分布式ID生成的几种方案
分布式ID的特性
唯一性:确保生成的ID是全网唯一的;
高可用性:确保任何时候都能正确的生成ID;
UUID
算法核心思想是结合机器的网卡、当地时间、一个随机数来生成UUID;
优点:
本地生成,生成简单且性能好,没有网络消耗;
缺点:
- 不易存储:UUID长度过长,16字节128位,通常以36长度的字符串表示,很多场景不适用;
- 信息不安全:给予MAC地址生成UUID的算法可能造成MAC地址泄露;
- ID作为逐渐是在特定的环境会存在一些问题,比如DB逐渐的场景下,UUID就非常不适用;
- ① MySQL官方明确的建议逐渐要尽量越短越好,36字符长度的UUID不符合要求
- ② 对MySQL索引不利:如果作为数据库逐渐,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
数据库自增ID
使用数据库的ID自增策略,如MySQL的auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。
优点:
- 简单易用:大多数数据库都支持自增ID,使用起来非常方便,只需要在创建表的时候设置ID字段为自增即可。
- 保证唯一性:数据库自增ID可以保证在同一张表中的唯一性。
- 性能高:数据库自增ID的生成速度非常快,因为它只是简单地在上一个ID的基础上加1。
缺点:
- 不适合分布式系统:在分布式系统中,如果每个数据库节点都生成自增ID,可能会导致ID冲突。
- 无法预知ID:由于ID是在插入数据时由数据库生成的,所以在插入数据前无法知道ID的值。
- ID可能会耗尽:如果ID字段的类型设置得不合理,可能会导致ID提前耗尽。
Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像incr和increby这样的自增原子命令,所以能保证生成的ID肯定是唯一有序的;
优点:
- 适合分布式系统:Redis可以生成全局唯一的ID,适合在分布式系统中使用。
- 可以预知ID:在插入数据前,可以先从Redis中获取到ID。
缺点:
- 需要额外的服务:需要运行一个Redis服务。
- 性能可能较低:虽然Redis是内存数据库,读写速度非常快,但是由于网络通信的延迟,生成ID的速度可能会比数据库自增ID慢。
- 数据持久性问题:如果Redis服务出现故障,可能会导致ID丢失。
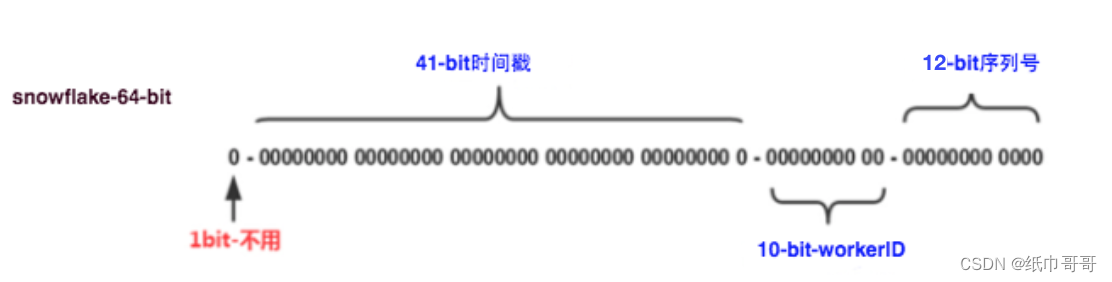
类雪花算法
这种方案大致来说是一种以为划分命名空间来生成ID的一种算法,这种方案吧64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
优点:
- 全局唯一性:在分布式系统中,雪花算法可以生成全局唯一的ID;
- 高效率:雪花算法可以在短时间内生成大量的ID;
- 无需以来数据库:与数据库自增ID相比,雪花算法不需要依赖数据库,避免了数据库的IO操作;
- ID趋势递增:雪花算法生成的ID是趋势递增的,这对于需要排序的场景非常有用。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 机器时钟回拨问题:如果服务器的系统时间回拨,可能会导致ID重复;
- ID含义暴露:由于雪花算法的ID是由时间戳、机器ID等组成,可能会暴露一些系统信息;
- 依赖机器硬件:雪花算法依赖机器ID和数据中心ID,需要在物理环境中尽显配置;
- ID可能会耗尽:如果单机的请求量过大,可能会在1毫秒内用完可以生成的ID。
参考文献:
https://tech.meituan.com/2017/04/21/mt-leaf.html