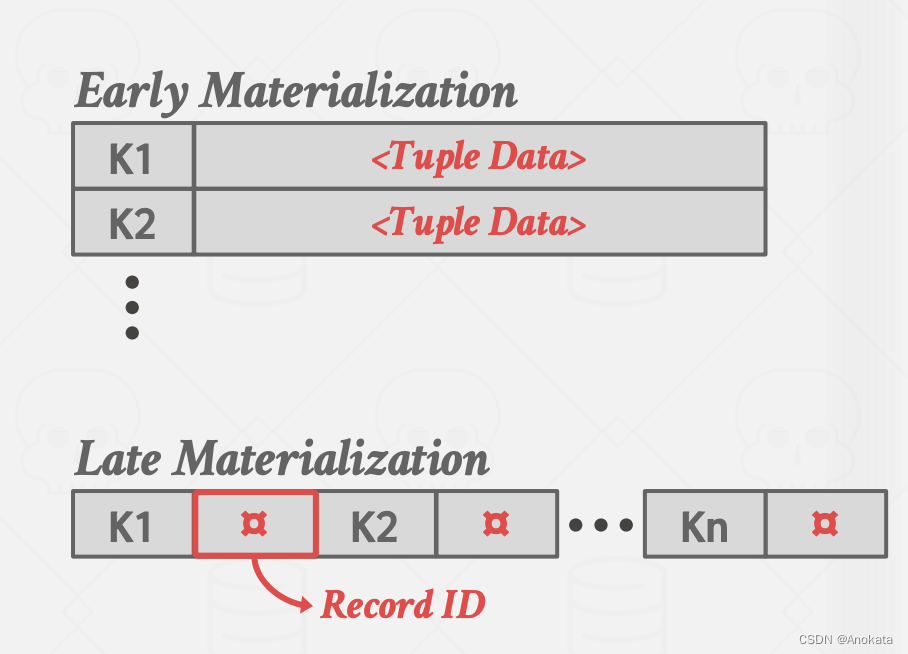
run 是键/值对的列表。
key:用于比较以计算排序顺序的属性【attribute】。
value:有两种选择
- 元组(早期的物化)。
- 记录 ID(后期的物化)。
4.2.1 2路外部归并排序
我们将从 2 路外部归并排序的简单示例开始。
- 其中,“2”是我们每次合并的 run 的数量
数据被分成 N 页。
DBMS 有有限数量的 B 个缓冲池页来保存输入和输出数据。
栗子:
我们有 N 页的数据,而 DBMS 有一个 B 页大小的缓冲池来保存输入和输出数据。
Pass 0
- 将表的所有 B 页【pages】读入内存
- 对页【page】进行排序并将其写回磁盘
Page 2,3,,,
- 递归地将一对 run 合并为两倍长的 run
- 使用三个缓冲区页面(2 个用于输入页面,1 个用于输出页面)
在每次一次传递【Pass】中,我们都要读写每一个页。
总的传递【Pass】数:= 1 + ⌈ log2 N ⌉
总的 IO 花费 = 2N · (# of passes)
