前言
随着对视觉语言机器人研究的深入,发现Google的工作很值得深挖,比如RT-2
想到很多工作都是站在Google的肩上做产品和应用,Google真是科技进步的核心推动力,做了大量大模型的基础设施,服(推荐重点关注下Google deepmind的工作:https://deepmind.google/discover/blog/)
故有了本文,单独汇总Google在机器人领域的重大结果、进展
第一部分 RT-1:首个Transformer机器人
Google于22年年底,正式提出RT-1,其将“语言”和“视觉观察”映射到机器人动作视为一个序列建
模问题,然后使用transformer来学习这个映射
- 即Robotics Transformer 1,其项目地址:https://robotics-transformer1.github.io/,其paper地址(其v1 Submitted on 13 Dec 2022,至于v2 revised 11 Aug 2023):RT-1: Robotics Transformer for Real-World Control at Scale
- 通过将高维输入和输出(包括相机图像、指令和电机指令)编码为紧凑的token表示,供Transformer使用,可以在运行时进行高效的推理,使实时控制成为可能
which by encoding high-dimensional inputs and outputs, including camera images, instructions and motor commands into compact token representations to be used by the Transformer, allows for efficient inference at runtime to make real-time control feasible
1.1 策略学习方法上的选择:模仿学习
现在的目标是从视觉中学习机器人策略来解决语言条件任务
- 形式上,我们考虑一个顺序决策环境。在时间步长
时,策略
被提供一个语言指令
和一个初始图像观察
。 策略产生一个动作分布
,从中采样并应用于机器人的一个动作
- 这个过程持续进行,策略通过从学习的分布
中采样来迭代地产生动作
,并将这些动作应用于机器人。 交互在达到终止条件时结束
- 从起始步骤
的完整交互
被称为一个 episode。 在一个episode结束时,Agent将获得一个二进制奖励
,指示机器人是否执行了指令
至于在策略的学习上,最终使用的模仿学习方法
- 首先,可以使用Transformer来参数化策略
映射到输出序列
,使用自注意力层和全连接神经网络的组合
虽然Transformer最初是为文本序列设计的,其中每个输入和输出
表示一个文本token,但它们已经扩展到图像以及其他模态
且在使用Transformer学习映射之前,先将输入
映射到序列
- 其次,可以使用模仿学习。 模仿学习方法通过一个演示数据集D来训练策略
具体而言,我们假设可以访问一个由成功的(即最终奖励为1) N个剧集组成的数据集
我们使用行为克隆来优化π,通过最小化给定图像和语言指令时动作的负对数似然
总之,RT-1接收一系列短暂的图像和自然语言指令作为输入,并在每个时间步骤为机器人输出一个动作,为了实现这一目标

- 首先,通过ImageNet预训练的卷积网络和通过FiLM预训练的指令嵌入来处理图像和文本
- 然后通过Token Learner计算一组紧凑的token
- 最后通过Transformer对这些token进行关注并产生离散化的动作token
这些动作包括七个维度的手臂运动(x, y, z, roll, pitch, yaw, opening of the gripper),三个维度的底座运动(x, y, yaw)和一个离散维度,用于在控制手臂、底座或终止情节之间切换
最终,RT-1进行闭环控制,并以3 Hz的速率执行动作,直到它产生“终止”动作或达到预设的时间步限制
1.2 模型架构
简言之,RT-1基于transformer的基础上,将图像历史记录和任务描述作为输入,直接输出标记化的动作,接下来,按照下图中的自上而下的顺序描述模型的组成部分
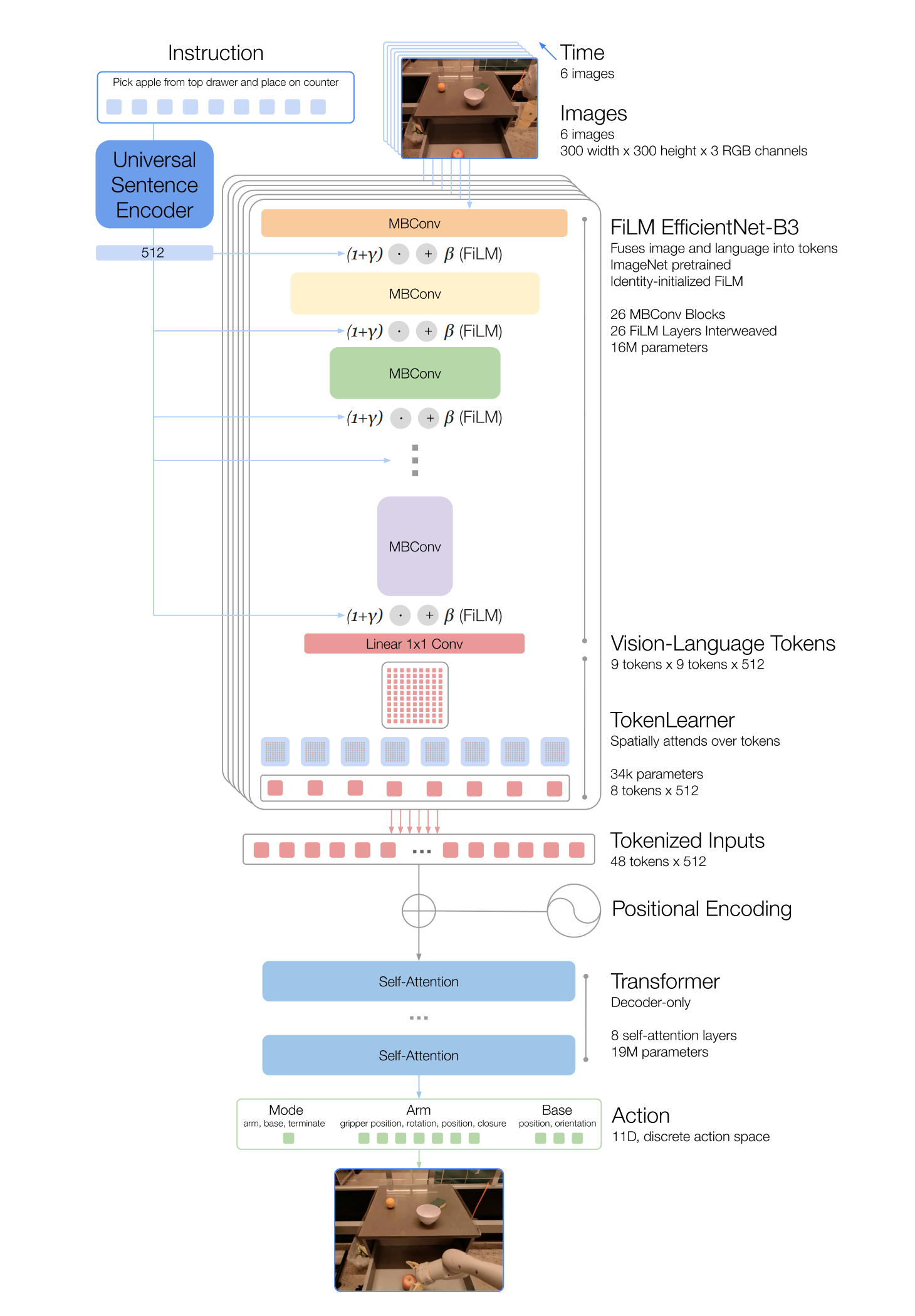
1.2.1 语言指令和图像的token化
RT-1架构依赖于对images和language instruction进行高效且紧凑的token化。 RT-1通过将images通过ImageNet预训练的EfficientNet-B3模型进行token化,将6个分辨率为300×300的图像作为输入,并从最后的卷积层输出形状为9×9×512的空间特征图(RT-1 tokenizes a history of 6 images by passingimages through an ImageNet pretrained EfficientNet-B3 (Tan & Le, 2019) model, which takes 6 images of resolution 300×300 as input and outputs a spatial feature map of shape 9×9×512 from the final convolutional layer.)
