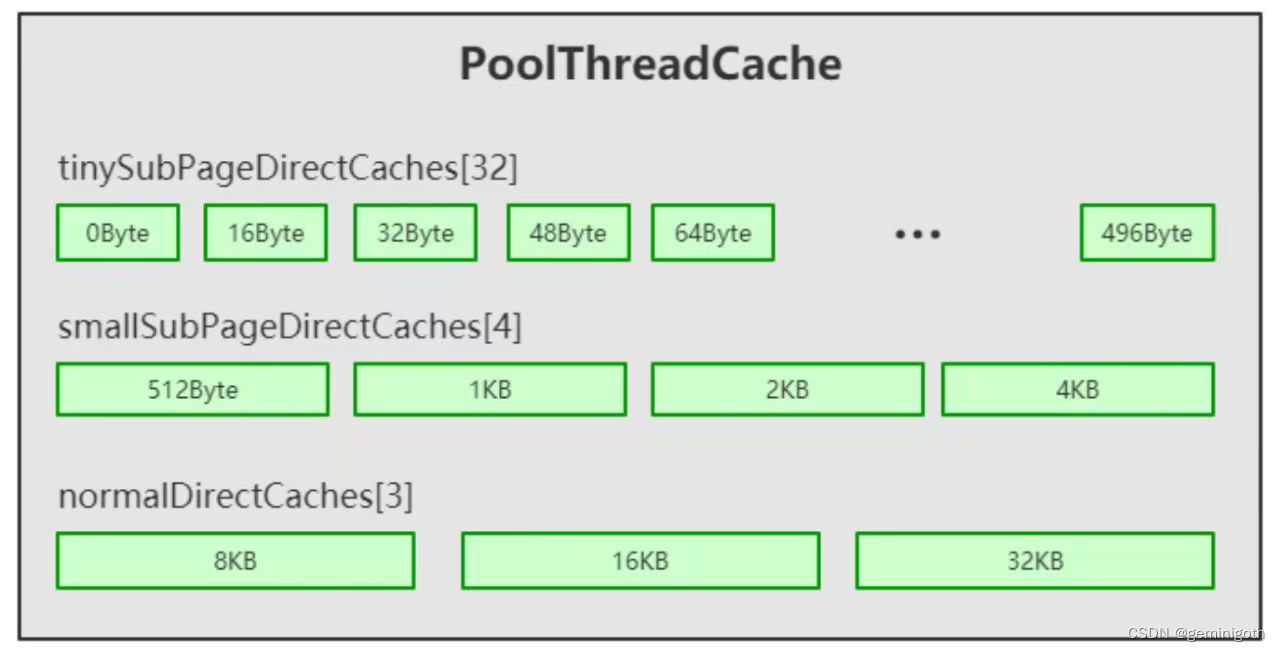
本文使用工具
Anaconda下载安装与使用
Jupyter Notebook的使用
本文使用数据集
机器学习实验所需内容.zip
以朝阳医院2018年销售数据为例,目的是了解朝阳医院在2018年里的销售情况,这就需要知道几个业务指标,本次的分析目标是从销售数据中分析出以下业务指标:
(1)业务指标1:月均消费次数
月均消费次数 = 总消费次数 / 月份数(同一天内,同一个人所有消费算作一次消费)
(2)业务指标2:月均消费金额
月均消费金额 = 总消费金额 / 月份数
(3)客单价
客单价 = 总消费金额 / 总消费次数
(4)消费趋势(可视化展示,并根据可视化结果给出下属问题分析得出的结论)
a、分析每天的消费金额
b、分析每月的消费金额
c、分析药品销售情况(截取销售数量最多的前十种药品,并用条形图展示结果)
数据分析基本过程 数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化以及消费趋势分析。
(一)数据获取
1. 读取数据,并且返回表格的前几行数据
import pandas as pd
# 读取数据(最好使用 object 类型读取)
data = pd.read_excel("朝阳医院2018年销售数据.xlsx", dtype="object")
# 通过panda模块内置的read_excel方法读取格式为.xlsx的excel表格内容,以object类型读取,还有一个为read_csv方法读取的是格式为.csv的Excel表格
data.head()# 返回data的前几行数据,默认为前五行,括号内部可填入数字表示显示几行数据
 图1:读取数据,并且返回表格的前几行数据
图1:读取数据,并且返回表格的前几行数据
2. 修改为 DataFrame 格式,并且查看数据的形状
# 修改为 DataFrame 格式
dataDF = pd.DataFrame(data)# 定义一个dataDF来存储修改为DataFrame格式的数据
# DataFrame是一种表格型的数据结构。它的每一列可以是不同的值类型(例如布尔型、数值型、字符串等),
# 此外它既有行索引index,又有列索引columns。我们可以将它看成是由Series组成的字典(将每一列看成是一个Series)。
# 查看数据的形状,即几行几列
print(dataDF.shape)# 形状(shape) 打印出数据的形状
print("dataDF.index:{}".format(dataDF.index))# 行索引(index) 打印出数据的参数
 图2:修改为 DataFrame 格式,并且查看数据的形状
图2:修改为 DataFrame 格式,并且查看数据的形状
3. 查看每一列的列表头内容
# 查看每一列的列表头内容
print("dataDF.columns:{}".format(dataDF.columns))# 打印出数据的每个列表头的说明,以及数据的类型
print(dataDF.columns)# 列索引(columns)
 图3:查看每一列的列表头内容
图3:查看每一列的列表头内容
4. 查看每一列数据统计数目
# 查看每一列数据统计数目
# count()返回每一列中的非空值的个数。
print("dataDF计数:{}".format(dataDF.count()))
 图4:查看每一列数据统计数目
图4:查看每一列数据统计数目
(二)数据分析
数据清洗过程包括:选择子集、列名重命名、缺失数据处理、数据类型转换、数据排序及异常值处理。
1. 列名重命名
# 使用 rename 函数,把"购药时间" 改为 "销售时间"
dataDF.rename(columns={"购药时间": "销售时间"}, inplace=True)
# 通过rename函数对于数据的列名(columns)里面的购药时间改成销售时间,inplace:是否替换,默认为False。
# inplace为False时返回修改后结果,变量自身不修改。inplace为True时返回None,变量自身被修改。
print("dataDF.columns:{}".format(dataDF.columns))
# 打印出修改后的数据结果,以及数据类型