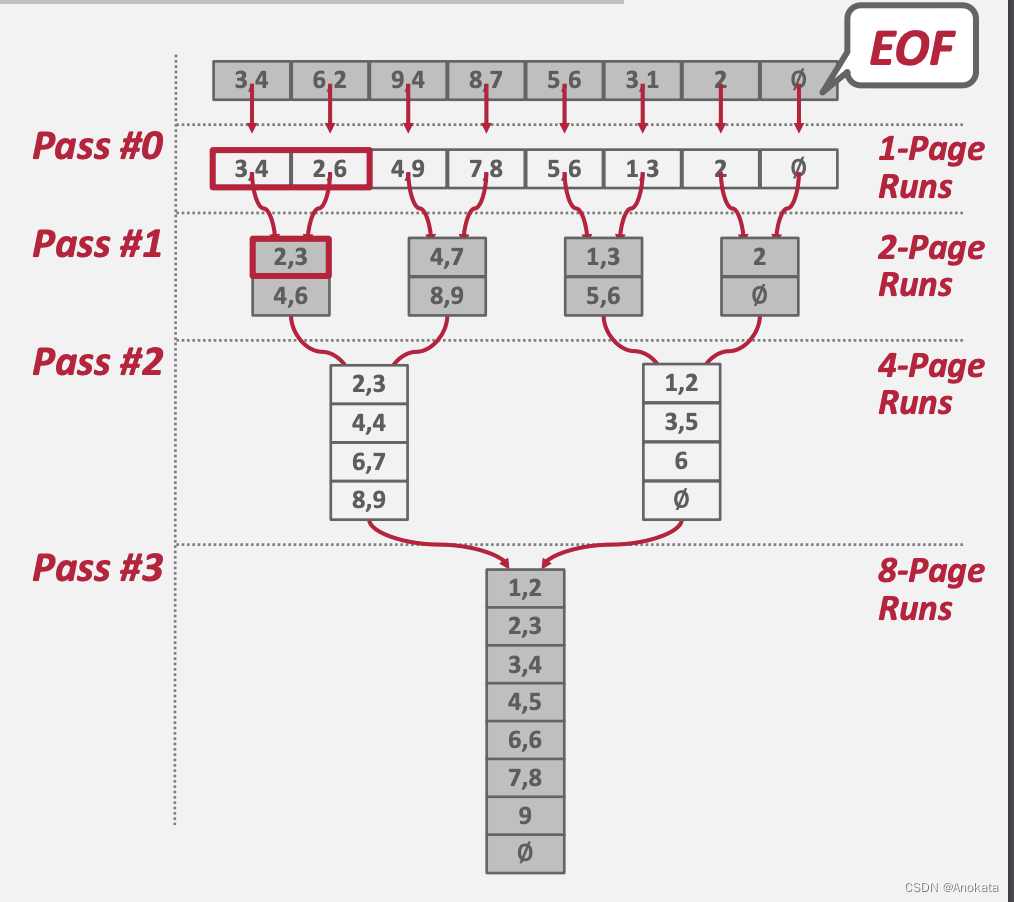
该算法仅需要三个缓冲池页面来执行排序(B=3)。
- 两个输入页面,一个输出页面
但是,即使我们有更多可用 Buffer Pool 空间 (B>3),如果工作线程【worker】必须阻塞磁盘 I/O,那么依然无法有效利用它们。
双缓存优化
当系统处理当前 run 时,在后台预取下一次的 run 并将其存储在第二个缓冲区中。通过持续利用磁盘来减少每个步骤中 I/O 请求的等待时间。
通用外部归并排序
Pass 0
- 使用 B 个 缓冲页
- 产生 ⌈N / B⌉ 个 B 大小的有序 run
Pass #1,2,3,…
- 归并 B-1 个 runs (i.e., K-way merge)
总的传递【Pass】数:= 1 + ⌈ logB-1 ⌈N / B⌉ ⌉
总的 IO 花费 = 2N · (# of passes)
栗子:
确定使用大小为 5 页的 Buffer Pool 来排序占用 108 页的数据,需要经过几次传递【Pass】?