与Reed等人(2022)不同,我们不会将图像分块成视觉token,然后将其馈送到我们的Transformer主干中,相反,我们将EfficientNet的输出特征图展平为81个视觉token,然后将其传递给网络的后续,具体而言

- 为了包含语言指令(比如有的机器人模型比如Gato便不包含语言),我们将图像分词器(image tokenizer)与自然语言指令结合,以预训练的语言嵌入的形式进行条件处理,从而能够提取与任务相关的图像特征,并提高RT-1的性能
首先,通过通用句子编码器(Universal Sentence Encoder,by Cer等人,2018)对语言指令instruction进行嵌入(The instruction is first embedded via Universal Sentence Encoder)
- 通常情况下,在预训练网络的内部插入FiLM层会破坏中间激活,并抵消使用预训练权重的好处
为了克服这个问题,我们将生成FiLM仿射变换的密集层(和
)的权重初始化为零,使得FiLM层最初作为一个恒等变换,并保持预训练权重的功能
Normally, inserting a FiLM layer into the interior of a pretrained network would disrupt the intermediate activations and negate the benefit of using pretrained weights. To overcome this, we initialize the weights of the dense layers (fc and hC ) which produce the FiLM affine transformation to zero, allowing the FiLM layer to initially act as an identity and preserve the function of the pretrained weights.
我们发现,使用identity-initialized FiLM在从头开始初始化EfficientNet (没有ImageNet预训练)进行训练时,也能产生更好的结果,但并没有超过上述描述的初始化方法(We find that identity-initialized FiLM also produces better results when training with an EfficientNet initialized from scratch, without ImageNet pretraining, but it does not surpass the initialization described above)
图像分词器的架构如上图所示,最终通过FiLM EfficientNet-B3,RT-1的images和instruction tokenization总共有16M个参数,包括26层MBConv blocks和FiLM layers,输出81个vision-language tokens
1.2.2 Token Learner与Transformer解码
为了进一步压缩RT-1需要关注的token数量,从而加快推理速度,RT-1使用了Token Learner(Ryoo等,2021年)
Token Learner是一个逐元素的注意力模块,学习将大量token映射到较少的token中。 这使我们能够基于它们的信息对图像token进行软选择,仅将重要的token组合传递给后续的Transformer层
总之,TokenLearner的引入将经过预训练的FiLM-EfficientNet层输出的81个视觉token子采样到只有8个最终token,然后传递给我们的Transformer层

然后,每个图像的这8个token与历史中的其他图像连接起来,形成48个总token(且附加位置编码),以供RT-1的Transformer主干输入。Transformer是一个仅解码器的序列模型,具有8个自注意力层和19M个总参数,输出动作token
1.2.3 Action tokenization、Loss、Inference speed
为了对动作进行token化,RT-1中的每个动作维度都被离散化为256个箱子(To tokenize actions, each action dimension in RT-1 is discretized into 256 bins)
- 如前所述,我们考虑的动作维度包括七个变量,用于手臂运动(x, y, z, roll, pitch, yaw, opening of the gripper),基座的三个变量运动(x, y,偏航)和一个离散变量,用于在三种模式之间切换:控制手臂,基座或终止剧集
As mentioned previously, the action dimensions we consider include seven variables for the arm movement (x, y, z, roll, pitch, yaw, opening of the gripper), three variables for base movement (x, y, yaw) and a discrete variable to switch between three modes: controlling arm, base or terminating the episode. - 对于每个变量,我们将目标映射到256个箱子中的一个,其中箱子在每个变量的范围内均匀分布
For each variable, we map the target to one of the 256 bins, where the bins are uniformly distributed within the bounds of each variable.
