前言:
迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。
比如已经有个模型A 实现了猫狗分类

模型B 要实现大象和老虎分类,可以利用训练好的模型A 的一些参数特征,简化当前的训练
过程.

目录:
- 简介
- Model Fine-Tuning (模型微调)
- multitask learning( 多任务学习)
- Python 例子
一 简介
Transfer Learning 是一种常用的深度学习方案.
如下图:
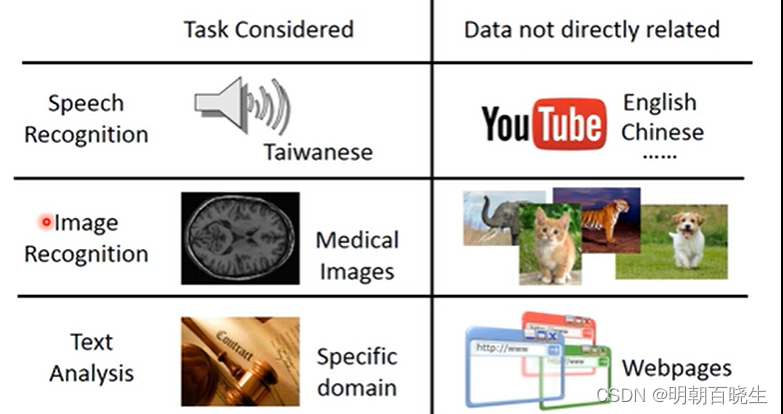
Task A: 通过语音识别台语. 但是 Task Data 中数据集非常少,很难训练出好的模型A,
TaskB: 通过语音识别中英文. 我们很容易获得大量 Source Data,,我们是否可以先 训练一个模型B,实现中英文文语音识别. 然后再通过模型B 的参数去实现 Task A呢?
同样在图像识别,文本分类依然存在同样的场景,需要做的Task A 的 Target Data 非常少,是否
可以利用相似的TaskB ,反过来优化任务A。
二 Model Fine-Tuning (模型微调)
source Data : 已经打了标签,有大量的数据集
Target Data: 未打标签,极少量的数据集,是Target Task.
方案:
1: 先通过 source Data 训练一个模型B,实现Task B
2:再通过参数微调得到模型A,实现Task A
下面介绍几个方案
2.1 Conservation Training 1(保守的微调)
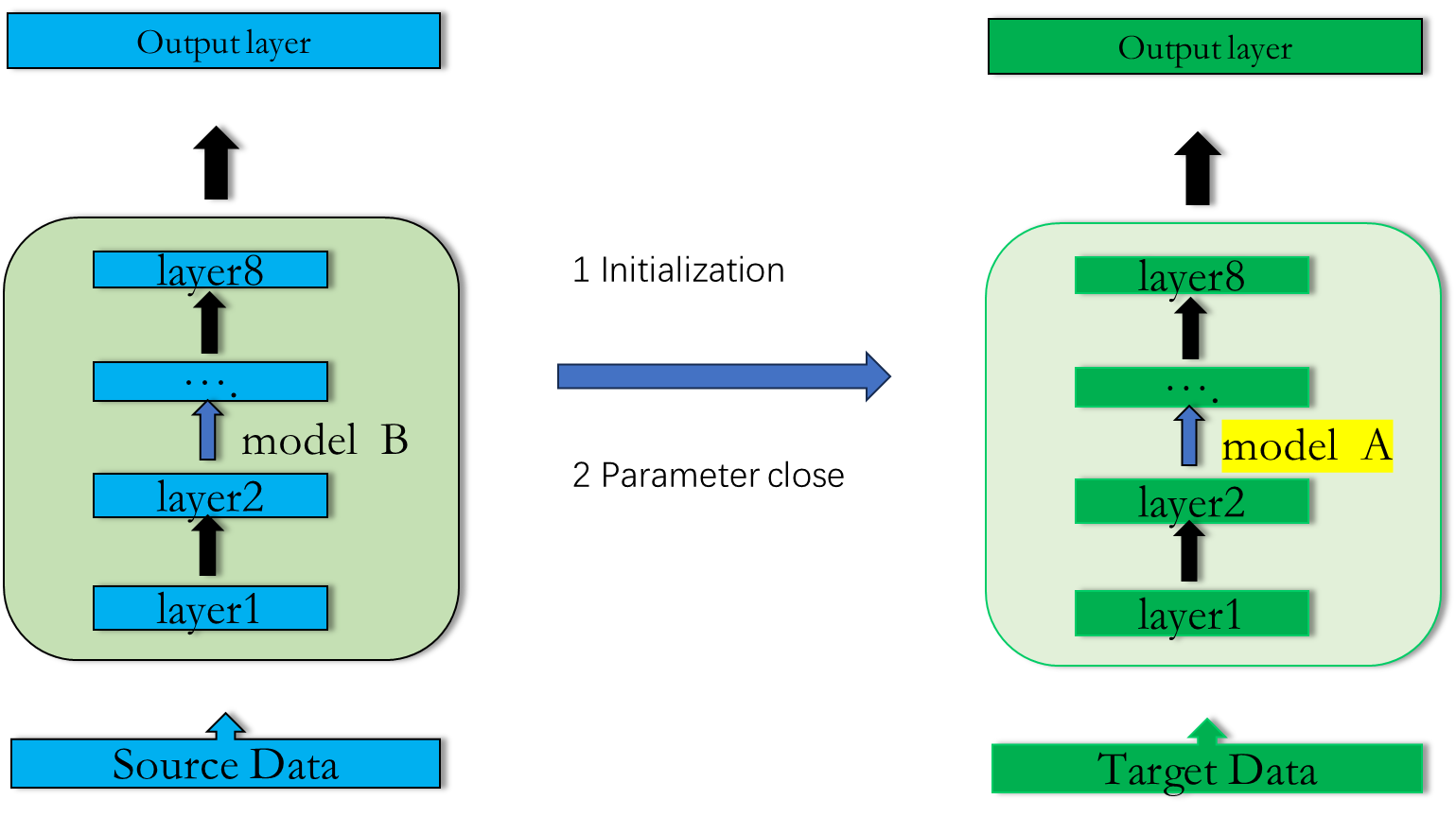
1: 利用source Data 训练出 model B
2: 利用model B 的模型参数初始化 model A
3: 利用Task Data, 只训练几个epoch ,这样model B 和 model A 的参数尽可能的接近
如上面实现猫狗分类 到 老虎和大象分类的例子
2.2 Conservation Training 2 (保守的微调)
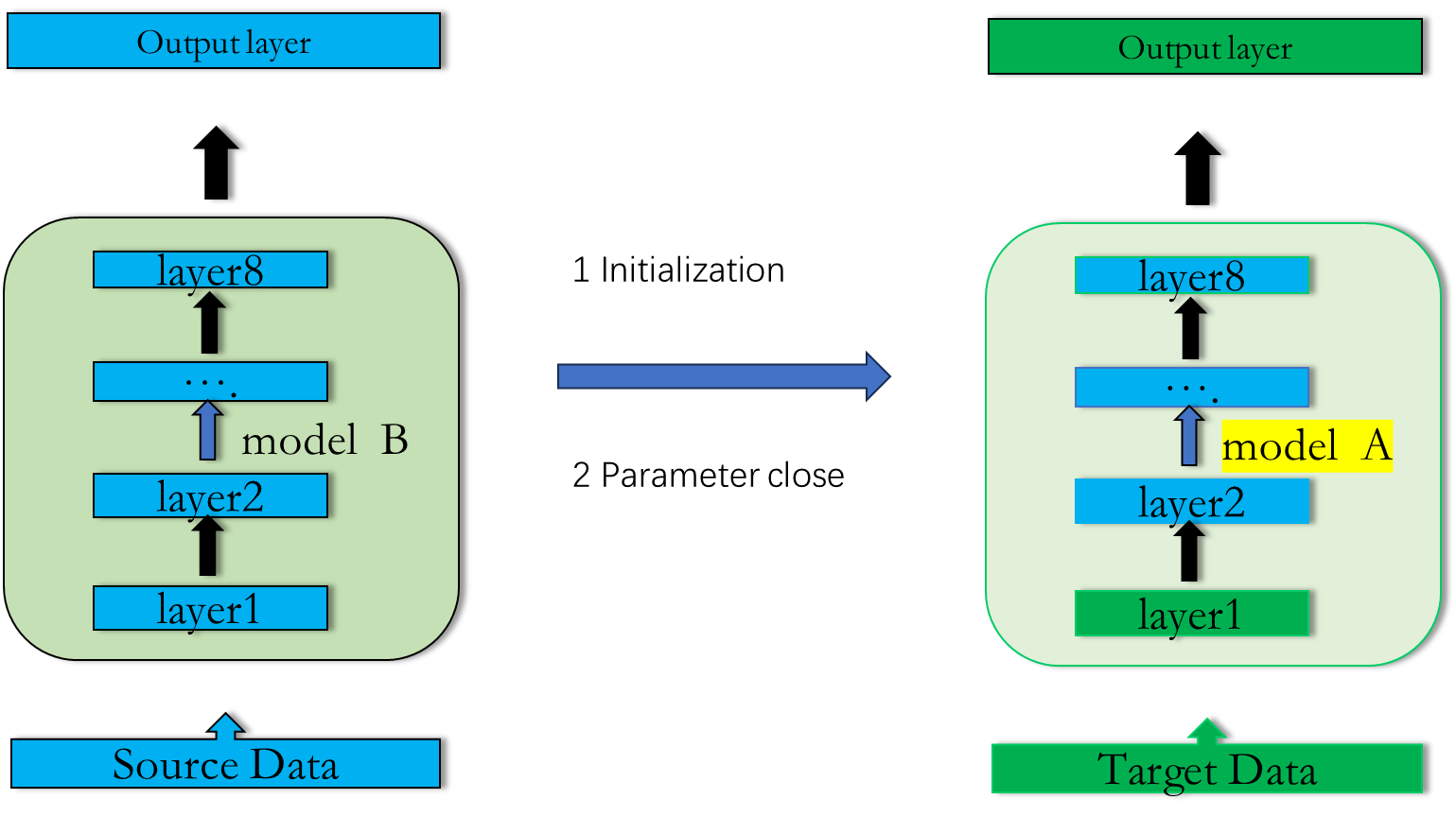
1: 利用source Data 训练出 model B
2: 利用model B 的模型参数初始化 model A
3: 固定部分layer ,利用Target Data 训练剩下来的layer
在语音识别中: 通常copy最后几层, 通过Target Data 训练接近输入层的layer
在图像识别中: 通常copy 前面几层, 通过Target Data 训练接近输出层的layer
二 multitask learning( 多任务学习)
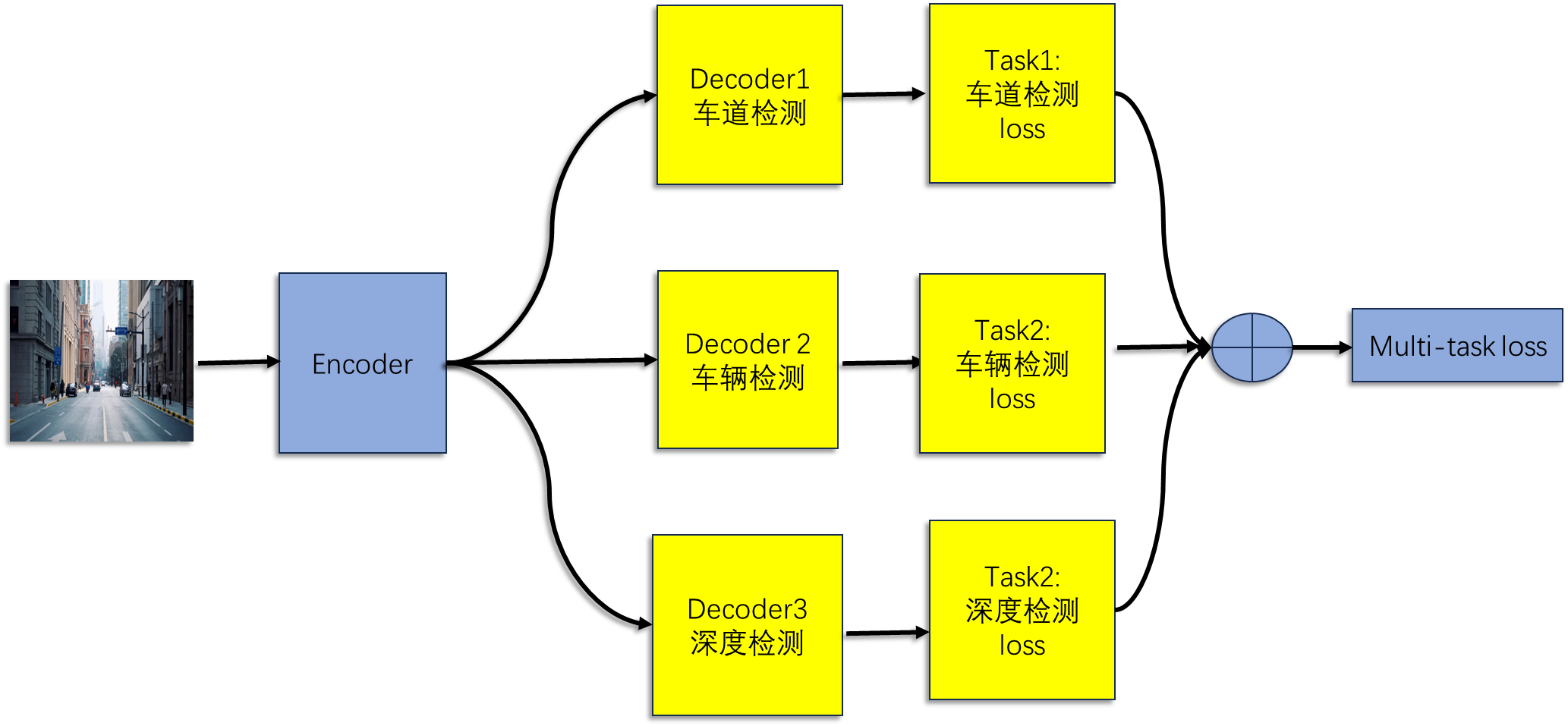
2.1 自动驾驶案例
我们需要实时对图像进行车辆检测、车道线分割、景深估计等 。传统的方式使是基于单任务学习(Single-Task Learning,STL),即每个 任务 使用一个独立的模型。
多任务使用一个模型实现多任务的预测。输入一张图片,通过不同的Decoder 实现不同任务的检测
2.2 语音识别案例

输入一段语音,使用相同的Encoder,不同的Decoder来训练多任务,实现中文,法文,日文,英文文字识别任务。
2.3 为什么要使用该方案
1: 实验效果
很多实验效果证明多任务系统相对于当任务有更好的效果。
比如语音识别例子中,语料库里面 法文标签的数据集非常少,我们可以通过Multi-Task Learning
比单独训练 法文Model 具有更好的效果.
每个任务可以选择性的利用其他任务中学习到的隐藏特征,提高自身能力;
2 训练效率更高
多个任务使用一个共享的Encoder,更少的GPU显存占用,更快的处理性能;
3 泛化性更强
在多个任务的数据集上训练,任务之间有一定相关性,相当于一种隐式的数据增强,可以提高模型泛化能力;
4 防止模型过拟合
兼顾多个任务,一定程度上避免了模型过拟合到单个任务的训练集;
5 更好的特征表达
共享的Encoder输出满足多任务的,相比STL可以获得更好的特征表达;
三 Progressive Neural Networks(增量学习)
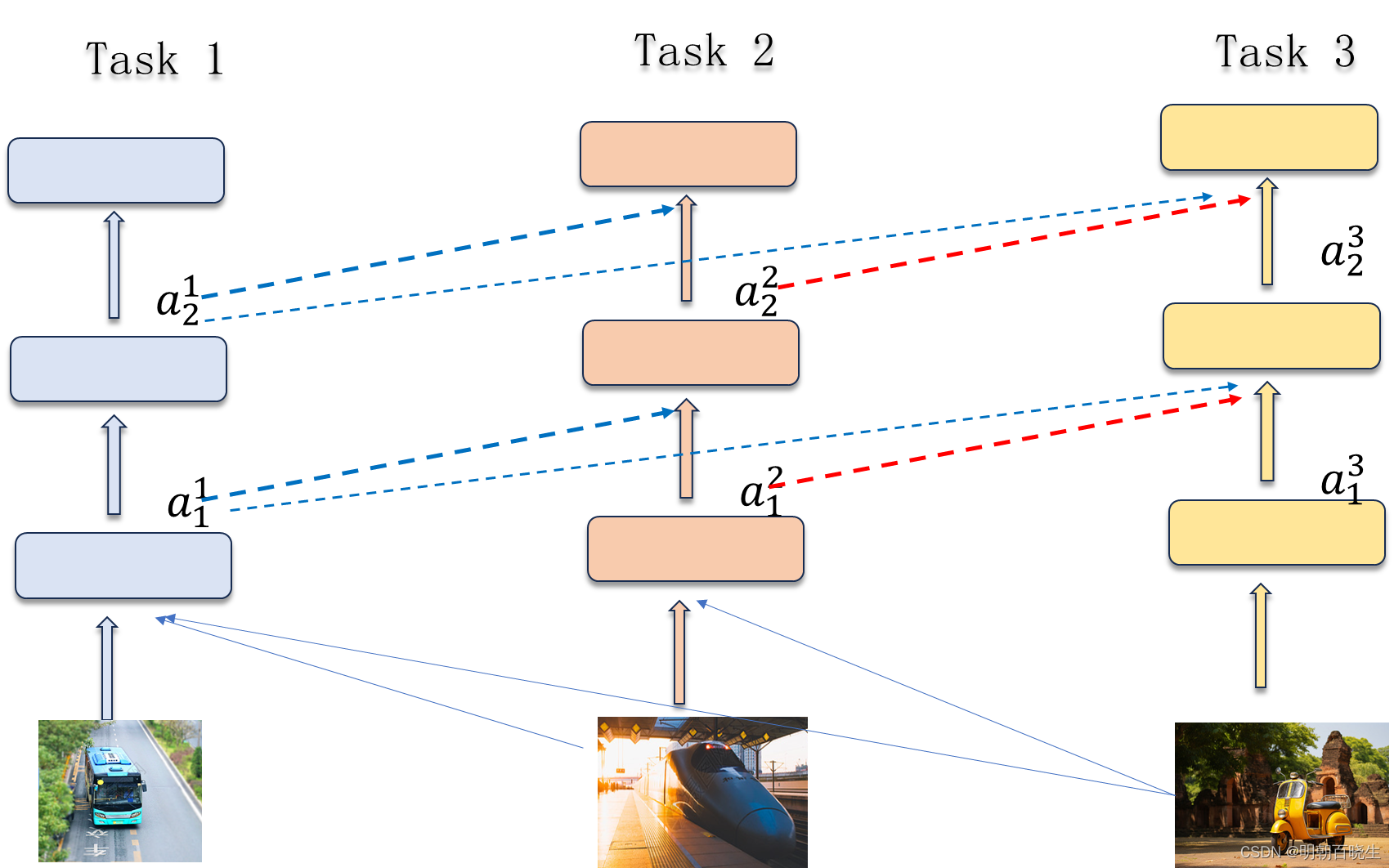
Step 1:构建 Model 1, 通过task1的数据集训练 Model 1
Step 2:固定Model 1,构建Model 2,把task2 的数据集输入Model 1,其每一层的输出添加进Model2 的输入层, 训练Model 2
Step 3: 固定Model1,Model2, 构建Model 3,然后同上一样的方法连接到第三个神经网络中,
训练Model 3
下面给出两个简单的例子
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 7 14:53:19 2024
@author: chengxf2
"""
from torch import nn
from torchvision import models
import torchvision
import torch.optim as optim
from torch.optim import lr_scheduler
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def net():
# 加载预训练模型
model = models.vgg16(pretrained=True)
print(model)
for parameter in model.parameters():
# 冻结了所有层(参数不会更新)
parameter.requires_grad = False
#查看model.parameters()的参数
model.classifier[6] = nn.Linear(in_features=4096, out_features=2, bias=True)
for name,param in model.named_parameters():
print(name, param.requires_grad)
return model