图5:列名重命名
2. 缺失值处理
# 删除缺失值之前
# 打印出数据缺失值之前的类型(几行几列)
print("删除缺失值之前dataDF.shape:{}".format(dataDF.shape))
# 使用dropna函数删除缺失值
# 因为Excel中的空的cell读入pandas中是空值(NaN),这个NaN是个浮点类型,一般当作空值处理,所以要先去除NaN再进行分隔字符串。
dataDF = dataDF.dropna()# 通过内置的dropna函数删除缺失的数据
# 删除缺失值之后
# 打印出缺失的数据被删除后的数据类型(几行几列)
print("删除缺失值之后dataDF.shape:{}".format(dataDF.shape))
# 将字符串转为浮点型数据
# 将销售数量,应收金额,实收金额的数据类型由字符串转变为浮点数类型(float)
# 数据类型转换:astype函数:字符串转换成数值(浮点型)
dataDF["销售数量"] = dataDF["销售数量"].astype("f8")
dataDF["应收金额"] = dataDF["应收金额"].astype("f8")
dataDF["实收金额"] = dataDF["实收金额"].astype("f8")
print("dataDF.dtypes:{}".format(dataDF.dtypes))

图6:缺失值处理
3. 数据类型转换之自定义函数
# 将日期进行分割
# 自定义函数::分隔销售口期,获取销售日期
# 输入:timeColSer销售时间这一列,是个Series数据类型
# 输出:分割后的时间,返回的也是Series数据类型
def splitsaletime(timeColser):
timelist = []
for t in timeColser:# [0]表示选取的分片,这里表示切割完后选取第一个分片
timelist.append(t.split(" ")[0])# split(" ")分割
timeser = pd.Series(timelist)# 将列表转行为一维数据Series类型
return timeser

图7:数据类型转换之自定义函数
4. 数据类型转换之调用自定义函数
# 获取"销售时间"这一列数据
t = dataDF.loc[:, "销售时间"]# 获取销售时间这一列数据的数据存储到t里面
# 调用函数去除星期,获取日期
timeser = splitsaletime(t)# 对字符串进行分割,获取销售日期
# 修改"销售时间"这一列日期
dataDF.loc[:, "销售时间"] = timeser
print(dataDF.head())