此外,损失函数上,使用了先前基于Transformer的控制器(A generalist agent、Multi-game decision transformers)中使用的标准分类交叉熵熵目标和因果掩码
而推理速度上,与许多大型模型的许多应用不同,例如自然语言或图像生成,需要在真实机器人上实时运行的模型的一个独特要求是快速和一致的推理速度。考虑到执行指令的人类速度在这项工作中考虑的速度范围(我们测量为 2- 4秒),我们希望模型的速度不明显慢于此
根据我们的实验,这个要求对应于至少3Hz的控制频率,并且由于系统中的其他延迟,模型的推理时间预算要小于 100ms。这个要求限制了我们可以使用的模型的大小,最终采用了两种技术来加速推理:
- 通过使用Token-Learner(Ryoo等,2021)来减少预训练EfficientNet模型生成的令牌数量
- 仅计算这些token一次,并在未来的推理中重复使用它们。 这两种方法使我们能够将模型推理加速 2.4倍和 1.7倍
1.3 效果与不足
RT-1,使用包含超过130,000个示范的大型数据集对RT-1进行了训练,这些示范是在17个月内使用13个机器人收集的
- 证明了可以以97%的成功率执行超过700个指令,并且在任务、物体和环境的新情境中比先前发表的基准效果更好地进行泛化
- 还证明了RT-1可以成功吸收来自模拟和其他机器人形态的异构数据,而不会牺牲原始任务的性能,并且可以提高对新场景的泛化能力。
- 最后,我们展示了这种性能和泛化水平如何使我们能够在SayCan框架中执行非常长期的任务,最多可达50个步骤
虽然RT-1在数据吸收模型方面是迈向大规模机器人学习的一个有希望的步骤,但它也存在
一些限制
- 首先,它是一种模仿学习方法,继承了这类方法的挑战,比如可能无法超越示范者的表现
- 其次,对新指令的泛化仅限于先前看到的概念的组合,RT-1还不能泛化到完全没有见过的新动作
- 最后,现有的方法是在一组大型但不太灵巧的操作任务上展示的,后续计划继续扩展RT-1能够启用和泛化的指令集,以解决这一挑战
第二部分 RT-2:给VLM加上动作模态RT1,从而变成VLA
尽管之前的研究在包括机器人学在内的各种问题和设置上研究了VLMs,但Google
- 一方面,为了赋予VLMs预测机器人动作的能力,以来扩展其在机器人闭环控制中的能力,从而利用VLMs中已有的知
- 识实现新的泛化水平(While prior works study VLMs for a wide range of problems and settings including in robotics, our focus is on how the capabilities of VLMs can be extended to robotics closed-loop control by endowing them with the ability to predict robot actions, thus leveraging the knowledge already present in VLMs to enable new levels of generalizatio)
- 二方面,更为了使得模型权重可以完全共享在语言和动作任务之间,而不需要引入仅针对动作的模型层组件(we leverage VLMs that generate language, and the unified output space of our formulation enables model weights to be entirely shared across language and action tasks, without introducing action-only model layer components)
故于23年7 月,Google DeepMind宣布推出RT-1的进化版(使用上一代机器人模型RT-1的数据进行训练,数据上虽然没变,但训练方法大大增强了):RT-2(项目地址:https://robotics-transformer2.github.io/,paper地址:https://robotics-transformer2.github.io/assets/rt2.pdf)
其将视觉文本多模态大模型VLM具备的数学、推理、识别等能力和机器人比如RT-1的操作能力结合到一块了
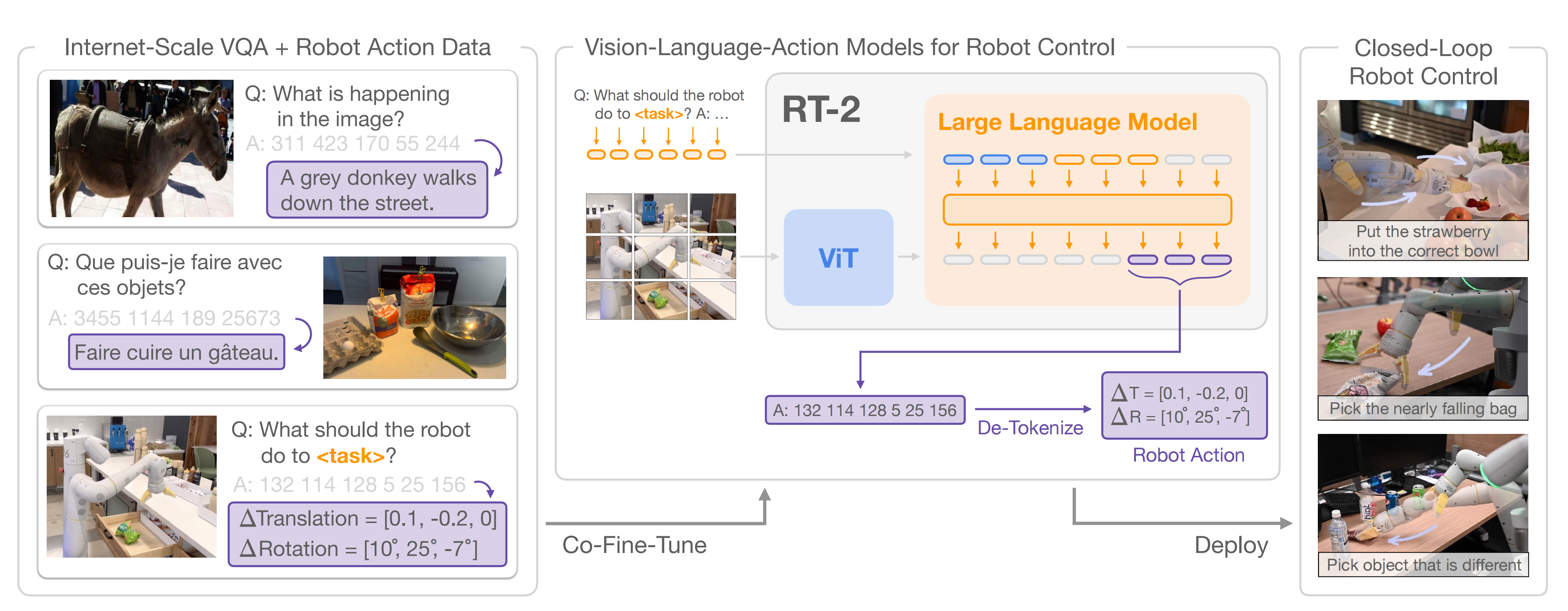
为了实现对「VLM之看听想」与「RT-1之操控」两者能力上的结合
- Google给视觉-文本大模型(VLM,比如5B和55B的PaLI-X、3B的PaLI以及12B的PaLM-E)增加了一个模态,叫做“机器人动作模态”,从而把它变成了视觉-文本-动作大模型(VLA),比如RT-2-PaLM-E和RT-2-PaLI-X
- 随后,将原本非常具体的机器人动作数据,转变成文本token,例如将转动度数、放到哪个坐标点等数据,转变成文本“放到某个位置”
这样一来,机器人数据也能被用到视觉-语言数据集中进行训练,同时在进行推理的过程中,原本的文本指令也会被重新转化为机器人数据,实现控制机器人等一系列操作
1.1 RT-2的三大能力:符号理解、推理、人类识别
其具备三大能力
- 符号理解(Symbol understanding),或者叫物体理解
能将大模型预训练的知识,直接延展到机器人此前没见过的数据上
例如机器人数据库中虽然没有“红牛”,但它能根据大模型预训练识所具备的知识中理解并掌握“红牛”的外貌,从而最终拿捏到所需物品 - 推理(Reasoning),这也是RT-2的核心优势,要求机器人掌握数学、视觉推理和多语言理解三大技能,比如


甚至能主动思考,比如给定指令「选择灭绝的动物」之后,它可以完成多个阶段的推理,从而最终抓取桌子上的塑料恐龙

- 人物识别(Human recognition)
比如只需要向对话一样下达命令:“将水递给泰勒·斯威夫特”,它就能在一堆图片中辨认出霉霉(Taylor Swift,美国当代歌手),送给她一罐可乐
1.2 VLMs for RT-2与机器人动作微调
1.2.1 VLMs for RT-2
- PaLI-X模型架构由ViT-22B组成,用于处理图像,可以接受
个图像序列,从而这
个token,其中
是每个图像的patches数量
The PaLI-X model architecture consists of a ViT-22B Dehghani et al. (2023) to process images, which can accept sequences of 𝑛 images, leading to 𝑛× 𝑘 tokens per image, where 𝑘 is the number of patches per image.