Pass #0: ⌈N / B⌉ = ⌈108 / 5⌉ = 22 个 5 页大小的排好序的 run
Pass #1: ⌈N’ / B-1⌉ = ⌈22 / 4⌉ = 6 个 20 页大小的排好序的 run(最后一个 run 只有3页)
Pass #2: ⌈N’’ / B-1⌉ = ⌈6 / 4⌉ = 2 个排好序的 run ,第一个有 80 页大小,第二个只有 28 页
Pass #3: Sorted file of 108 pages
1+⌈ logB-1⌈N / B⌉ ⌉ = 1+⌈log4 22⌉ = 1+⌈2.229...⌉ = 4 passes
比较优化
方法1:代码特化/硬编码:不要提供比较函数作为排序算法的指针,而是创建特定于键类型的硬编码版本的排序。
方法2:后缀截断:首先比较长 VARCHAR 键【key】的二进制前缀,而不是较慢的字符串比较。 如果前缀相等,则回退到较慢的版本。
4.3 使用 B 树进行排序
如果需要排序的表在排序属性上已经有 B+Tree 索引,那么我们可以使用它来加速排序。
只需遍历树的叶节点所在的页,即可按所需的排序顺序检索元组。
需要考虑下面两种情况:
- 聚簇 B+树
- 非聚集B+树
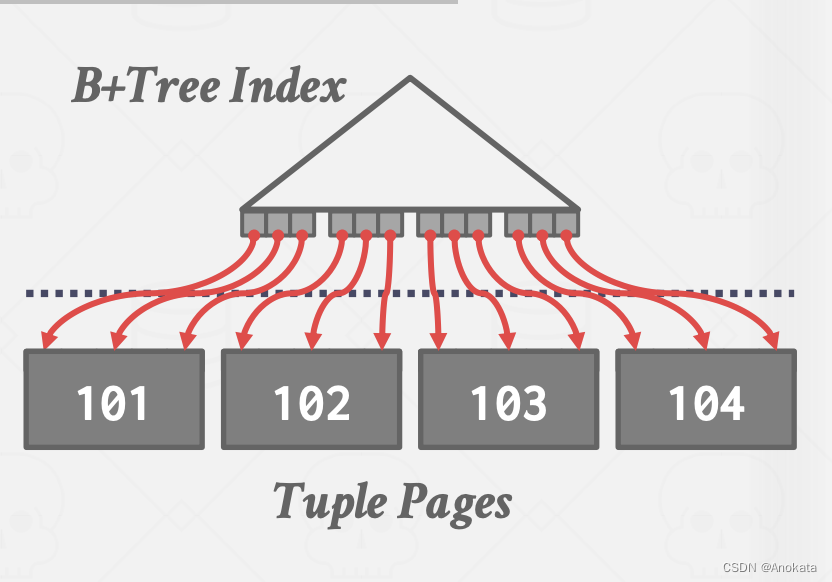
聚簇索引
遍历到最左边的叶节点的页,然后从所有叶节点的页中检索元组。
