原文链接: 工作流引擎架构设计
最近开发的安全管理平台新增了很多工单申请流程需求,比如加白申请,开通申请等等。最开始的两个需求,为了方便,也没多想,就直接开发了对应的业务代码。
但随着同类需求不断增多,感觉再这样写可要累死人,于是开始了工作流引擎的开发之路。查找了一些资料之后,开发了现阶段的工作流引擎,文章后面会有介绍。
虽然现在基本上能满足日常的需求,但感觉还不够智能,还有很多的优化空间,所以正好借此机会,详细了解了一些完善的工作流引擎框架,以及在架构设计上需要注意的点,形成了这篇文章,分享给大家。
什么是工作流
先看一下维基百科对于工作流的定义:
工作流(Workflow),是对工作流程及其各操作步骤之间业务规则的抽象、概括描述。工作流建模,即将工作流程中的工作如何前后组织在一起的逻辑和规则,在计算机中以恰当的模型表达并对其实施计算。
工作流要解决的主要问题是:为实现某个业务目标,利用计算机在多个参与者之间按某种预定规则自动传递文档、信息或者任务。
简单来说,工作流就是对业务的流程化抽象。WFMC(工作流程管理联盟) 给出了工作流参考模型如下:

举一个例子,比如公司办公的 OA 系统,就存在大量的申请审批流程。而在处理这些流程时,如果每一个流程都对应一套代码,显然是不现实的,这样会造成很大程度上的代码冗余,而且开发工作量也会骤增。
这个时候就需要一个业务无关的,高度抽象和封装的引擎来统一处理。通过这个引擎,可以灵活配置工作流程,并且可以自动化的根据配置进行状态变更和流程流转,这就是工作流引擎。
简单的工作流
那么,一个工作流引擎需要支持哪些功能呢?
这个问题并没有一个标准答案,需要根据实际的业务场景和需求来分析。在这里,我通过一个工单流程的演进,从简单到复杂,循序渐进地介绍一下都需要包含哪些基础功能。
最简单流程

最简单的一个流程工单,申请人发起流程,每个节点审批人逐个审批,最终流程结束。
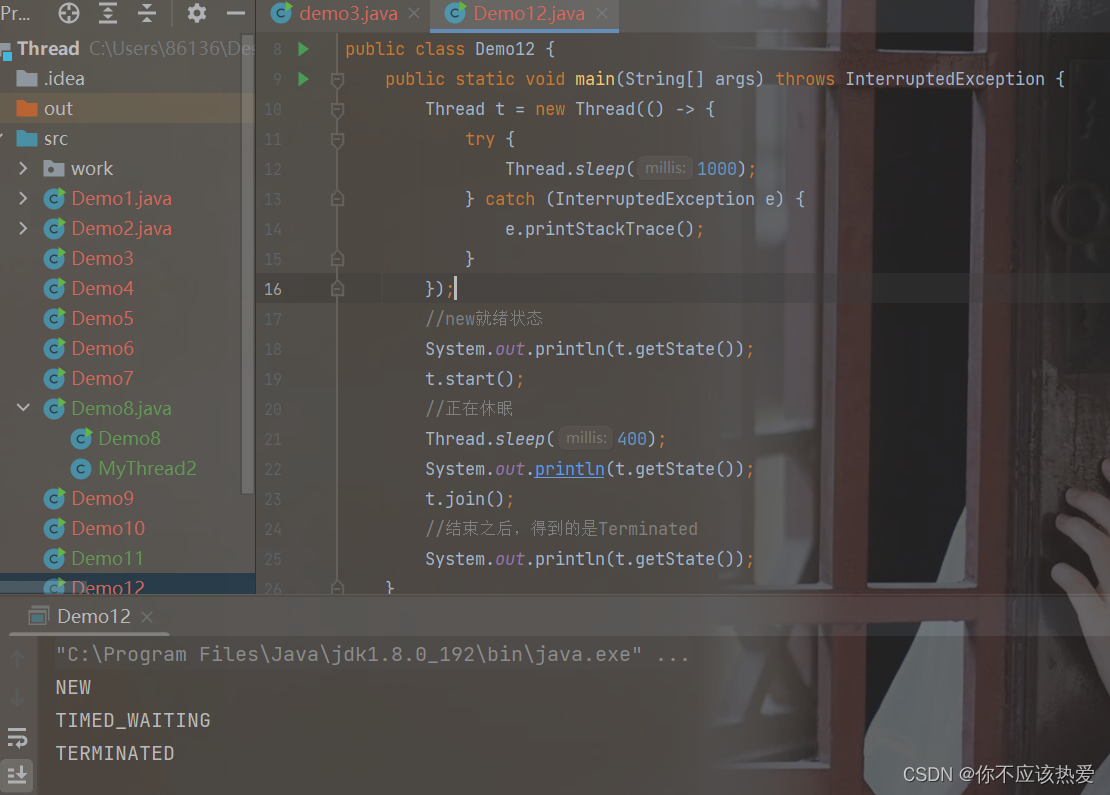
会签
在这个过程中,节点分成了两大类:简单节点和复杂节点。
简单节点处理逻辑不变,依然是处理完之后自动到下一个节点。复杂节点比如说会签节点,则不同,需要其下的所有子节点都处理完成,才能到下一个节点。
并行

同样属于复杂节点,其任何一个子节点处理完成后,都可以进入到下一个节点。
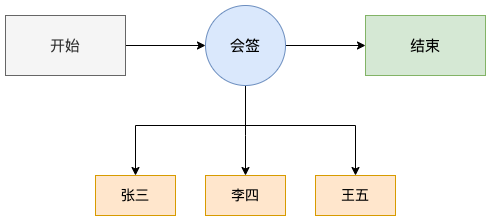
条件判断
需要根据不同的表单内容进入不同的分支流程。
举一个例子,比如在进行休假申请时,请假一天需要直属领导审批,如果大于三天则需要部门领导审批。
动态审批人

审批节点的审批人需要动态获取,并且可配置。
审批人的获取方式可以分以下几种:
- 固定审批人
- 从申请表单中获取
- 根据组织架构,动态获取
- 从配置的角色组或者权限组中获取
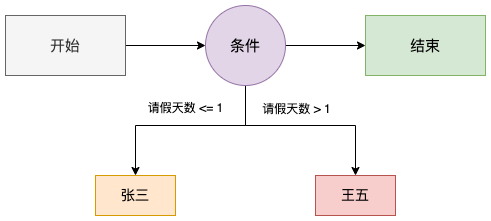
撤销和驳回
节点状态变更可以有申请人撤回,审批人同意,审批人驳回。那么在驳回时,可以直接驳回到开始节点,流程结束,也可以到上一个节点。更复杂一些,甚至可以到前面流程的任意一个节点。
自动化节点

有一些节点是不需要人工参与的,比如说联动其他系统自动处理,或者审批节点有时间限制,超时自动失效。
个性化通知
节点审批之后,可以配置不同的通知方式来通知相关人。
以上是我列举的一些比较常见的需求点,还有像加签,代理,脚本执行等功能,如果都实现的话,应该会是一个庞大的工作量。当然了,如果目标是做一个商业化产品的话,功能还是需要更丰富一些的。
但把这些常见需求点都实现的话,应该基本可以满足大部分的需求了,至少对于我们系统的工单流程来说,目前是可以满足的。
工作流引擎对比
既然这是一个常见的需求,那么需要我们自己来开发吗?市面上有开源项目可以使用吗?