The image tokens passing over a projection layer is then consumed by an encoder-decoder backbone of 32B parameters and 50 layers, similar to UL2 Tay et al. (2023), which jointly processes text and images as embeddings to generate output tokens in an auto-regressive manner.
The text input usually consists of the type of task and any additional context (e.g., "Generate caption in h langi " for captioning tasks or "Answer in h langi : question" for VQA tasks). - PaLI-3B模型在Language-Table上训练,使用较小的ViT-G/14(2B参数)处理图像,并使用UL2-3B进行编码器-解码器网络
- PaLM-E模型基于仅解码器的LLM,将机器人数据(如图像和文本)投影到语言token空间,并输出高级计划等文本
在使用的PaLM-E-12B情况下,用于将图像投影到语言嵌入空间的视觉模型是ViT-4B。 将连续变量与文本输入进行串联,使PaLM-E能够完全多模态,接受多种输入,例如多个传感器模态,以及以对象为中心的表示,场景表示和对象实体引用
1.2.2 机器人动作微调(Robot-Action Fine-tunin)
为了使视觉-语言模型能够控制机器人,将行动表示为模型输出中的token,这些token与语言token的处理方式相同
- 行动编码基于RT-1模型提出的离散化方法
行动空间包括机器人末端执行器的6自由度位置和旋转位移,以及机器人夹持器的伸展程度和用于终止情节的特殊离散命令,该命令应由策略触发以表示成功完成 - 连续维度(除了离散终止命令之外的所有维度)均均匀地离散为256个箱子,因此,机器人行动可以使用离散箱子的序数表示为8个整数
The continuous dimensions (all dimensions except for the discrete termination command) are discretized into 256 bins uniformly. Thus, the robot action can be represented using ordinals of the discrete bins as 8 integer numb - 为了将这些离散化的行动用于将视觉-语言模型微调为视觉-语言-行动模型,我们需要将模型的现有token化与离散行动箱子相关联(we need to associate tokens from the model’s existing tokenization with the discrete action bins)。这需要保留256个token作为动作token,而选择哪些token取决于每个VLM使用的特定分词方式
- 为了定义VLM微调的目标,我们通过简单地将每个维度的动作token用空格字符连接起来,将动作向量转换为单个字符串
这样一个目标的可能实例是:“1 128 91 241 5 101 127”
再比如“指令:我饿了” 、计划:挑选rxbar巧克力、行动:1 128 124 136 121 158 111255
我们在实验中微调的两个VLMs,PaLI-X和PaLM-E,使用不同的分词方式。 对于PaLI-X模型,每个整数最多可以有一个唯一的token,因此我们只需将动作区间与表示相应整数的token相关联
对于PaLM-E模型,它没有提供这种方便的数字表示,因此我们只需覆盖最不常用的256个token来表示动作词汇。 值得注意的是,训练VLMs以覆盖现有token与动作token是symbol tuning的一种形式,在先前的工作中已经证明对VLMs非常有效
最终,通过采取上述行动表示,我们将机器人数据转换为适合于VLM模型微调的形式,其中我们的输入包括机器人摄像头图像和文本任务描述(使用标准的VQA格式“Q:机器人应该采取什么行动来完成[任务指令]?A:”),我们的输出格式为表示机器人行动的数字/最不常用的标记的字符串(and our output is formatted as a string of numbers/least frequently used tokens representing a robot action)
值得注意的是,同时使用原始的VLM训练数据和机器人数据对VLM微调,得到的效果相对最好(we use both the original VLM training data as well as robotic data for VLM fine-tuning)

此外,推理的时候用的最大模型是55B参数的RT-2-PaLI-X-55B模型,可以以1-3 Hz的频率运行,而该模型的较小版本由5B参数组成,可以以约5 Hz的频率运行
1.3 训练数据
1.3.1 PaLI-X/PaLM-E和RT-1的机器人演示数据
对于训练数据,我们利用了
- Pali-x: On scaling up a multilingual vision and language model和Palm-e: An embodied multimodal language model(一作为Driess)的原始网络规模数据,其中包括视觉问答、字幕和非结构化交织的图像和文本示例
- 然后将其与RT-1的机器人演示数据相结合(该数据在办公室厨房环境中使用13台机器人在17个月内收集而来)
每个机器人演示轨迹都用自然语言指令进行了注释,描述了执行的任务,包括描述技能的动词(例如,“拾取”,“打开”,“放入”)和描述操作对象的一个或多个名词(例如,“7up罐”,“抽屉”,“餐巾纸”)
对于RT-2训练过程中的参数设置,采用了原始PaLI-X和PaLM-E论文中的超参数,包括学习率调度和正则化
1.3.2 Q-Transformer与Open X-Embodiment 数据集
在 RT-2 之后,谷歌 DeepMind 又提出了 Q-Transformer,机器人界也有了自己的 Transformer 。Q-Transformer 使得机器人突破了对高质量的演示数据的依赖,更擅长依靠自主「思考」来积累经验
RT-2 发布仅两个月,又迎来了机器人的 ImageNet 时刻。谷歌 DeepMind 联合其他机构推出了 Open X-Embodiment 数据集,改变了以往需要针对每个任务、机器人具体定制模型的方法,将各种机器人学的知识结合起来,创造出了一种训练通用机器人的新思路。
想象一下,只需向你的机器人小助理发出「为我打扫房子」或「为我们做一顿美味健康的饭菜」等简单的要求,它们就可以完成这些工作。打扫房间或做饭这种任务,对于人类来说很简单,但对于机器人来说,可真不容易,需要它们对世界有深度理解。
第二部分 先泛化后加速最后造数据:RT-Trajectory、SARA-RT、AutoRT
Google认为,要生产出真正可进入现实世界的机器人,必须要解决两个基本挑战:
- 新任务推广能力
- 提高决策速度
本次三连发的前两项成果就主要在这两大领域作出改进,且都建立在谷歌的基础机器人模型RT之上
于是在23年年初,谷歌宣布了一系列机器人研究进展:AutoRT、SARA-RT 和 RT-Trajectory,它们能够帮助机器人更快地做出决策,更好地理解它们身处于怎样的环境,更好地指导自己完成任务
接下来,让我们回顾一下这几项重要研究
2.1 RT-Trajectory:帮助机器人泛化,使得没见过的任务也能直接做
2.1.1 RT-Trajectory创建轨迹的三种方式
人类可以直观地理解、学会如何擦桌子,但机器人却不是很懂。不过好在我们可以通过多种可能的方式将这一指令传达给它,让它作出实际的物理行动
传统上,对机械臂的训练依赖于将抽象的自然语言(擦桌子)映射到一个个特定的动作,然后让机械臂完成,例如对于擦桌子,就可以拆解为:合上夹具、向左移动、向右移动,但很明显,这种方式的泛化能力很差,从而使得模型很难推广到新任务中
说白了,模仿学习可以让机器人迅速掌握所需的技能,但泛化能力比较差,比如任务泛化,其中包括需要以新的方式组合已见的状态和动作,或者完全泛化到未见的状态或动作的情况
在此,谷歌新提出的RT-Trajectory模型(对应paper为:RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches)通过解释具体的机器人动作(即描述训练视频或草图中的机器人动作),使 RT 模型能够理解 「如何完成」任务,具体而言
- RT-Trajectory 将训练数据集中的每段视频与机器人手臂执行任务时抓手的 2D 轨迹草图叠加在一起。这些轨迹以RGB图像的形式呈现,包括路线和关键点,在机器人学习执行任务时提供低级但非常实用的提示
- 在对训练数据中未见的 41 项任务进行测试时,由 RT-Trajectory 控制的机械臂的性能比现有的 SOTA RT 模型高出一倍多:任务成功率达到 63%,而 RT-2 的成功率仅为 29%
RT-Trajectory可以用多种方式来创建轨迹,包括:
- 人工手绘的草图(这点的巨大意义在于不需要人类再亲自实际演示一遍,只需要花成百上千个任务的草图操作图即可,相比采集视频或3D图像的训练数据 更便捷)
- 通过观看人类演示,带有手物互动的人类演示视频是一种替代输入方式。从视频中估计人手姿势的轨迹,并将其转换为机器人末端执行器姿势的轨迹,后者可以用于生成轨迹草图(We estimate the trajectory of human hand poses from the video, and convert it to a trajectory of robot end-effector poses, which can later be used to generate a trajectory sketch)
- 通过VLM来生成
通过使用这个提示,LLM编写代码生成一系列3D姿势,最初是为了与运动规划器一起执行,然后我们可以重新用来在初始图像上绘制轨迹草图以条件化RT-Trajectory
如下图所示

- 在策略训练期间,我们首先进行回顾轨迹标记,以从演示数据集中获取轨迹条件标签。这使我们能够重复使用现有的演示数据集,并确保提出的方法对新数据集的可扩展性
然后,我们使用模仿学习对基于Transformer的控制策略进行训练,该策略以2D轨迹草图为条件 - 在推理时,用户或高级规划者会从机器人摄像头获得初始图像观察,并创建一个粗略的2D轨迹草图,指定所需的运动(下图左下角),然后将其输入训练好的控制策略以执行指定的操作任务
2.1.2 2D轨迹的绘制

// 待更
2.1.3 机器人动作策略的训练
模仿学习已经在在多任务机器人模仿学习环境中取得了巨大的成功。 更具体地说
- 假设可以访问一系列成功的机器人演示剧集。 每个episode
包含一系列观察
-动作
对
(Each episode τ contains a sequence of pairs of observations ot and actions at: τ ={(ot,at)}. )
- 这些观察包括从头部摄像头获取的RGB图像
和回顾轨迹草图
- 然后,我们使用Transformer来学习表示为策略 π的模型
行为克隆遵循RT-1框架,通过最小化在给定输入图像和轨迹草图下预测动作的对数似然来优化模型(by minimizing the log-likelihood of predicted actions at given the input image and trajectory sketch)
但为了支持轨迹条件,对RT-1架构进行了修改
- 轨迹草图与输入序列(6个图像的历史记录)中的每个RGB图像在特征维度上进行连接,然后通过image tokenizer(一个ImageNet预训练的EfficientNet-B3)进行处理
- 对于image tokenizer的额外输入通道,将第一个卷积层的新权重初始化为全零。 由于不使用语言指令,我们删除了原始RT-1中使用的FiLM层
最终效果如下图所示
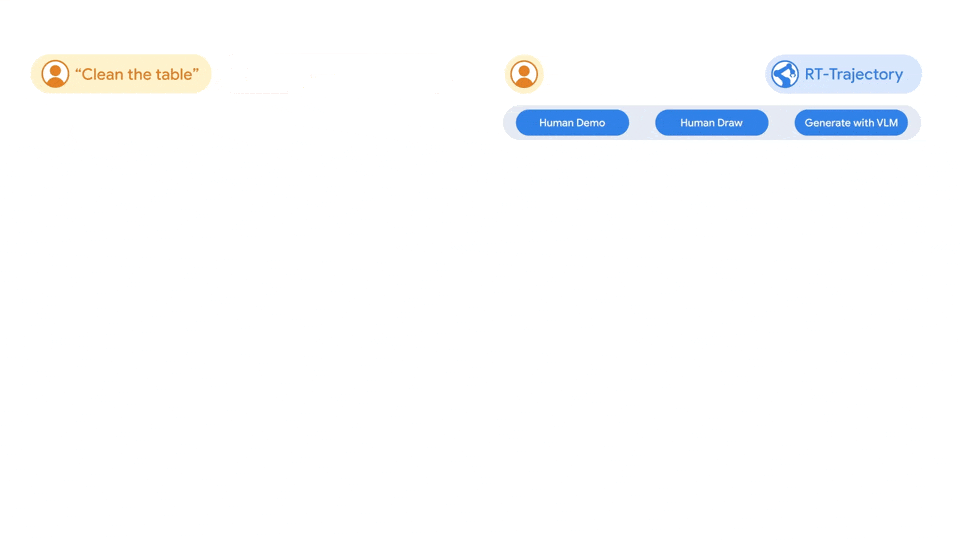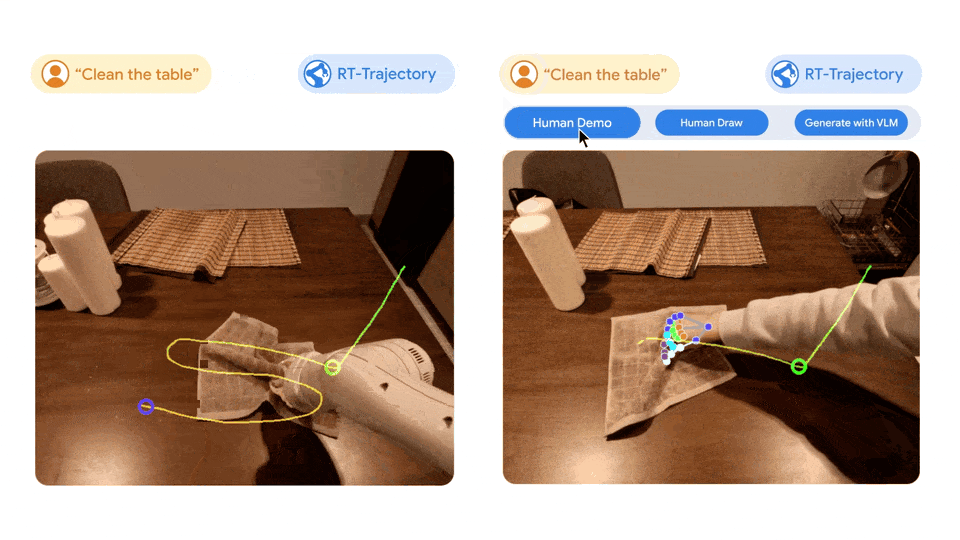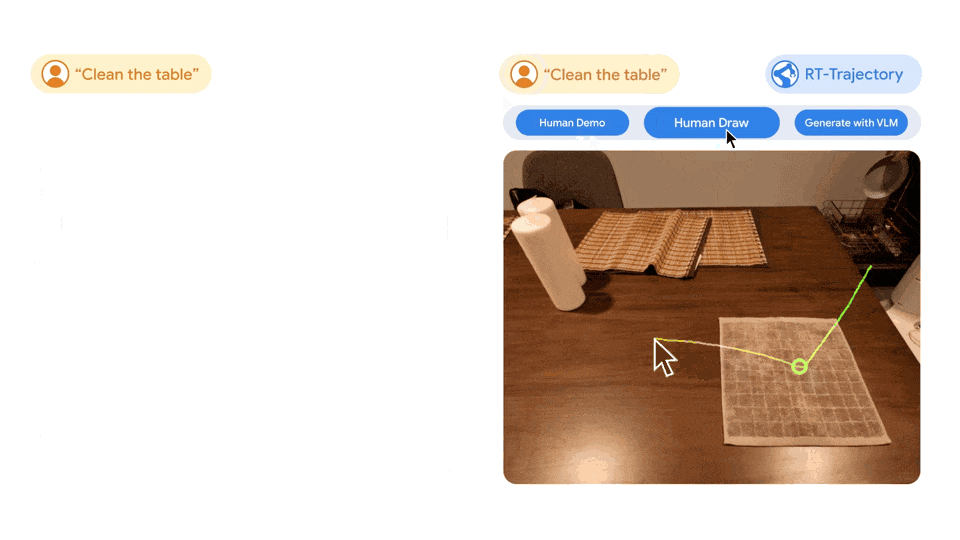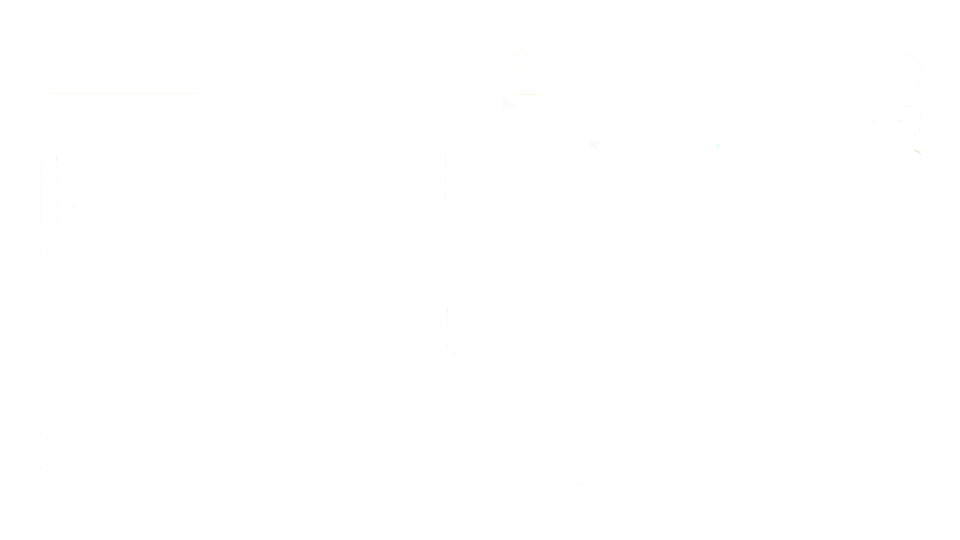
- 左图:只使用自然语言数据集训练的 RT 模型控制的机器人,在执行擦桌子这一新任务时受挫,而由 RT 轨迹模型控制的机器人,在经过 2D 轨迹增强的相同数据集训练后,成功规划并执行了擦拭轨迹
- 右图:训练有素的 RT 轨迹模型在接到新任务(擦桌子)后,可以在人类的协助下或利用视觉语言模型自行以多种方式创建 2D 轨迹
RT 轨迹利用了丰富的机器人运动信息,这些信息存在于所有机器人数据集中,但目前尚未得到充分利用。RT-Trajectory 不仅代表着在制造面向新任务高效准确移动的机器人的道路上又迈进了一步,而且还能从现有数据集中发掘知识
2.2 SARA-RT:让机器人的决策速度务必更快
泛化能力上来以后,我们再来关注决策速度
虽然 Transformer 功能强大,但它们可能会受到计算需求的限制,从而减慢决策速度。因为Transformer 主要依赖于二次复杂度的注意力模块。这意味着,如果 RT 模型的输入增加一倍(例如,为机器人提供更多或更高分辨率的传感器),处理该输入所需的计算资源就会增加四倍,从而导致决策速度减慢