def netFin():
# 加载预训练模型
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
for name,param in model_conv.named_parameters():
print(name, param.requires_grad)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
netFin()
四 Python 例子
利用resnet18 来进行昆虫分类,默认是实现1000种分类。
现在把全连接层改成二分类:分类蚂蚁和蜜蜂,只要训练1-2轮
精确度可以达到90%以上。
项目分为三个部分
1: data.py 加载数据集
2: train.py 训练模型
3: model.py 模型部分
数据集
https://download.csdn.net/download/weixin_46233323/12182815

1: train.py
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 7 15:28:16 2024
@author: chengxf2
"""
import torch
from model import netFin
import time
from tempfile import TemporaryDirectory
import os
from data import create_dataset
import matplotlib.pyplot as plt
from data import imshow
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def visualize_model(model, dataloaders,class_names, num_images,device):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
def train_model(model, criterion, optimizer, scheduler, num_epochs,dataloaders,dataset_sizes):
# Create a temporary directory to save training checkpoints
with TemporaryDirectory() as tempdir:
best_model_params_path = os.path.join(tempdir, 'best_model_params.pt')
torch.save(model.state_dict(), best_model_params_path)
best_acc = 0.0
print("\n --train---")
start_time = time.time()
for epoch in range(num_epochs):
epoch_start_time = time.time()