这种办法总是比外部归并排序更好,因为没有计算成本,并且所有磁盘访问都是顺序的。
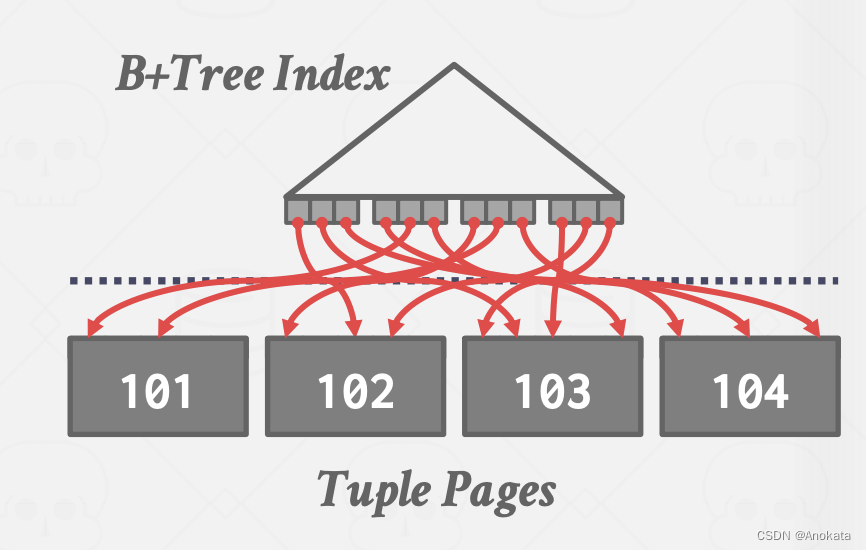
非聚簇索引
这几乎总是一个坏主意。因为在非聚簇索引种,我们需要追踪指向包含数据的页面的每个指针。
一般来说,每个数据记录一个 I/O,这是随机 IO 的灾难。
5 聚合
聚合是一种函数【function】,将多个元组中单个属性的值折叠为单个标量值【scalar value】。比如 min / max / sum / count /avg。
当我们要实现这些聚合时,我们需要找到一种方法,让DBMS系统快速找到与我们试图在其上构建聚合的属性具有相同值的元组,这样我们就可以对它们进行分组【grouping】计算我们想要的聚合函数。
两种实现选择:
- 排序
- 哈希,哈希的方案一般是要比排序更好的,尤其是当你的操盘速度很慢时(最小化IO)。
5.1 排序聚合
我们以一个栗子开始,这是我们的表:

我们要在该表上查询特定条件下不重复的 cid
SELECT DISTINCT cid
FROM enrolled
WHERE grade IN ('B','C')
ORDER BY cid
首先,我们遍历表,我们要应用 where 子句中的过滤条件,来找到所有成绩为 B 和 C 的元组
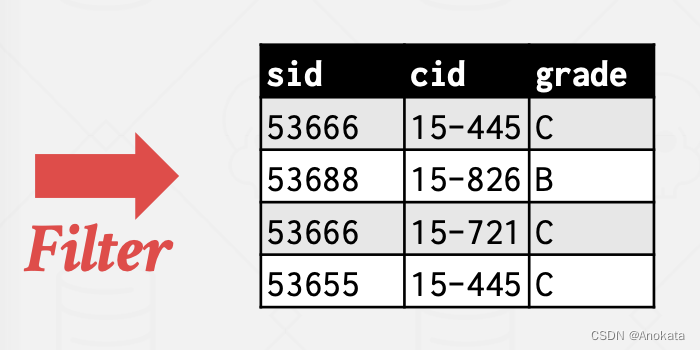