为了提高机器人的速度,谷歌在基础模型Robotics Transformer上开发了SARA-RT
SARA-RT使用一种新的模型微调方法让原来的RT模型变得更为高效,这种方法被谷歌称之为“向上训练”,它主要的功能就是将原来的二次复杂度转换为线性复杂度,同时保持处理质量
当 SARA-RT 应用于拥有数十亿个参数的 SOTA RT-2 模型,它能在各种机器人任务中实现更快的决策和更好的性能:

用于操纵任务的 SARA-RT-2 模型。机器人的动作以图像和文本指令为条件。
凭借其坚实的理论基础,SARA-RT 可应用于各种 Transformer 模型。例如,将 SARA-RT 应用于点云 Transformer (用于处理来自机器人深度摄像头的空间数据),其速度能够提高一倍以上
2.3 AutoRT:数据不够?自己创造! ——极大利好机器人数据的收集
在高层次上,AutoRT(对应论文为:AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents,Submitted on 23 Jan 2024)通过开放词汇表对象检测器收集数据
- 首先对场景进行理解和描述
- 然后LLM解析该描述,在给定高层目标的情况下生成明智且安全的语言目标
- 最后使用LLM确定如何执行这些目标
AutoRT采用了一个带有摄像头、机械臂和移动基座的移动机械手作为机器人平台。在此处,我们仅考虑操作数据的收集,因此导航只用于获取不同操作设置——然而值得注意的是该系统对其他机器人实现和收集模式也具有通用性
AutoRT 结合了大型基础模型(如LLM或VLM,和机器人控制模型RT-1/RT-2,创建了一个可以在新环境中部署机器人用以收集训练数据的系统。AutoRT 可以同时指导多个配备了视频摄像机和末端执行器的机器人,在各种各样环境中执行多样化的任务
2.3.1 探索阶段:导航到目标
- 第一步是对空间进行探索,并找到有趣的场景进行操作(The first stage of AutoRT is to explore the space and find interesting scenes for manipulation)
为了绘制环境,我们采用了 Chen 等人提出的自然语言地图方法,该方法利用 VLM 构建,将物体检测编码为视觉语言嵌入,相应位置
由机器人的深度传感器和 SLAM 确定
Tomap the environment, we use the natural language map approach proposed by Chen et al. (Open-vocabulary queryable scene representations for real world planning),which is built using a VLM to encode object detections into visual-language embeddings φi, with corresponding position (xi,yi,zi) determined by the robot’s depth sensor and SLAM.
因此,给定一个类似于“海绵”的文本目标,我们可以通过查询接近
Thus, givena textual target q like “sponge”, we can direct the robot towards a sponge by querying for a φithat is close to the text embedding for q. - 为了确定导航目标,在感兴趣区域中采样状态时,我们根据之前看到对象的平均嵌入与潜在距离成比例进行采样
To determine navigation goals we sample this map forregions of interest via sampling states proportional to their latent distance to an average embeddingof previously seen objects (see Appendix B for more details)
每个环境只生成一次该地图,并复制到所有收集机器人所在空间中,并从缓存中加载以节省未来情节时间
For each environment, this map isgenerated once, then copied to all robots collecting in the space and loaded from cache to save timein future episodes.