#print(f'Epoch {epoch}/{num_epochs - 1}')
#print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
#print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), best_model_params_path)
print('End of epoch %d Time Taken: %d sec' % (epoch, time.time() - epoch_start_time),f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
time_elapsed = time.time() - start_time
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(torch.load(best_model_params_path))
return model
if __name__ == '__main__':
num_epochs = 20
num_images = 6
dataloaders,dataset_sizes,class_names = create_dataset()
model, criterion, optimizer, scheduler = netFin()
train_model(model, criterion, optimizer, scheduler, num_epochs,dataloaders,dataset_sizes)
visualize_model(model, dataloaders,class_names, num_images,device)2: data.py
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 7 15:37:38 2024
@author: chengxf2
"""
import os
import torch
from torchvision import datasets, models, transforms
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torchvision
def visualize_model_predictions(model,data_transforms,img_path,device,class_names):
was_training = model.training
model.eval()
img = Image.open(img_path)
img = data_transforms['val'](img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
outputs = model(img)
_, preds = torch.max(outputs, 1)
ax = plt.subplot(2,2,1)
ax.axis('off')
ax.set_title(f'Predicted: {class_names[preds[0]]}')
imshow(img.cpu().data[0])
model.train(mode=was_training)
def imshow(inp, title=None):
"""Display image for Tensor."""
#[channel=3, 228, 228*batch_size]
inp = inp.numpy().transpose((1, 2, 0))
#[228, 228*batch_size, channel=3]
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
#(行, 列, channel):具有RGB值(0-1浮点数或0-255整数)的图像。
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
def create_dataset():
# Data augmentation and normalization for training
# Just normalization for validation
image_datasets={}
dataloaders={}
dataSize ={}
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'hymenoptera_data'
for x in ['train', 'val']:
image_datasets[x]= datasets.ImageFolder(os.path.join(data_dir, x),data_transforms[x])
for x in ['train', 'val']:
dataloaders[x] = torch.utils.data.DataLoader(image_datasets[x], batch_size=2,shuffle=True)
for x in ['train', 'val']:
dataSize[x]= len(image_datasets[x])
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#print(type(dataloaders))
class_names = image_datasets['train'].classes
return dataloaders, dataSize,class_names
'''
# Get a batch of training data
dataloaders, class_names= create_dataset(None)
inputs, classes = next(iter(dataloaders['train']))
#[batch, channel, width, hight]
#print(inputs.shape)
#torch.Size([4, 3, 224, 224])
