一、实验内容简介
该实验主要使用频繁模式和关联规则进行数据挖掘,在已经使用过Apriori算法挖掘频繁模式后,这次使用FP-tree算法来编写和设计程序,依然使用不同规模的数据集来检验效果,最后分析和探讨实验结果,看其是否达到了理想的效果。本实验依然使用Python语言编写。
二、算法说明
首先简单介绍频繁模式和关联规则:
-
频繁模式一般是指频繁地出现在数据集中的模式。
-
关联规则是形如X→Y的蕴涵表达式,其中X和Y是不相交的项集,即X∩Y=∅。关联规则的强度可以用它的支持度(support)和置信度(confidence)来度量。计算公式如下:
-
支持度:support(A=>B)=P(A∪B),表示A和B同时出现的概率。
-
置信度:confidence(A=>B)=support(A∪B)/support(A),表示A和B同时出现的概率占A出现概率的比值。
-
强关联规则是指达到了最小支持度和最小置信度的关联规则。
然后再介绍FP-Tree算法:
2000年,Han Jiawei等人提出了基于频繁模式树(Frequent Pattern Tree, FP—Tree)的发现频繁模式的算法FP-Growth。其思想是构造一棵FP-Tree,把数据集中的数据映射到树上,再根据这棵FP-Tree找出所有频繁项集。
FP-Growth算法是指,通过两次扫描事务数据集,把每个事务所包含的频繁项目按其支持度降序压缩存储到FP-Tree中。在以后发现频繁模式的过程中,不需要再扫描事务数据集,而仅在FP-Tree中进行查找即可。通过递归调用FP-Growth的方法可直接产生频繁模式,因此在整个发现过程中也不需产生候选模式。由于只对数据集扫描两次,因此FP-Growth算法克服了Apriori算法中存在的问题,在执行效率上也明显好于Apriori算法。
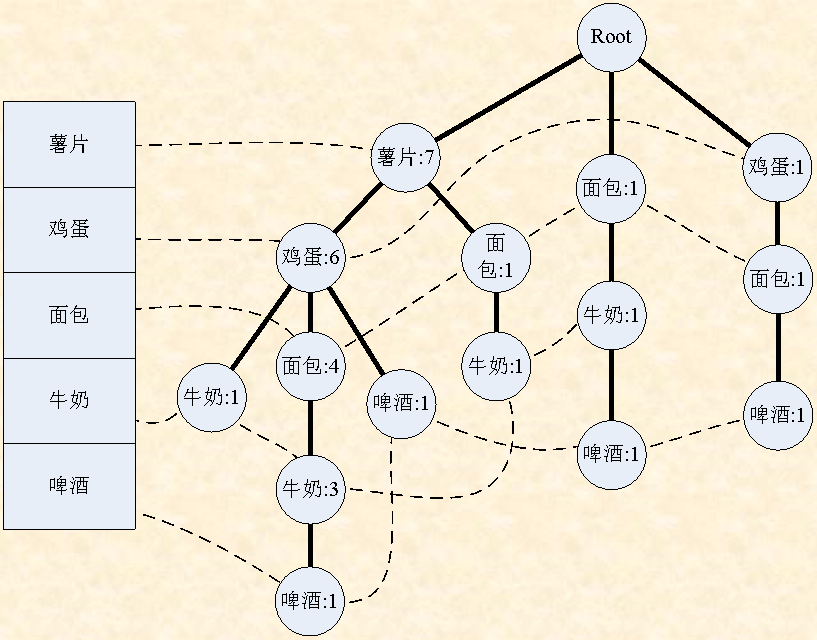
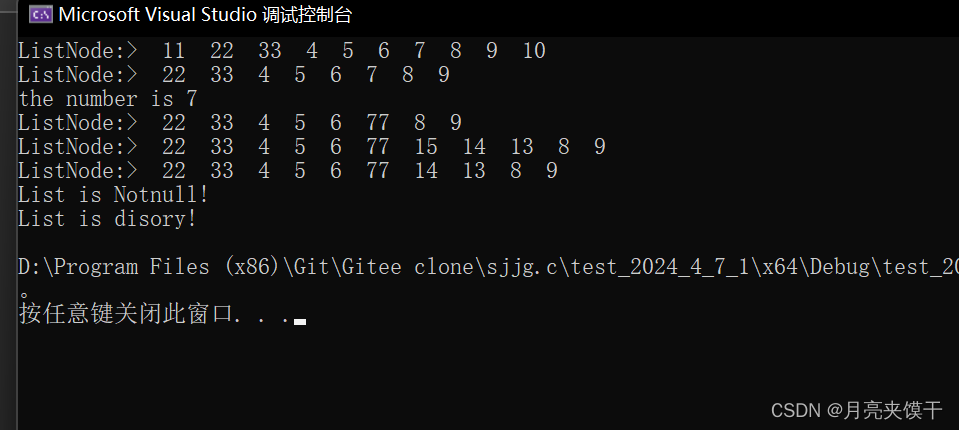
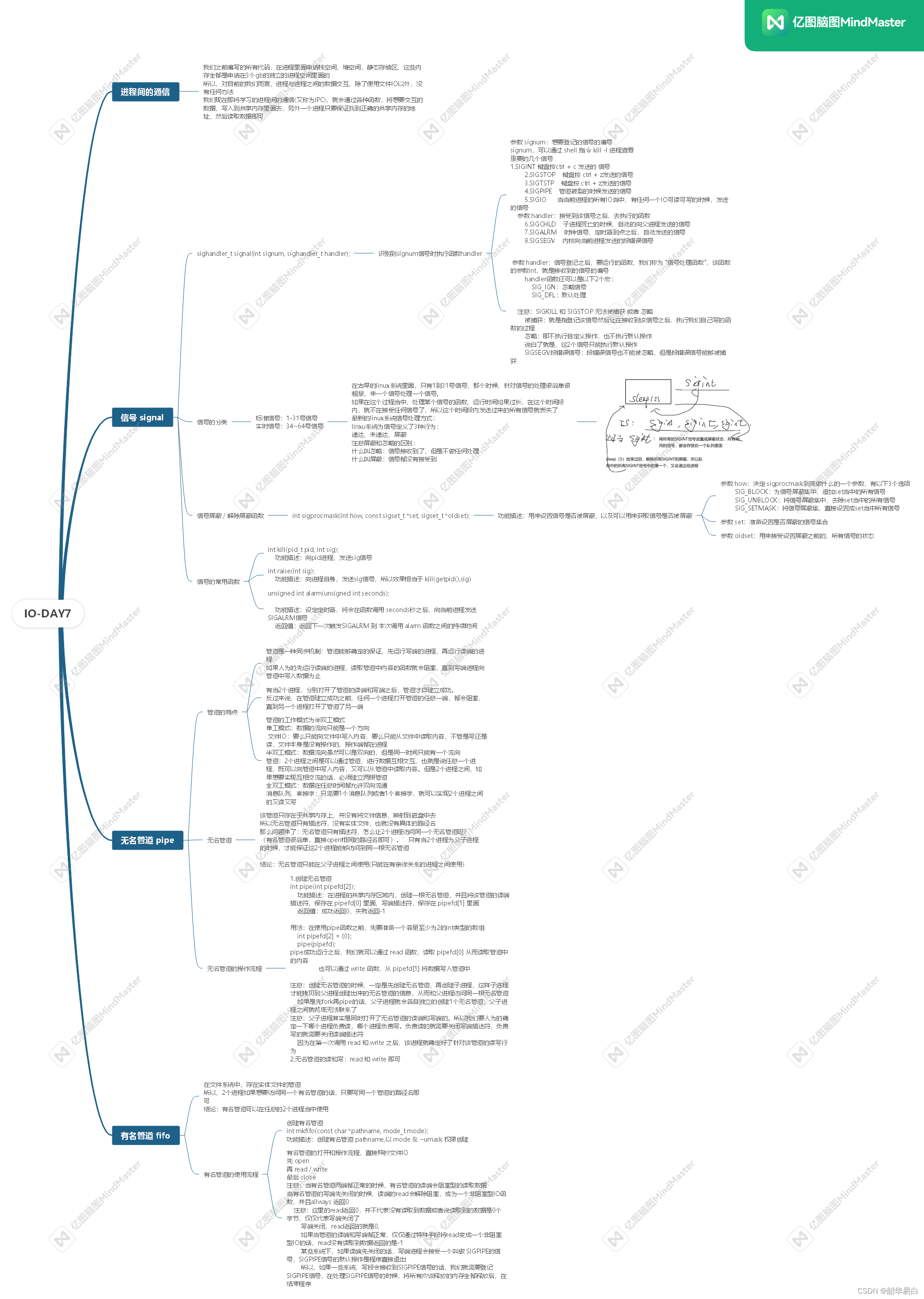
上图为FP-Tree示意图,展示了该数据结构的构成方式。
三、算法分析与设计
了解完算法的基本原理后,现在开始真正实现该算法。首先需要读取最小支持度,读取数据集。这里的数据集可大可小,我用Python中的字典来表示数据
这里的数据存储格式与之前写Apriori算法时一样,使用字典来存储。然后由用户来输入支持度和置信度(因为这次还要挖掘关联规则,所以增加了置信度输入)。
作为FP-Tree的基础,首先构建树节点。一个节点有四个基本属性,分别节点名称、出现次数、双亲节点和孩子节点。因为这里不是二叉树,树的孩子节点个数不确定,因此用字典来存储,大小可控。
class Node:
def __init__(self, value, parent, count=0):
self.value = value
self.parent = parent
self.count = count
self.children = {}
def addChild(self, child):
self.children.update(child)
def __init__(self, value, parent, count=0):