答案是肯定的,目前,市场上比较有名的开源流程引擎有 Osworkflow、Jbpm、Activiti、Flowable、Camunda 等等。其中:Jbpm、Activiti、Flowable、Camunda 四个框架同宗同源,祖先都是 Jbpm4,开发者只要用过其中一个框架,基本上就会用其它三个了。
Osworkflow
Osworkflow 是一个轻量化的流程引擎,基于状态机机制,数据库表很少。Osworkflow 提供的工作流构成元素有:步骤(step)、条件(conditions)、循环(loops)、分支(spilts)、合并(joins)等,但不支持会签、跳转、退回、加签等这些操作,需要自己扩展开发,有一定难度。
如果流程比较简单,Osworkflow 是一个很不错的选择。
JBPM
JBPM 由 JBoss 公司开发,目前最高版本是 JPBM7,不过从 JBPM5 开始已经跟之前不是同一个产品了,JBPM5 的代码基础不是 JBPM4,而是从 Drools Flow 重新开始的。基于 Drools Flow 技术在国内市场上用的很少,所有不建议选择 JBPM5 以后版本。
JBPM4 诞生的比较早,后来 JBPM4 创建者 Tom Baeyens 离开 JBoss,加入 Alfresco 后很快推出了新的基于 JBPM4 的开源工作流系统 Activiti,另外 JBPM 以 hibernate 作为数据持久化 ORM 也已不是主流技术。
Activiti
Activiti 由 Alfresco 软件开发,目前最高版本 Activiti7。Activiti 的版本比较复杂,有 Activiti5、Activiti6、Activiti7 几个主流版本,选型时让人晕头转向,有必要先了解一下 Activiti 这几个版本的发展历史。
Activiti5 和 Activiti6 的核心 leader 是 Tijs Rademakers,由于团队内部分歧,在 2017 年 Tijs Rademakers 离开团队,创建了后来的 Flowable。Activiti6 以及 Activiti5 代码已经交接给了 Salaboy 团队,Activiti6 以及 Activiti5 的代码官方已经暂停维护了。
Salaboy 团队目前在开发 Activiti7 框架,Activiti7 内核使用的还是 Activiti6,并没有为引擎注入更多的新特性,只是在 Activiti 之外的上层封装了一些应用。
Flowable
Flowable 是一个使用 Java 编写的轻量级业务流程引擎,使用 Apache V2 license 协议开源。2016 年 10 月,Activiti 工作流引擎的主要开发者离开 Alfresco 公司并在 Activiti 分支基础上开启了 Flowable 开源项目。基于 Activiti v6 beta4 发布的第一个 Flowable release 版本为 6.0。
Flowable 项目中包括 BPMN(Business Process Model and Notation)引擎、CMMN(Case Management Model and Notation)引擎、DMN(Decision Model and Notation)引擎、表单引擎(Form Engine)等模块。
相对开源版,其商业版的功能会更强大。以 Flowable6.4.1 版本为分水岭,大力发展其商业版产品,开源版本维护不及时,部分功能已经不再开源版发布,比如表单生成器(表单引擎)、历史数据同步至其他数据源、ES 等。
Camunda
Camunda 基于 Activiti5,所以其保留了 PVM,最新版本 Camunda7.15,保持每年发布两个小版本的节奏,开发团队也是从 Activiti 中分裂出来的,发展轨迹与 Flowable 相似,同时也提供了商业版,不过对于一般企业应用,开源版本也足够了。
