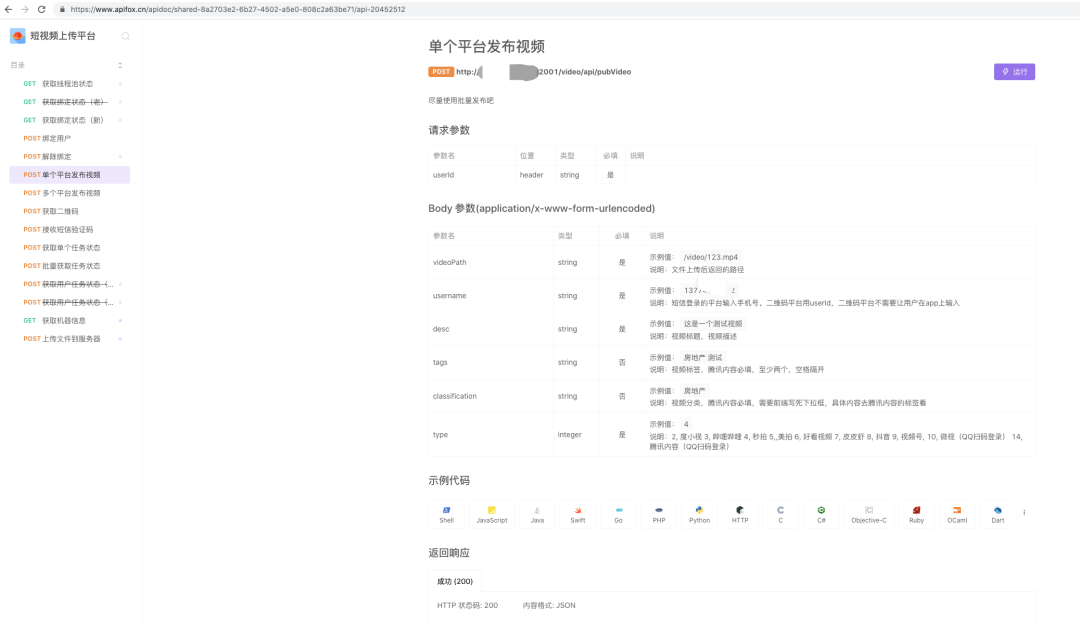
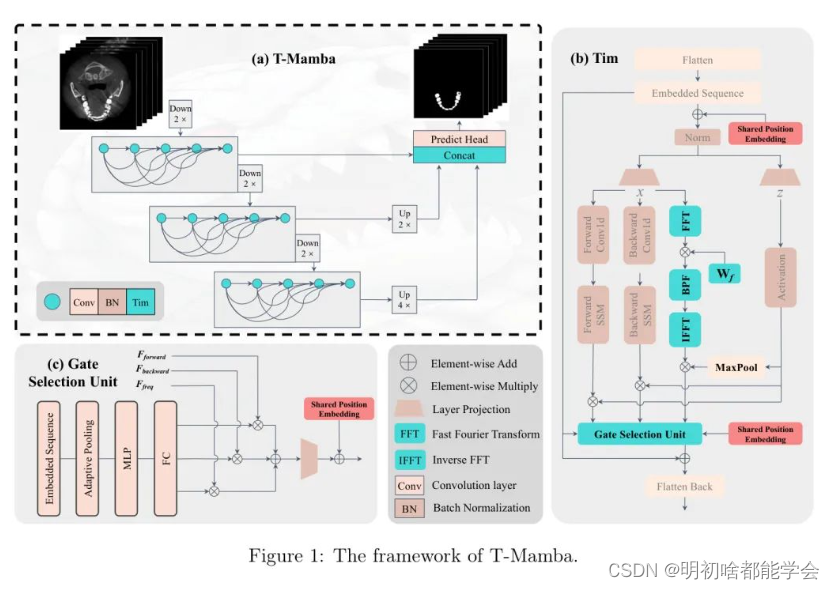
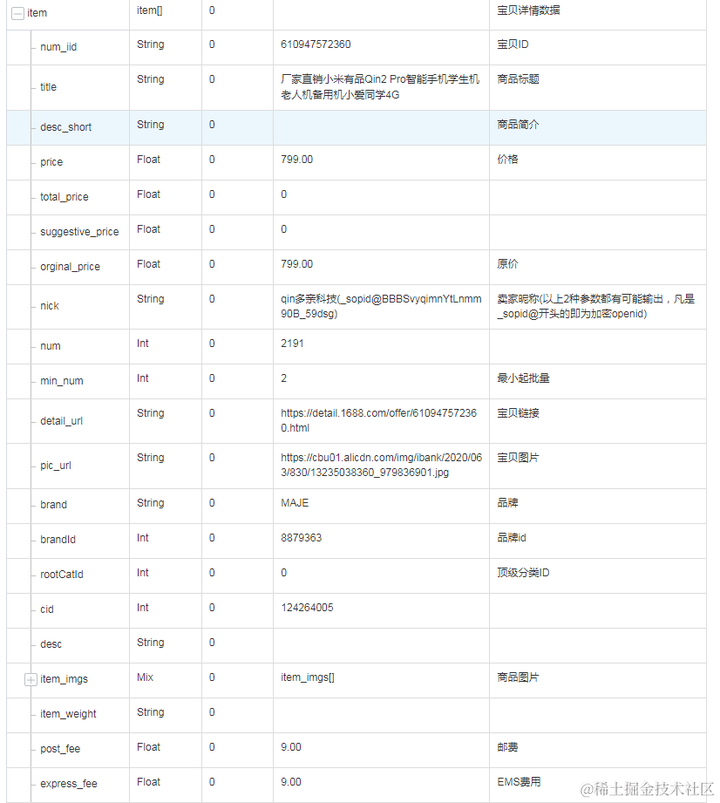
这样一个excel文件,由于行数太多显示不全。
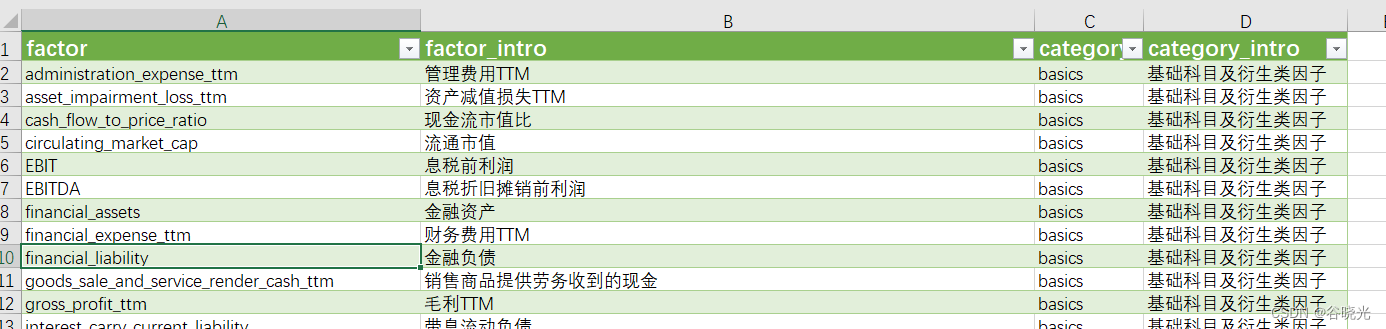
直接读取显示:

该如何处理?方法有很多,这次讲解用dataframe.iterrows()方法。
DataFrame.iterrows()方法:
返回值是一个由索引和Series组成的元组。
关于这个方法的两个注意点:
- Because iterrows returns a Series for each row, it does not preserve dtypes across the rows (dtypes are preserved across columns for DataFrames).
To preserve dtypes while iterating over the rows, it is better to use itertuples() which returns namedtuples of the values and which is generally faster than iterrows.
- You should never modify something you are iterating over. This is not guaranteed to work in all cases. Depending on the data types, the iterator returns a copy and not a view, and writing to it will have no effect.
即:1 不能跨行保持数据类型。2不能再循环处理的过程中改变其中的值。
例子:
import pandas as pd
df1 = pd.read_excel(r'D:\TEST\test20240408\聚宽因子.xlsx')
for i,row in df1.iterrows():
print('{:<};{:<};{:<};{:<}'.format(row.factor,row.factor_intro,row.category,row.category_intro))
结果: