大数据特点(4V)
Volume(大量)
非常非常多,大企业数据接近1EB
Velocity(高速)
比如在双十一,数据爆增
Variety(多样)
很多样子的数据,比如,代码,图片,视频,JSON,等等。
Value(低价值密度)
很多数据都是没用的,需要人为去掉无效数据
Hadoop的四大优势
高可靠性
每一个文件服务器,都会备份其他服务器的数据。这样,即使一台服务器的数据丢失,也不会导致数据丢失。
高扩展性
想加一台服务器就加,想减一台服务器就减。
高效性
每一台服务器都是并行操作的,效率很高。
高容错性
一台服务器任务中途停止,会将任务转移到其他服务器上。
Hadoop的组成
Hadoop1.0时代
MapReduce 负责 计算和资源调度
HDFS 负责 数据的存储
Common负责 辅助
Hadoop2.0时代
MapReduce 单纯负责计算
Yarn 负责资源调度
HDFS 负责数据的存储
Common负责辅助
HDFS架构概述
HDFS的英文全称为(Hadoop Distributed File System)意为
Hadoop 分布式文件系统,这就很好理解为什么HDFS这几个字母负责数据的存储了。
Hadoop当中,
DataNode
DataNode负责存储具体的数据和数据的校验工作,可以理解为子节点
NameNode
NameNode 负责存储具体的数据存在哪个子节点当中,也就是DataNode的文件名,文件路径等等。可以理解为父节点
Second NameNode(2NN)
每隔一段时间备份NameNode的数据,防止NameNode数据丢失造成的全盘皆失。
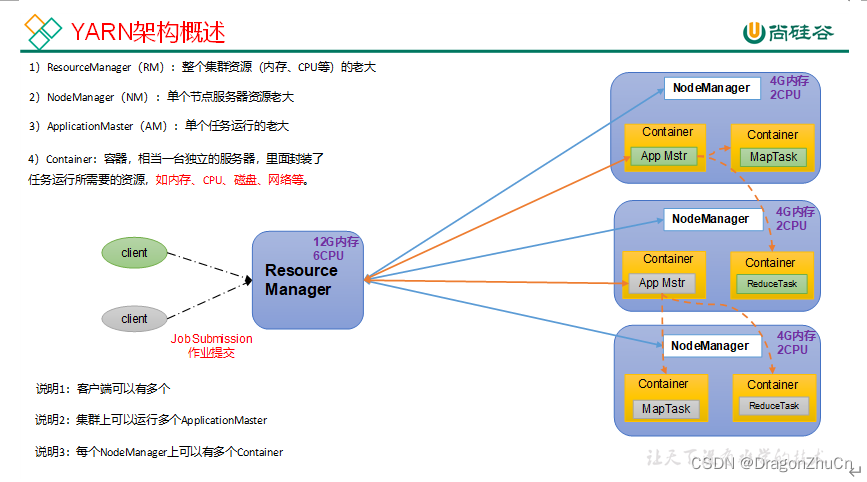
YARN架构概述
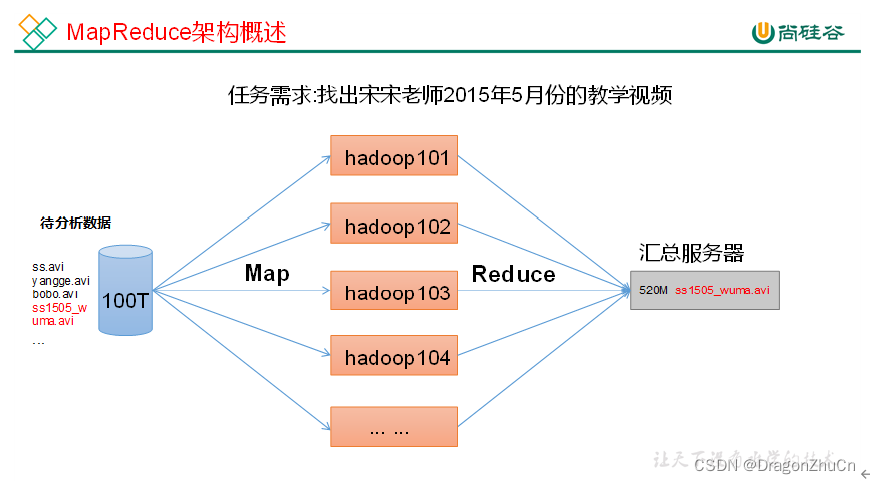
MapReduce架构概述
MapReduce的计算过程,分为Map过程和Reduce过程
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
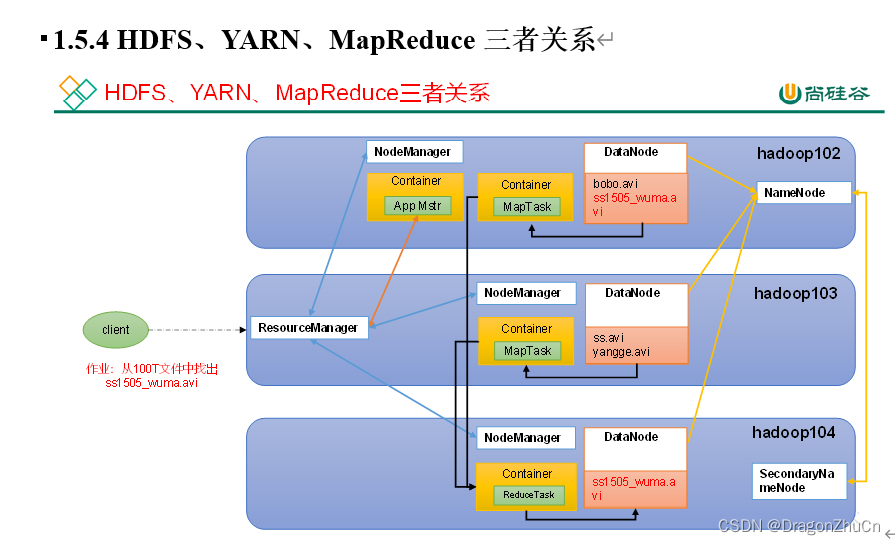
HDFS、YARN、MapReduce三者关系
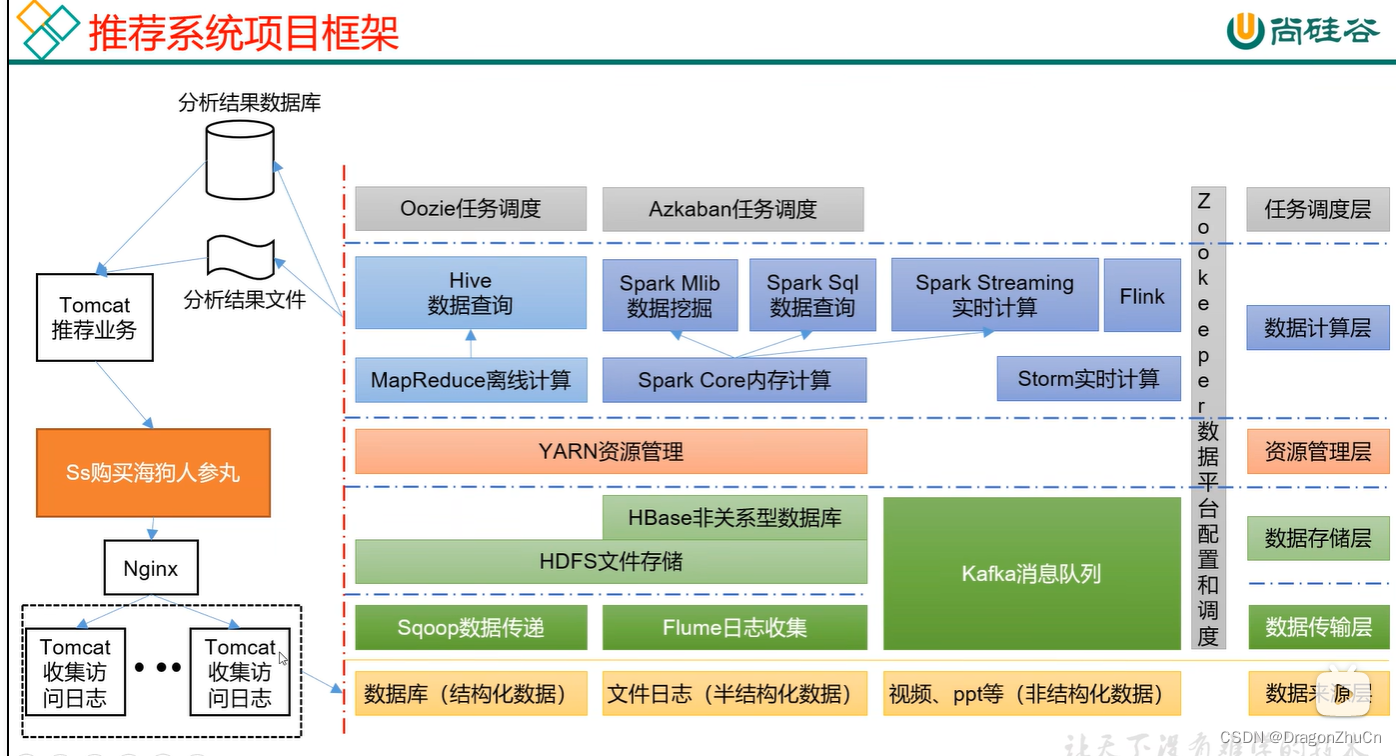
大数据的生态体系