以上就是每个项目的一个大概介绍,接下来主要对比一下 Jbpm、Activiti、Flowable 和 Camunda。只看文字的话可能对它们之间的关系还不是很清楚,所以我画了一张图,可以更清晰地体现每个项目的发展轨迹。

那么,如果想要选择其中一个项目来使用的话,应该如何选择呢?我罗列了几项我比较关注的点,做了一张对比表格,如下:
| Activiti 7 | Flowable 6 | Camunda | JBPM 7 | |
|---|---|---|---|---|
| 流程协议 | BPMN2.0、XPDL、PDL | BPMN2.0、XPDL、XPDL | BPMN2.0、XPDL、XPDL | BPMN2.0 |
| 开源情况 | 开源 | 商业和开源版 | 商业和开源版 | 开源 |
| 开发基础 | JBPM4 | Activiti 5 & 6 | Activiti 5 | 版本 5 之后 Drools Flow |
| 数据库 | Oracle、SQL Server、MySQL | Oracle、SQL Server、MySQL、postgre | Oracle、SQL Server、MySQL、postgre | MySQL,postgre |
| 架构 | spring boot 2 | spring boot 1.5 | spring boot 2 | Kie |
| 运行模式 | 独立运行和内嵌 | 独立运行和内嵌 | 独立运行和内嵌 | - |
| 流程设计器 | AngularJS | AngularJS | bpmn.js | - |
| 活跃度 | 活跃 | 相对活跃 | 相对活跃 | - |
| 表数量 | 引入 25 张表 | 引入 47 张表 | 引入 19 张表 | - |
| jar 包数量 | 引入 10 个 jar | 引入 37 个 jar | 引入 15 个 jar | - |
Flowable 应用举例
如果选择使用开源项目来开发自己的引擎,或者嵌入到现有的项目中,应该如何使用呢?这里通过 Flowable 来举例说明。
使用 Flowable 可以有两种方式,分别是内嵌和独立部署方式,现在来分别说明:
内嵌模式
创建 maven 工程
先建一个普通的 maven 工程,加入 Flowable 引擎的依赖以及 h2 内嵌数据库的依赖,也可以使用 MySQL 数据库来做持久化。
<!-- https://mvnrepository.com/artifact/org.flowable/flowable-engine -->
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-engine</artifactId>
<version>6.7.2</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.192</version>
</dependency>
创建流程引擎实例
import org.flowable.engine.ProcessEngine;
import org.flowable.engine.ProcessEngineConfiguration;
import org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration;
public class HolidayRequest {
public static void main(String[] args) {
ProcessEngineConfiguration cfg = new StandaloneProcessEngineConfiguration()
.setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=-1")