然后我们做一个映射【Projection】,因为我们不需要所有的属性,我们应用映射,只保留 cid

最后,我们对这个单列【column】进行应用排序,现在要生成最终结果,我们只需要扫描排序产生的输出,并跟踪我在光标处看到的最后一个值是什么,然后如果我遇到了和我之前看到的相同的值,那么我知道,它是重复的,我可以把它扔掉。
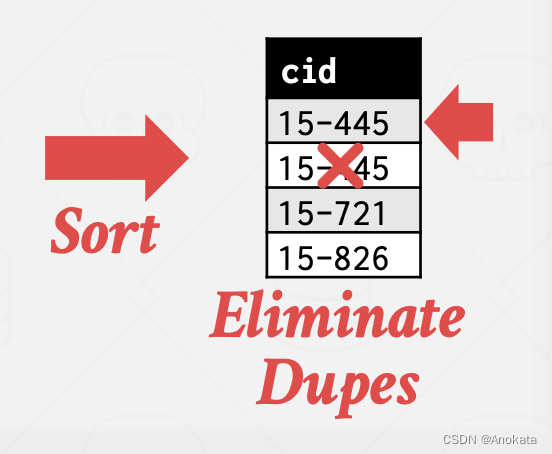
5.2 排序的替代方案
如果我们不需要数据有序的话,排序可能并不是最好的方案,那么这该怎么办?
- 在 GROUP BY 中形成组(无顺序)
- 删除 DISTINCT 中的重复项(无顺序)
在这种情况下,哈希散列是更好的选择。
- 只需要去重,无需排序。
- 计算成本比排序更便宜。
5.3 哈希聚合
当 DBMS 扫描表时填充临时哈希表。 对于每条记录,检查哈希表中是否已有条目:
- DISTINCT:丢弃重复项
- GROUP BY:执行聚合计算
如果内存足够容纳着一切数据,那么这很容易。
如果 DBMS 必须将数据溢出到磁盘,那么我们需要变得更智能一点。
外部哈希聚合【External Hashing Aggregation】
第 1 阶段 – 分区【Partition】
- 根据哈希键将元组【tuple】划分为桶【bucket】
- 当它们已满时将它们写到磁盘
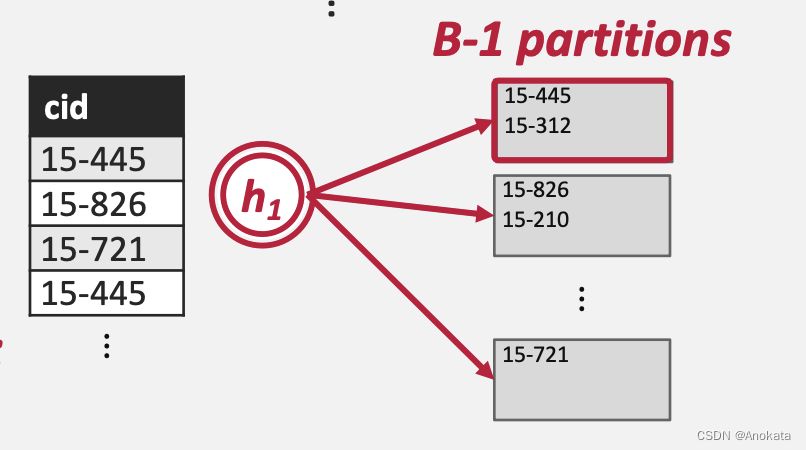