前置准备完成后,开始实现FP-Tree算法。FP-Tree算法可大致分为构建项头表、构建FP-Tree、利用条件模式基挖掘频繁模式和关联规则几步。把这几步集成到一个类中,这样避免了大量函数传参操作,思路更清晰。
首先构建项头表,先扫描一遍数据集挖掘频繁1项集,挖掘出来的数据按支持度降序排列,并按此顺序重新排列原数据集的数据,对于不符合要求的数据直接删除。
def first_scan(self):
"""
生成项头表,整理数据
"""
Dict = dict()
for i in self.data.values():
for j in i:
if j not in Dict.keys():
Dict.update({j: 1})
else:
Dict[j] += 1
self.first_list = list(Dict.items())
self.first_list.sort(key=lambda l: l[1], reverse=True)
for i in range(len(self.first_list) - 1, 0, -1):
if self.first_list[i][1] < self.support * len(self.data):
continue
else:
rubbish = [self.first_list[j][0] for j in range(i + 1, len(self.first_list))]
self.first_list = self.first_list[:i + 1]
break
# 将原来的数据重新按支持度排序并剔除非频繁1项集
sort_refer = [i[0] for i in self.first_list]
for i in self.data.values():
for j in i:
if j in rubbish:
i.remove(j)
i.sort(key=lambda l: sort_refer.index(l))
# 添加频繁1项集
self.pinfan.extend([list(i) for i in self.first_list])
# 整理项头表
self.value_list = [i[0] for i in self.first_list]
temp = {}
for i in self.first_list:
temp.update({i[0]: []})
self.first_list = temp
然后构建FP-Tree。这里的过程就比较复杂了,简要说明步骤。第二次遍历数据集,从上往下构建分支,每次若遇到之前没出现的节点,就新建一个新节点,同时更新FP-Tree和项头表,若遇到之前已经出现的节点,则该节点的次数加一。特殊的根节点不需要存储任何数据,只需要存储孩子节点。
def first_scan(self):
"""
生成项头表,整理数据
"""
Dict = dict()
for i in self.data.values():
for j in i:
if j not in Dict.keys():
Dict.update({j: 1})
else:
Dict[j] += 1
self.first_list = list(Dict.items())
self.first_list.sort(key=lambda l: l[1], reverse=True)
for i in range(len(self.first_list) - 1, 0, -1):
if self.first_list[i][1] < self.support * len(self.data):
continue
else:
rubbish = [self.first_list[j][0] for j in range(i + 1, len(self.first_list))]
self.first_list = self.first_list[:i + 1]
break
# 将原来的数据重新按支持度排序并剔除非频繁1项集
sort_refer = [i[0] for i in self.first_list]
for i in self.data.values():
for j in i:
if j in rubbish:
i.remove(j)
i.sort(key=lambda l: sort_refer.index(l))
# 添加频繁1项集
self.pinfan.extend([list(i) for i in self.first_list])
# 整理项头表
self.value_list = [i[0] for i in self.first_list]
temp = {}
for i in self.first_list:
temp.update({i[0]: []})
self.first_list = temp
然后基于FP-Tree同时挖掘频繁模式和关联规则。利用项头表,从支持度低的元素到支持度高的元素,找到该元素在FP-Tree的所有位置,然后自底向上读取其所有祖先节点(除了根节点),同时把出现的次数都改为该元素所对应节点的次数。挖掘出结果后,先剔除掉不满足支持度要求的项,再通过两两组合挖掘出频繁2项集,然后递归挖掘出频繁多项集。同时两两组合算出条件概率与置信度比较,挖掘出1对1的关联规则。
这里涉及到的操作最为复杂,代码量也最大,分了三个方法来实现。
# 详见附录
def find(self):
def cal(self, Dict: dict, delete=False, length=1):
def rules(self, Dict: dict):
四、测试结果
写完代码后,就又到了测试环节。分别测试正确性和性能。在测试性能的时候也会与Apriori算法做比较,以更好地感受到FP-Tree算法的高效性。
首先验证正确性。我使用了教材上的数据集来验证。

先给定0.5的支持度和0.75的置信度:

经过验证是正确的,再给定0.2的支持度和0.5的置信度:
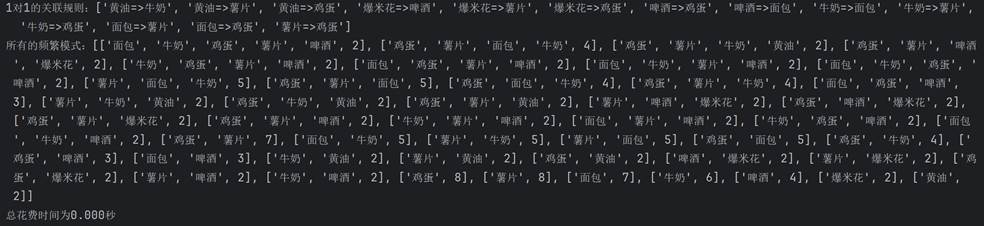
可以看到输出结果大大增加,经过验证也是正确的。
接下来就要扩大数据集的容量了,这样才能分析算法的性能。这里再次使用随机变量来模拟大量的数据:

在这里,arr和data2都可以修改,arr可以修改其中的元素来改变权重,data2可以修改数量,这里统一使用0.5作为支持度,0.75作为置信度。
首先用100000的数据来测试:
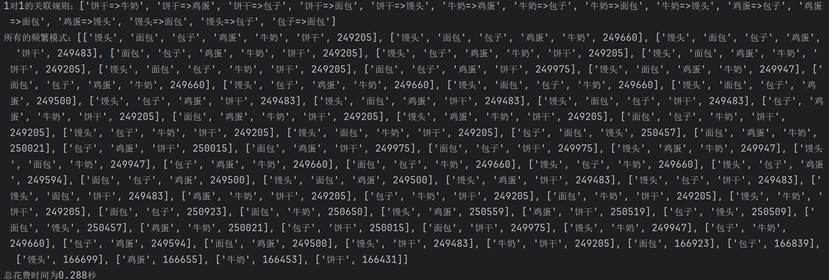
可以看到,一共花了0.288秒。相比其他条件相同下的Apriori算法是1.7秒。
然后把数据量变为1000000来试试:
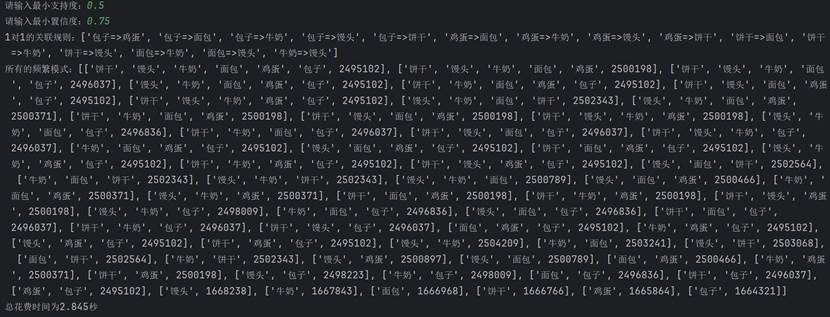
一共花了2.845秒,相比同期Apriori算法一共花了15.58秒。
然后把数据量变为10000000来试试:

一共花了28.054秒,相比同期Apriori算法一共花了171.1秒。
最后再把数据量变为一亿,下图是最终结果。

差不多跑了8分钟,同期Apriori算法半个小时也没跑出来。可以看出,两个算法所耗费的时间都随时间呈线性增长,但FP-Tree算法显然效率比Apriori算法高得多。
五、分析与探讨
测试完算法后,来分析它的性能,思考FP-Tree算法的优势和缺陷。与Apriori算法相比,FP-Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构。Apriori的核心思路是用两个长度为l的频繁项集去构建长度为l+1的频繁项集,而FP-growth则稍有不同。它是将一个长度为l的频繁项集作为前提,筛选出包含这个频繁项集的数据集。用这个数据集构建新的FP-tree,从这个FP-tree当中寻找新的频繁项。如果能找到,那么说明它可以和长度为l的频繁项集构成长度为l+1的频繁项集。然后,我们就重复这个过程。
FP-Tree算法无论从复杂度还是实现难度还是具体技术点来看都比Apriori算法更复杂,但复杂度提高此带来的好处则是更高的效率和更好的性能。二者均为频繁模式挖掘的经典算法,都有必要学习和掌握,期待未来还能不断开发出挖掘频繁模式更加高效的算法。
附录:源代码
# 使用FP-tree实现频繁模式和关联规则挖掘
import itertools
import random
from time import time
# 构建树的节点
class Node:
def __init__(self, value, parent, count=0):
self.value = value
self.parent = parent
self.count = count
self.children = {}
def addChild(self, child):
self.children.update(child)
# 构建FP-tree
class FP_tree:
def __init__(self, data, support, confidence):
self.data = data
self.first_list = []
self.value_list = []
self.support = support
self.confidence = confidence
self.tree = None
self.pinfan = []
self.rule = []
def first_scan(self):
"""
生成项头表,整理数据
"""
Dict = dict()
for i in self.data.values():
for j in i:
if j not in Dict.keys():
Dict.update({j: 1})
else:
Dict[j] += 1
self.first_list = list(Dict.items())
self.first_list.sort(key=lambda l: l[1], reverse=True)