.setJdbcUsername("sa")
.setJdbcPassword("")
.setJdbcDriver("org.h2.Driver")
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
ProcessEngine processEngine = cfg.buildProcessEngine();
}
}
接下来,我们就可以往这个引擎实例上部署一个流程 xml。比如,我们想建立一个员工请假流程:
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:activiti="http://activiti.org/bpmn"
typeLanguage="http://www.w3.org/2001/XMLSchema"
expressionLanguage="http://www.w3.org/1999/XPath"
targetNamespace="http://www.flowable.org/processdef">
<process id="holidayRequest" name="Holiday Request" isExecutable="true">
<startEvent id="startEvent"/>
<sequenceFlow sourceRef="startEvent" targetRef="approveTask"/>
<!-- <userTask id="approveTask" name="Approve or reject request"/>-->
<userTask id="approveTask" name="Approve or reject request" activiti:candidateGroups="managers"/>
<sequenceFlow sourceRef="approveTask" targetRef="decision"/>
<exclusiveGateway id="decision"/>
<sequenceFlow sourceRef="decision" targetRef="externalSystemCall">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${approved}
]]>
</conditionExpression>
</sequenceFlow>
<sequenceFlow sourceRef="decision" targetRef="sendRejectionMail">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${!approved}
]]>
</conditionExpression>
</sequenceFlow>
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
activiti:class="org.example.CallExternalSystemDelegate"/>
<sequenceFlow sourceRef="externalSystemCall" targetRef="holidayApprovedTask"/>
<!-- <userTask id="holidayApprovedTask" name="Holiday approved"/>-->
<userTask id="holidayApprovedTask" name="Holiday approved" activiti:assignee="${employee}"/>