总之,机器人先在环境中进行探索(场景和物体由VLM描述),然后随机选择导航目标并靠近物体(并提供LLM文本作为机器人生成操纵任务的依据),最终机器人能有效执行任务,且对结果进行评分,并重复该过程,这种方法不需要事先了解环境布局或其中包含的物体
具体来说
- 每个机器人将根据 AutoRT,使用视觉语言模型VLM来「看看四周」,了解其环境和视线内的物体
- 接下来,大型语言模型会为其提出一系列创造性任务,例如「将零食放在桌子上」,并扮演决策者的角色,为机器人选择需要执行的任务
下图图呈现了 AutoRT 系统的运作过程(绿色部分是本工作的贡献):
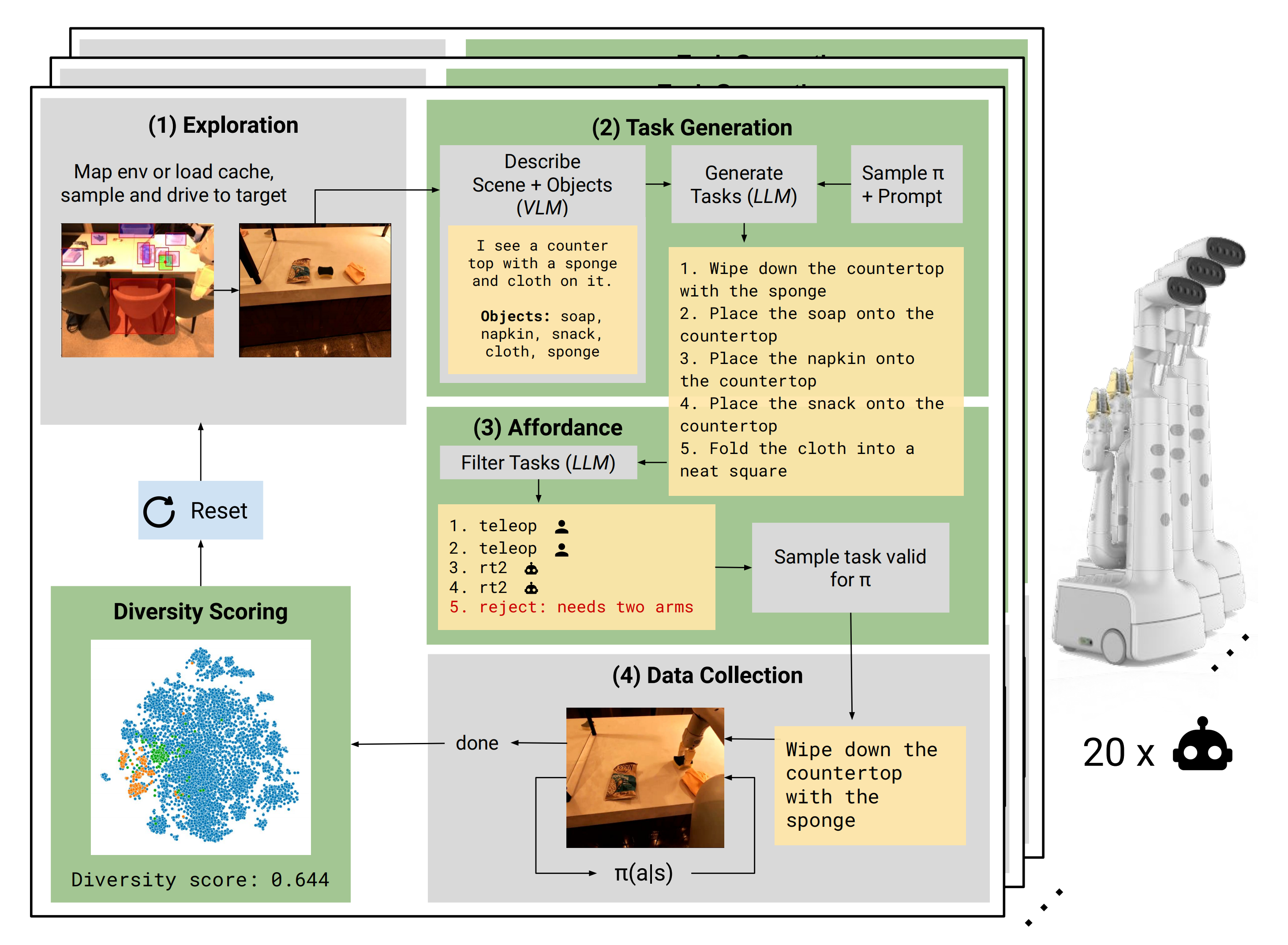
- 自主轮式机器人找到了一个有多个物体的位置
- VLM 向 LLM 描述场景和物体
- LLM 为机器人提出各种操作任务,并决定哪些任务机器人可以独立完成,哪些任务需要人类远程控制,哪些任务不可能完成,然后做出选择
- 机器人尝试选择要做的任务,收集实验数据,并对数据的多样性和新鲜度进行评分
机器人将不断重复这个过程
2.3.2 任务列表的生成
在机器人操作场景之前,需要生成一个操纵任务列表。这个过程包括两个步骤:
- 场景描述:根据机器人摄像头拍摄的图像,VLM会输出文本来描述机器人观察到的场景以及其中存在的五个物体。例如,在给定场景中,VLM列出了肥皂、餐巾、零食、布和海绵
Given an image from the robot camera, a VLM outputs text describing thescene the robot observes, and 5 objects that exist in that scene. For example, as shown in Fig. 5,the VLM lists soap, napkin, snack, cloth, sponge in the given scene.
-
任务建议:在这一步中,AutoRT会提示生成任务列表。提示首先提供系统角色说明,比如“我是在办公环境中操作的机器人”,以指导LLM扮演相应角色。然后通过由机器人constitution编写的任务生成规则列表结束
Task proposal: In this step, AutoRT is prompted to generate a list of tasks. This prompt beginswith a system prompt, such as: “I am a robot operating in an office environment”, which describesthe role the LLM should play. It continues with a list of rules that should be followed for taskgeneration, codified by the robot constitution.
提示部分还可以注入之前VLM调用中得到的场景和对象描述信息。基于这些提示,LLM会生成一个潜在的操纵任务列表。值得注意的是,为了保持底层模型通用性,并没有针对我们特定用例进行LLM微调
The prompt ends with a section, where we can inject the scene and object description from the prior VLM call. Given this prompt, an LLMgenerates a list of potential manipulation tasks (see Fig. 5). We note, the LLM is not fine-tuned toour specific use case to maintain the generality the underlying model.
研究人员在现实世界中对 AutoRT 进行了长达七个月的广泛评估。实验证明,AutoRT 系统能够同时安全地协调多达 20 个机器人,最多时共能协调 52 个机器人。通过指导机器人在各种办公楼内执行各种任务,研究人员收集了涵盖 77,000 个机器人试验,6,650 个独特任务的多样化数据集
第三部分 RT-H
// 待更
参考文献与推荐阅读
- 的
- 关于RT-2的报道
机器人ChatGPT来了:大模型进现实世界,DeepMind重量级突破
谷歌AGI机器人大招!54人天团憋7个月,强泛化强推理,DeepMind和谷歌大脑合并后新成果 -
关于Google家务机器人的报道
谷歌DeepMind机器人成果三连发!两大能力全提升,数据收集系统可同时管理20个机器人,量子位
谷歌家务机器人单挑斯坦福炒虾机器人!端茶倒水逗猫,连甩三连弹开打,新智元
大模型正在重构机器人,谷歌Deepmind这样定义具身智能的未来,机器之心 - Google机器人三项成果
https://deepmind.google/discover/blog/shaping-the-future-of-advanced-robotics/ - RT-2 的后续,RT-H:https://rt-hierarchy.github.io/
对应paper为:https://arxiv.org/pdf/2403.01823.pdf - ..








![[开源] 基于transformer的时间序列预测模型python代码](https://img-blog.csdnimg.cn/direct/a9e682f5b24949579e45c1604aaa9d4d.png)