for i in range(len(self.first_list) - 1, 0, -1):
if self.first_list[i][1] < self.support * len(self.data):
continue
else:
rubbish = [self.first_list[j][0] for j in range(i + 1, len(self.first_list))]
self.first_list = self.first_list[:i + 1]
break
# 将原来的数据重新按支持度排序并剔除非频繁1项集
sort_refer = [i[0] for i in self.first_list]
for i in self.data.values():
for j in i:
if j in rubbish:
i.remove(j)
i.sort(key=lambda l: sort_refer.index(l))
# 添加频繁1项集
self.pinfan.extend([list(i) for i in self.first_list])
# 整理项头表
self.value_list = [i[0] for i in self.first_list]
temp = {}
for i in self.first_list:
temp.update({i[0]: []})
self.first_list = temp
def build_tree(self):
"""
建立FP-tree
:return:fp-tree
"""
root = Node('root', None)
parent = root
for i in self.data.values():
for j in i:
# 更新树和项头表
head = self.first_list
if j not in parent.children.keys():
node = Node(j, parent, 1)
temp = {j: node}
parent.addChild(temp)
head[j].append(node)
else:
parent.children[j].count += 1
parent = parent.children[j]
parent = root
self.tree = root
def find(self):
"""
利用建立好的树挖掘频繁模式
"""
for i in self.value_list[::-1]:
i_dict = {}
for j in self.first_list[i]:
k = j
count = j.count
while k != None:
if k.value not in i_dict.keys():
i_dict[k.value] = count
else:
i_dict[k.value] += count
k = k.parent
del i_dict['root']
self.cal(i_dict, True)
def cal(self, Dict: dict, delete=False, length=1):
if delete:
# 预处理,删去支持度低的项
d = Dict.copy()
for i, j in d.items():