<sequenceFlow sourceRef="holidayApprovedTask" targetRef="approveEnd"/>
<serviceTask id="sendRejectionMail" name="Send out rejection email"
activiti:class="org.flowable.SendRejectionMail"/>
<sequenceFlow sourceRef="sendRejectionMail" targetRef="rejectEnd"/>
<endEvent id="approveEnd"/>
<endEvent id="rejectEnd"/>
</process>
</definitions>
此 xml 是符合 bpmn2.0 规范的一种标准格式,其对应的流程图如下:
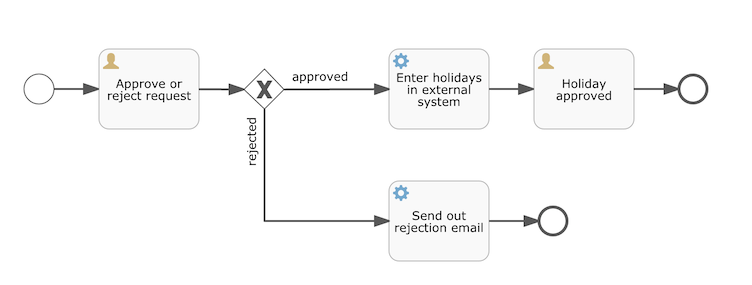
接下来,我们就把这个文件传给流程引擎,让它基于该文件,创建一个工作流。
RepositoryService repositoryService = processEngine.getRepositoryService();
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("holiday-request.bpmn20.xml")
.deploy();
创建后,实际就写到内存数据库 h2 了,我们还可以把它查出来:
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.deploymentId(deployment.getId())
.singleResult();
System.out.println("Found process definition : " + processDefinition.getName());
创建工作流实例
创建工作流实例,需要提供一些输入参数,比如我们创建的员工请假流程,参数就需要:员工姓名、请假天数、事由等。
Scanner scanner= new Scanner(System.in);
System.out.println("Who are you?");
String employee = scanner.nextLine();
System.out.println("How many holidays do you want to request?");
Integer nrOfHolidays = Integer.valueOf(scanner.nextLine());
System.out.println("Why do you need them?");
String description = scanner.nextLine();
RuntimeService runtimeService = processEngine.getRuntimeService();
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("employee", employee);
variables.put("nrOfHolidays", nrOfHolidays);
variables.put("description", description);
参数准备好后,就可以传给工作流了:
ProcessInstance processInstance =
runtimeService.startProcessInstanceByKey("holidayRequest", variables);
此时,就会根据流程定义里的:
<userTask id="approveTask" name="Approve or reject request" activiti:candidateGroups="managers"/>
