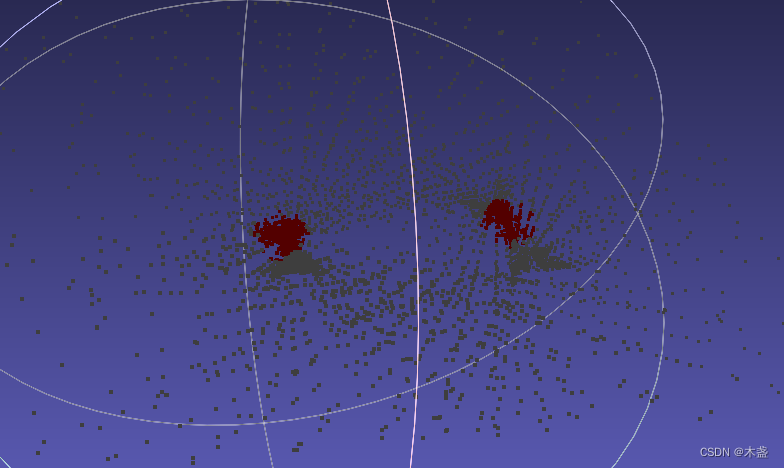
Kmeans毫无疑问,好用又“便宜”的算法,经常在很多轻量化场景中实现。所谓的“聚类”(Clustering),就是通过欧氏距离找哪些点构成一个簇。假设我们空间中有一堆点,通过肉眼大概可以看出有两簇,思考:我们怎么决定哪些点属于哪一簇,以及每簇的中心分别是什么?

那我们可以直接用sklearn的工具进行计算:
import numpy as np
from sklearn.cluster import KMeans
a = np.load("pts.npy")
kmeans = KMeans(n_clusters=2, random_state=0, n_init=2).fit(a)
print(kmeans.labels_) # each point belongs to which cluster
print(kmeans.cluster_centers_) # cluster center
根据这个简短的脚本,我们可以计算出kmeans的两个聚类中心的坐标,我们把两个中心附近的点都标成红色, 便可以看到很明显的中心效果:







![【算法每日一练]-动态规划(保姆级教程 篇17 状态压缩)](https://img-blog.csdnimg.cn/direct/9e48689b43e349078d12b357a619ba57.png)