if j < self.support * len(self.data):
del Dict[i]
if length == 1:
self.rules(Dict)
# 递归挖掘频繁模式
if length <= len(Dict):
l = list(Dict.keys())
pinfan = [l[0], Dict[l[0]]]
del l[0]
result = itertools.combinations(l, length)
for i in result:
p = pinfan.copy()
for j in i:
p.insert(-1, j)
if Dict[j] < p[-1]:
p[-1] = Dict[j]
p[0:-1] = p[-2::-1]
self.pinfan.append(p)
self.cal(Dict, length=length + 1)
def rules(self, Dict: dict):
"""
只生成1对1的关联规则
:param Dict:数据源
"""
if len(Dict) > 1:
l = list(Dict.keys())
for i in l[1:]:
if min(Dict[l[0]], Dict[i]) / Dict[l[0]] > self.confidence:
self.rule.append(f"{l[0]}=>{i}")
def __str__(self):
"""
输出频繁模式
:return: 所有的频繁模式
"""
print("1对1的关联规则:" + str(self.rule))
self.pinfan.sort(key=lambda l: (len(l), l[-1]), reverse=True)
return "所有的频繁模式:" + str(self.pinfan)
if __name__ == '__main__':
data = {1: ['牛奶', '鸡蛋', '面包', '薯片'],
2: ['鸡蛋', '爆米花', '薯片', '啤酒'],
3: ['牛奶', '面包', '啤酒'],
4: ['牛奶', '鸡蛋', '面包', '爆米花', '薯片', '啤酒'],
5: ['鸡蛋', '面包', '薯片'],
6: ['鸡蛋', '面包', '啤酒'],
7: ['牛奶', '面包', '薯片'],
8: ['牛奶', '鸡蛋', '面包', '黄油', '薯片'],
9: ['牛奶', '鸡蛋', '黄油', '薯片'],
10: ['鸡蛋', '薯片']}
arr = ['牛奶', '面包', '鸡蛋', '馒头', '包子', '饼干']
support = float(input('请输入最小支持度:'))
confidence = float(input('请输入最小置信度:'))
data2 = {i: [random.choice(arr) for j in range(10)] for i in range(100000)}
begin = time()
f = FP_tree(data2, support, confidence)
f.first_scan()
f.build_tree()
f.find()
print(f)
print("总花费时间为%.3f秒" % (time() - begin))