创建一个任务,任务有个标签,就是 candidateGroups,这里的 managers,可以猜得出,是给 managers 建了个审批任务。
查询并审批任务
基于 manager 查询任务:
TaskService taskService = processEngine.getTaskService();
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("managers").list();
System.out.println("You have " + tasks.size() + " tasks:");
for (int i=0; i<tasks.size(); i++) {
System.out.println((i+1) + ") " + tasks.get(i).getName());
}
审批任务:
boolean approved = scanner.nextLine().toLowerCase().equals("y");
variables = new HashMap<String, Object>();
variables.put("approved", approved);
taskService.complete(task.getId(), variables);
这里就是把全局变量 approved,设为了 true,然后提交给引擎。引擎就会根据这里的变量是 true 还是 false,选择走不同分支。如下:
<sequenceFlow sourceRef="decision" targetRef="externalSystemCall">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${approved}
]]>
</conditionExpression>
</sequenceFlow>
<sequenceFlow sourceRef="decision" targetRef="sendRejectionMail">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${!approved}
]]>
</conditionExpression>
</sequenceFlow>
回调用户代码
审批后,就会进入下一个节点:
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
activiti:class="org.example.CallExternalSystemDelegate"/>
这里有个 class,就是需要我们自己实现的:

最后,流程就走完结束了。
REST API 模式
上面介绍的方式是其作为一个 jar,内嵌到我们的程序里。创建引擎实例后,由我们业务程序去驱动引擎的运行。引擎和业务代码在同一个进程里。
第二种方式,Flowable 也可以作为一个独立服务运行,提供 REST API 接口,这样的话,非 Java 语言开发的系统就也可以使用该引擎了。
这个只需要我们下载官方的 zip 包,里面有个 rest 的 war 包,可以直接放到 tomcat 里运行。
部署工作流
在这种方式下,如果要实现上面举例的员工请假流程,可以通过调接口来实现:
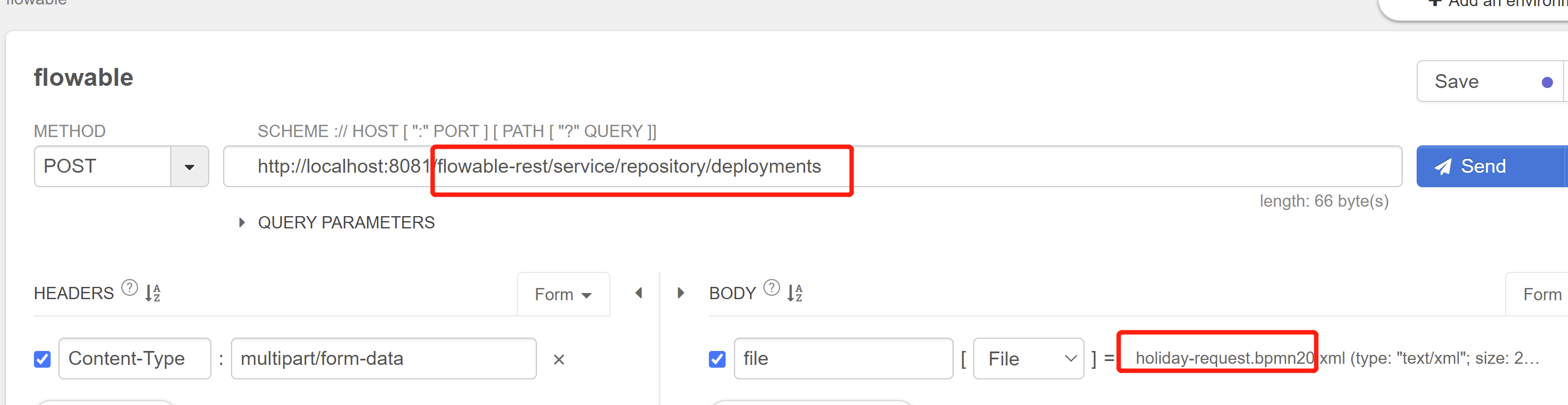
启动工作流:
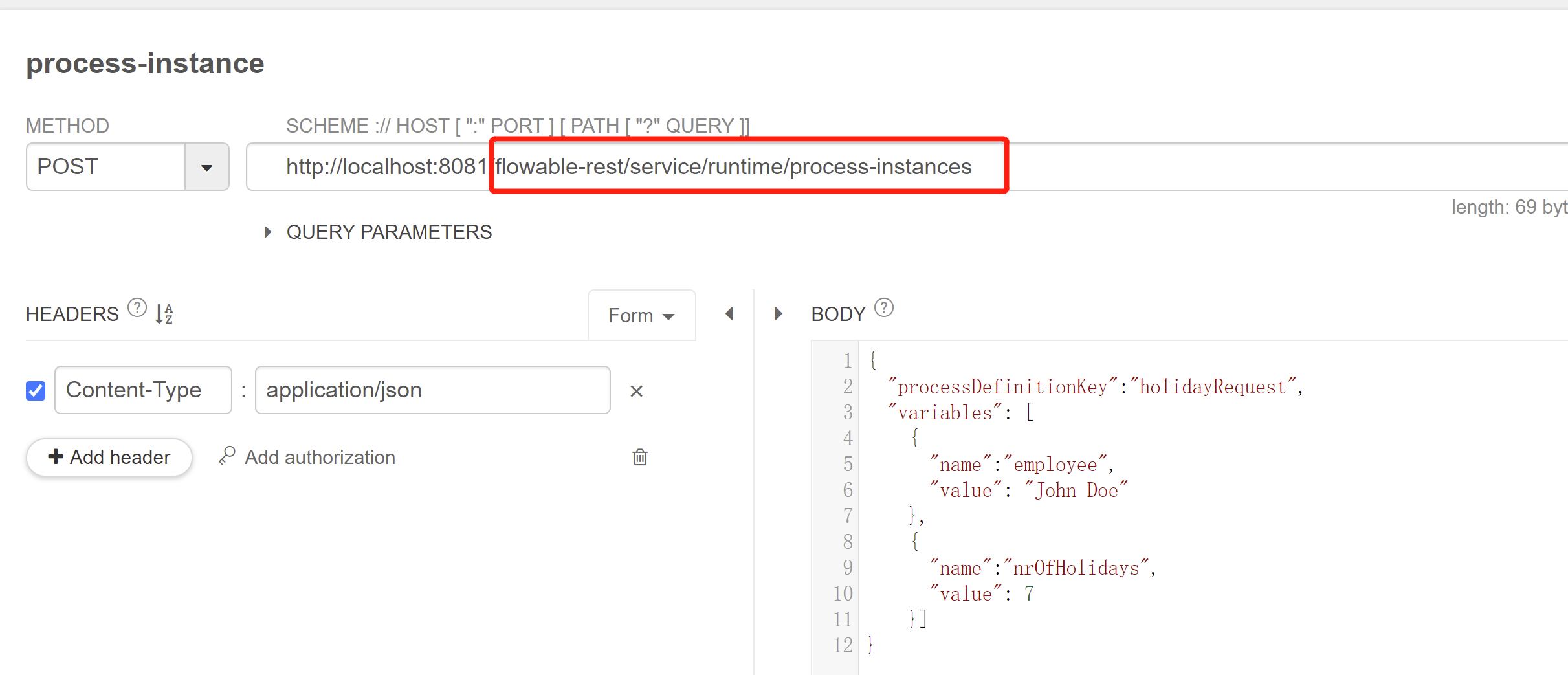
其他接口就不一一展示了,可以参考官方文档。
通过页面进行流程建模