# Make a grid from batchdataloaders
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
'''3:model.py
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 7 14:53:19 2024
@author: chengxf2
"""
from torch import nn
from torchvision import models
import torchvision
import torch.optim as optim
from torch.optim import lr_scheduler
import torch
from torchsummary import summary
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def net():
# 加载预训练模型
model = models.vgg16(pretrained=True)
print(model)
for parameter in model.parameters():
# 冻结了所有层(参数不会更新)
parameter.requires_grad = False
#查看model.parameters()的参数
model.classifier[6] = nn.Linear(in_features=4096, out_features=2, bias=True)
for name,param in model.named_parameters():
print(name, param.requires_grad)
return model
def netFin():
# 加载预训练模型
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
#打印出默认的网络结构
summary(model_conv, (3, 512, 512)) # 输出网络结构
#model_conv.fc = nn.Linear(num_ftrs, 2)
'''
# Debug info
for name,param in model_conv.named_parameters():
print(name, param.requires_grad)
'''
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
return model_conv, criterion, optimizer, exp_lr_scheduler
Multi-Task Learning 多任务学习 - 知乎
Transfer Learning for Computer Vision Tutorial — PyTorch Tutorials 2.2.1+cu121 documentation








![[Mac]安装App后“XX已损坏,无法打开“](https://img-blog.csdnimg.cn/direct/1c853bec01454fe48d87bbfa5f35f91e.png)