使用哈希函数 h1 将元组拆分为磁盘上的分区【Partition】。
- 分区是包含具有相同哈希值的一组键的一个或多个页面,它是一种逻辑分组
- 分区通过输出缓冲区“溢出”到磁盘
假设我们有 B 个缓冲区。 我们将使用 B-1 个缓冲区用于输出数据,即用于分区【Partition】,1 个缓冲区用于输入数据。
我们继续复用用排序聚合时的栗子:

我们首先对数据做条件过滤没然后只保留满足条件的元组:
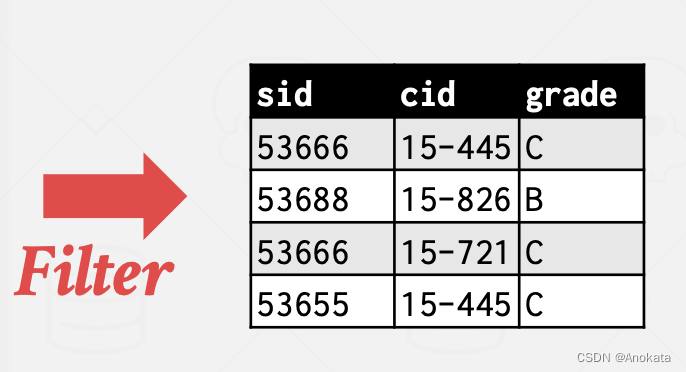
然后通过映射【Projection】删除无用的列

我们对 cid 应用哈希函数
阶段 #2 – ReHash
- 为每个分区构建内存哈希表并计算聚合
对于磁盘上的每个分区:
- 我们要将该分区的所有页面读入内存,逐一扫描它们,并基于第二个哈希函数 h2 构建内存中哈希表。
- 然后遍历该内存哈希表的每个存储桶,以将匹配的元组组合在一起。
我们这里假设每个分区都适合内存大小。
我们继续基于第一阶段产出的分区,进行第二阶段的操作:
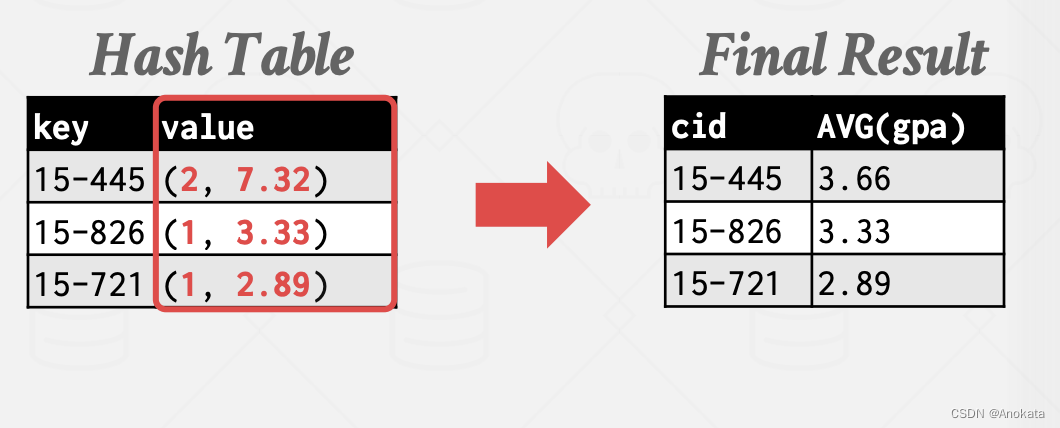
1️⃣ 首先我们对每一个分区应用哈希函数 h2,并写入专属于自己分区的哈希表中,需要注意的是,这个哈希表不是简单的原样存储,而是针对聚合函数的特定实现。
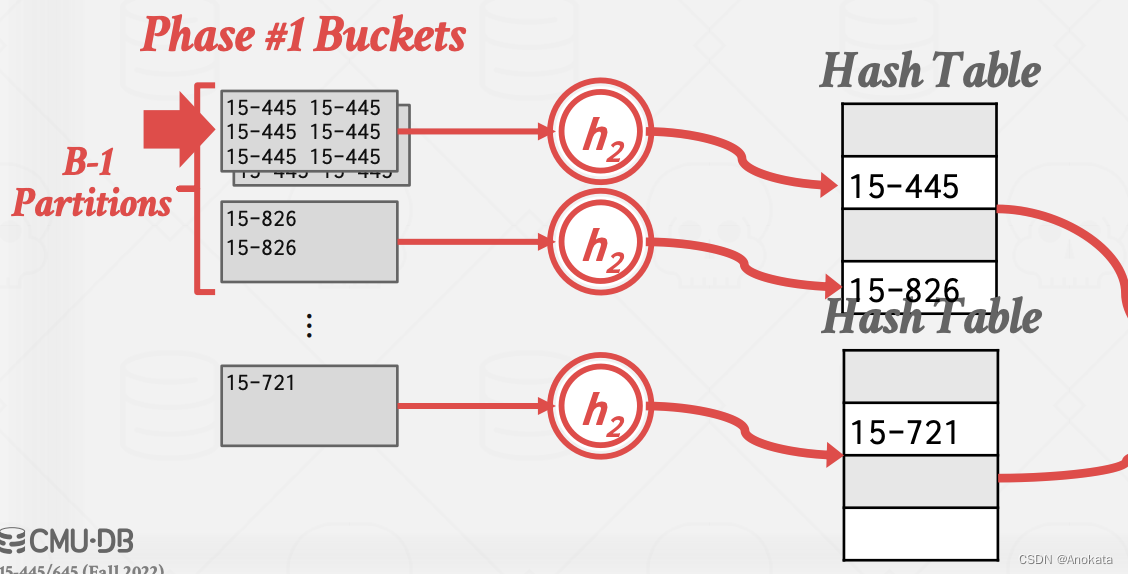