截止到目前,创建工作流程都是通过建立 xml 来实现的,这样还是非常不方便的。因此,系统也提供了通过页面可视化的方式来创建流程,使用鼠标拖拽相应组件即可完成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6GWGHwd4-1673498086176)(null)]
但是体验下来还是比较辛苦的,功能很多,名词更多,有很多都不知道是什么意思,只能不断尝试来理解。
开源 VS 自研
既然已经有成熟的开源产品了,还需要自研吗?这算是一个老生常谈的问题了。那到底应该如何选择呢?其实并不困难,归根结底就是要符合自身的业务特点,以及实际的需求。
开源优势:
入门门槛低,有很多可以复用的成果。通常而言,功能比较丰富,周边生态也比较完善,投入产出比比较高。一句话总结,投入少,见效快。
开源劣势:
内核不容易掌控,门槛较高,通常开源的功能和实际业务并不会完全匹配,很多开源产品开箱即用做的不够好,需要大量调优。一句话总结,入门容易掌控难。
自研优势:
产品核心技术掌控程度高,可以更好的贴着业务需求做,可以定制的更好,基于上述两点,通常更容易做到良好的性能表现。一句话总结,量身定制。
自研劣势:
投入产出比略低,且对团队成员的能力曲线要求较高。此外封闭的生态会导致周边支持缺乏,当需要一些新需求时,往往都需要定制开发。一句话总结,啥事都要靠自己。
基于以上的分析,再结合我们自身业务,我总结了以下几点可供参考:
- 开源项目均为 Java 技术栈,而我们使用 Python 和 Go 比较多,技术栈不匹配
- 开源项目功能丰富,而我们业务相对简单,使用起来比较重
- 开源项目并非开箱即用,需要结合业务特点做定制开发,学习成本和维护成本比较高
综上所述,我觉得自研更适合我们现阶段的产品特点。
工作流引擎架构设计
如果选择自研,架构应该如何设计呢?有哪些比较重要的模块和需要注意的点呢?下面来详细说说。
BPMN
BPMN 全称是 Business Process Model And Notation,即业务流程模型和符号。

可以理解成一种规范,在这个规范里,哪些地方用空心圆,哪些地方用矩形,哪些地方用菱形,都是有明确定义的。
也就是说,只要是基于这个规范开发的系统,其所创建的流程就都是可以通用的。
其实,如果只是开发一个内部系统,不遵守这个规范也没有问题。但要是做一个产品的话,为了通用性更强,最好还是遵守这个规范。
流程设计器
对于工作流引擎来说,流程设计器的选型至关重要,它提供了可视化的流程编排能力,决定了用户体验的好坏。
目前主流的流程设计器有 Activiti-Modeler,mxGraph,bpmn-js 等,下面来做一个简单介绍。
Activiti-Modeler
Activiti 开源版本中带了 Web 版流程设计器,在 Activiti-explorer 项目中有 Activiti-Modeler,优点是集成简单,开发工作量小,缺点是界面不美观,用户体验差。

mxGraph
mxGraph 是一个强大的 JavaScript 流程图前端库,可以快速创建交互式图表和图表应用程序,国内外著名的 ProcessOne 和 draw.io 都是使用该库创建的强大的在线流程图绘制网站。
由于 mxGraph 是一个开放的 js 绘图开发框架,我们可以开发出很炫的样式,或者完全按照项目需求定制。
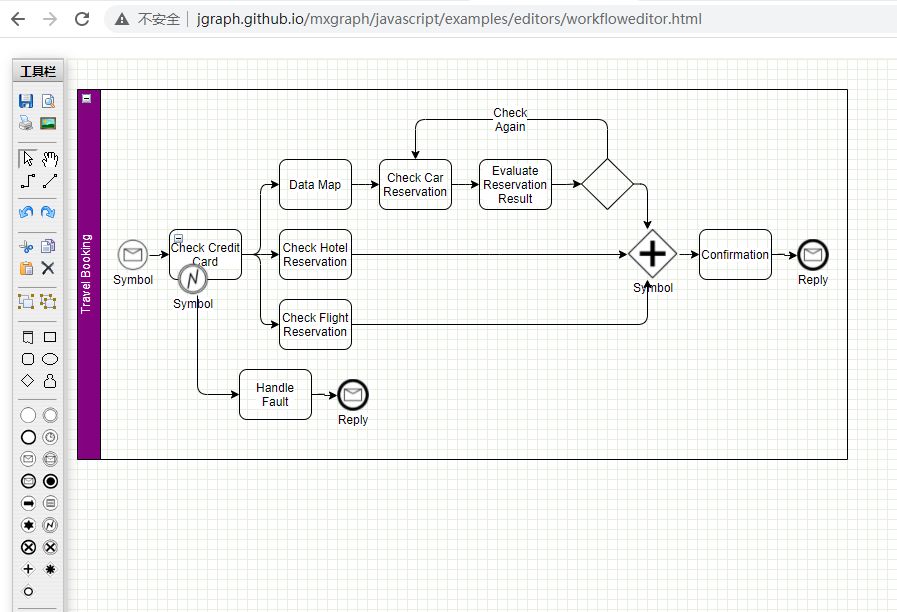
官方网站:http://jgraph.github.io/mxgrap
bpmn-js
bpmn-js 是 BPMN2.0 渲染工具包和 Web 模型。bpmn-js 正在努力成为 Camunda BPM 的一部分。bpmn-js 使用 Web 建模工具可以很方便的构建 BPMN 图表,可以把 BPMN 图表嵌入到你的项目中,容易扩展。
bpmn-js 是基于原生 js 开发,支持集成到 vue、react 等开源框架中。

官方网站:https://bpmn.io/
以上介绍的都属于是功能强大且完善的框架,除此之外,还有其他基于 Vue 或者 React 开发的可视化编辑工具,大家也可以根据自己的实际需求进行选择。
流程引擎
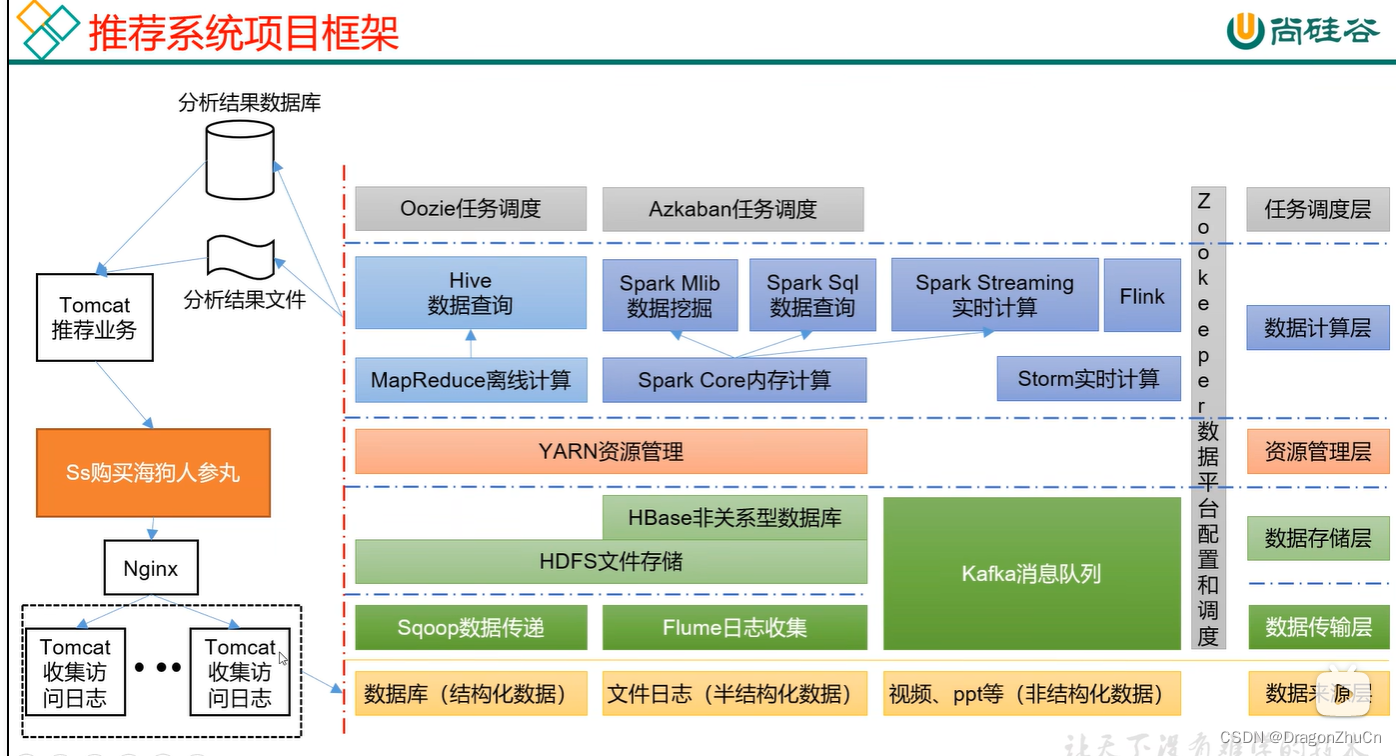
最后来说说流程引擎,整个系统的核心。引擎设计的好坏决定了整个系统的稳定性,可用性,扩展性等等。

整体架构如图所示,主要包括一下几个部分:
一、流程设计器主要通过一系列工具创建一个计算机可以处理的工作流程描述,流程建模通常由许多离散的节点步骤组成,需要包含所有关于流程的必要信息,这些信息包括流程的起始和结束条件,节点之间的流转,要承担的用户任务,被调用的应用程序等。
二、流程引擎主要负责流程实例化、流程控制、节点实例化、节点调度等。在执行过程中,工作流引擎提供流程的相关信息,管理流程的运行,监控流程的运行状态,并记录流程运行的历史数据。
三、存储服务提供具体模型及流程流转产生的信息的存储空间,工作流系统通常需要支持各种常见的数据库存储。
四、组织模型不属于工作流系统的建设范围,但流程设计器在建模的过程中会引用组织模型,如定义任务节点的参与者。还有就是在流程流转的过程中同样也需要引用组织模型,如在进行任务指派时,需要从组织模型中确定任务的执行者。
工作流引擎内部可以使用平台自身的统一用户组织架构,也可以适配第三方提供的用户组织架构。
五、工作流引擎作为一项基础支撑服务提供给各业务系统使用,对第三方系统开放标准的 RESTful 服务。
后记
下面来说说我现在开发的系统支持到了什么程度,以及未来可能的发展方向。由于毕竟不是一个专门的工单系统,工单申请也只是其中的一个模块,所以在整体的功能上肯定和完整的工作流引擎有很大差距。
第一版
第一版并没有流程引擎,开发方式简单粗暴,每增加一个流程,就需要重新开发对应的表和业务代码。
这样做的缺点是非常明显的:
- 每个流程需要单独开发,工作量大,开发效率低
- 流程功能相近,代码重复量大,冗余,不利于维护
- 定制化开发,缺少扩展性#
第二版
第二版,也就是目前的版本。
随着工单流程逐渐增多,工作量逐渐增大,于是开始对流程进行优化,开发了现阶段的工作流引擎。

在新增一个工单流程时,需要先进行工作流配置,配置其基础信息,自定义字段,状态和流转这些信息。还支持配置自动化节点,可以根据条件由程序自动完成相关操作并审批。
配置好之后,后端无需开发,由统一的引擎代码进行处理,包括节点审批流转,状态变更等。只需要开发前端的创建和查询页面即可,相比于第一版,已经在很大程度上提高了开发效率。
目前版本需要优化的点:
- 缺少可视化流程设计器,无法做到拖拽式设计流程
- 节点之间状态流转不够灵活
- 缺少分布式事物支持,以及异常处理机制
下一个版本
针对以上不足,下一个版本准备主要优化三点,如下:
- 需要支持可视化流程设计器,使流程设计更加简单,灵活
- 根据流程配置自动生成前端页面,做到新增一种类型的工单,无需开发
- 增加节点自动化能力,异常处理机制,提高系统的稳定性
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
参考文章:
- https://www.cnblogs.com/grey-wolf/p/15963839.html
- https://www.cnblogs.com/duck-and-duck/p/14436373.html#!comments
- https://zhuanlan.zhihu.com/p/369761832
- https://zhuanlan.zhihu.com/p/143739835
- https://bbs.qolome.com/?p=365
- https://workflowengine.io/blog/java-workflow-engines-comparison/
推荐阅读:
- Git 分支管理策略