2️⃣ 在将一个分区rehash完,我们再将内存哈希表中的每一个桶中的值,写入到最终结果集中
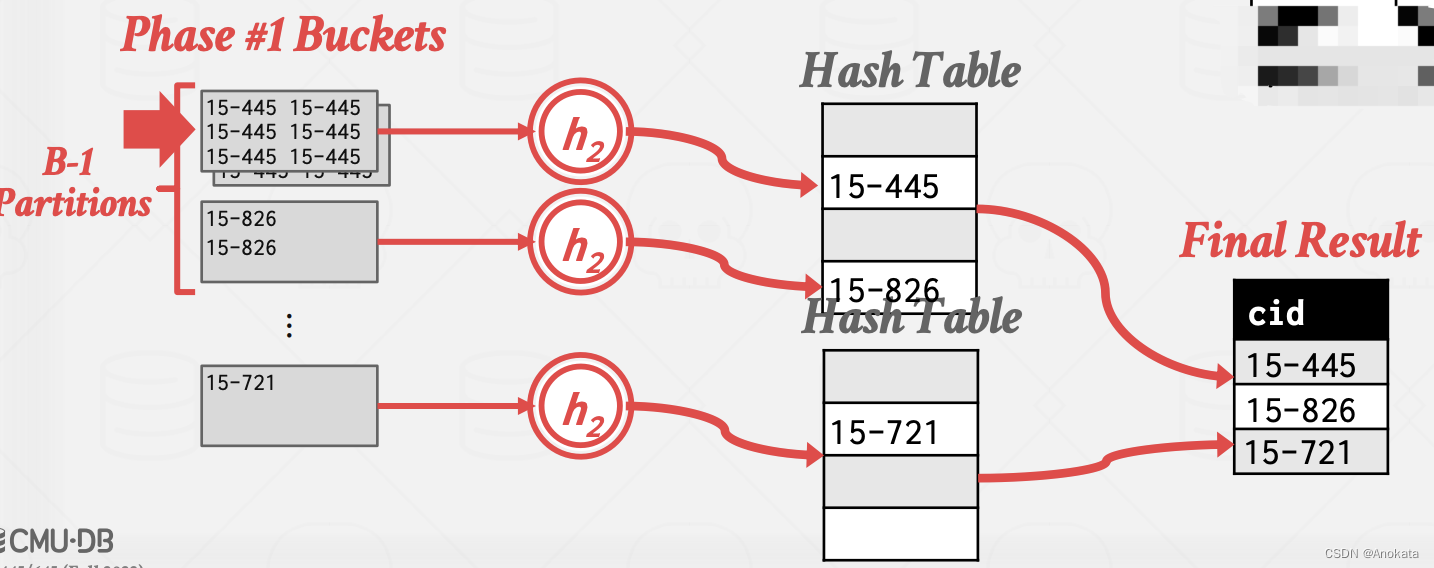
3️⃣ 在一个分区操作完之后,继续执行下一个分区,循环往复,直到所有分区都处理完。
在 ReHash 阶段,存储(GroupKey→RunningVal) 形式的序对【Pair】。
当我们想在哈希表中插入一条新的元组时:
- 如果我们找到匹配的 GroupKey,我们只需要适当的更新RunningVal
- 否则,插入一条 GroupKey→RunningVal
下面我们举个例子来解释一下,我们使用一个新的查询【Query】
SELECT cid, AVG(s.gpa)
FROM student AS s, enrolled AS e
WHERE s.sid = e.sid
GROUP BY cid
1️⃣ 我们先对数据集做分区
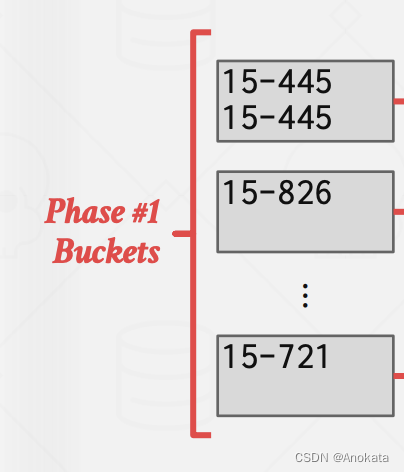
2️⃣ 然后应用哈希函数 h2 ,我们聚合函数要的是平均值,因此哈希表的值是关于聚合函数的特定值,它是数量和平均值的一个复合体
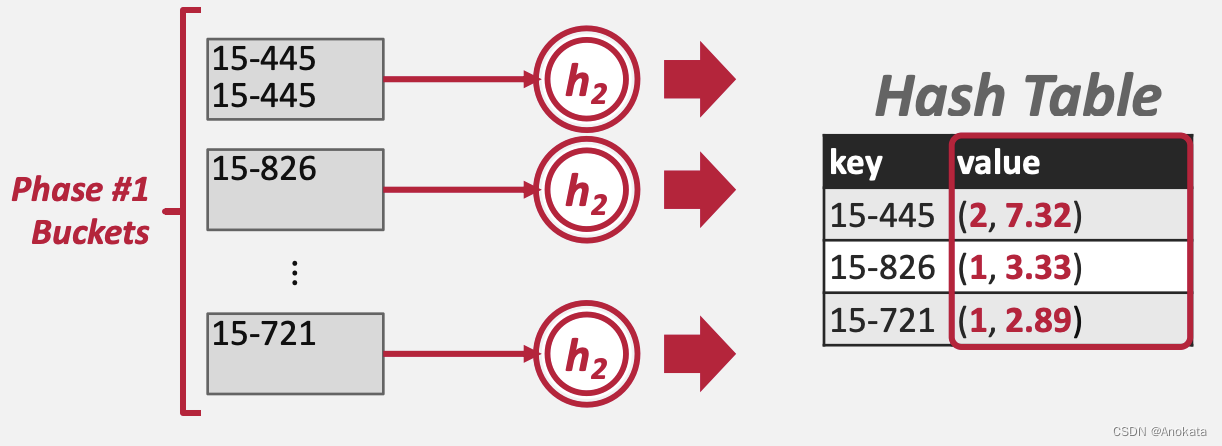 3️⃣ 在rehash完,我们将哈希表写入结果集中
3️⃣ 在rehash完,我们将哈希表写入结果集中