图8:数据类型转换之调用自定义函数
5. 数据类型转换
# 字符串转日期
# errors='coerce'如果原始数据不符合日期的格式,转换后的值为NaT
dataDF.loc[:, "销售时间"] = pd.to_datetime(dataDF.loc[:, "销售时间"], errors='coerce')
# 将原本是字符串的日期类型转变成日期datatime类型的,pandas提供了一个可选的参数errors,
# 传入errors=‘coerce’,pandas遇到不能转换的数据就会赋值为NaN(Not a Number)
print("dataDF.dtypes:{}".format(dataDF.dtypes))

图9:数据类型转换
6. 删除空值
# 转换日期过程中不符合日期格式的数值会被转换为空值None,
# 这里删除为空的行
dataDF = dataDF.dropna()
print("dataDF.shape:{}".format(dataDF.shape))
# 按销售时间进行升序排序
dataDF = dataDF.sort_values(by='销售时间', # by :按几列排序
ascending=True)# ascending=True为升序,ascending=False为降序
print("dataDF.head():{}".format(dataDF.head()))
# 重置索引(index)
dataDF = dataDF.reset_index(drop=True)
# 通过reset进行索引的重置,drop=True表示删除用作新索引的列,也就是删除被用作索引的第一列

图10:删除空值
7. 删除异常值
# 查看描述统计信息
# 描述指标:“销售数量”值不能小于0
print(dataDF.describe())
# 删除异常值:通过条件判断筛选出数据
# 将"销售数量"这一列中小于0的数排除掉
pop = dataDF.loc[:, "销售数量"] > 0
dataDF = dataDF.loc[pop, :]

图11:删除异常值
8. 删除重复数据
# 排除异常值后再次查看描述统计信息
print(dataDF.describe())
# 计算总消费次数
# 删除重复数据
kpi1_Df = dataDF.drop_duplicates(subset=['销售时间', '社保卡号'])
# drop_duplicates是pandas内的一个删除函数,subset:表示要进去重的列名,默认为 None。

图12:删除重复数据
(三)构建模型及数据可视化
数据清洗完成后,需要利用数据构建模型(就是计算相应的业务指标),并用可视化的方式呈现结果。
1. 计算总消费次数
# 计算总消费次数
# 总消费次数:同一天内,同一个人发生的所有消费算作一次消费
# 有多少行
totall = kpi1_Df.shape[0]# 统计有多少行的数据(总消费次数)
print('总消费次数:', totall)
# 按销售时间升序排序
kpi1_Df = kpi1_Df.sort_values(by='销售时间', ascending=True)
# 对销售时间这一列进行升序排序,ascending=True为升序,ascending=False为降序
# 重命名行名(index)
kpi1_Df = kpi1_Df.reset_index(drop=True)

图13:计算总消费次数
2. 业务指标1-3(月均消费次数、月均消费金额、客单价)
# 获取时间范围
# 最小时间值
startTime = kpi1_Df.loc[0, '销售时间']
# 最大时间值
endTime = kpi1_Df.loc[totall - 1, '销售时间']
# 计算天数
daysI = (endTime - startTime).days
# 月份数:运算符"//"表示取整除,返回商的整数部分
monthsI = daysI // 30
print('月份数:', monthsI)
# 计算月均消费次数
# 业务指标1:月均消费次数=总消费次数 / 月份数
kpi1_I = totall // monthsI
print('业务指标1:月均消费次数=', kpi1_I)
# 总消费金额
totalMoneyF = dataDF.loc[:, '实收金额'].sum()
# 月均消费金额
# 业务指标2:月均消费金额 = 总消费金额 / 月份数
monthMoneyF = totalMoneyF / monthsI
print('业务指标2:月均消费金额=', monthMoneyF)
# 业务指标3:客单价 = 总消费金额 / 总消费次数
# 客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。
pct = totalMoneyF / totall
print('业务指标3:客单价=', pct)

图14:月均消费次数、月均消费金额、客单价
3. 业务指标:消费趋势(可视化展示)
# 业务指标:消费趋势,画图-折线图
import matplotlib.pyplot as plt
from pylab import mpl # 画图时用于显示中文字符
mpl.rcParams['font.sans-serif'] = ['SimHei'] # SimHei是黑体的意思
# 在操作之前先复制一份数据,防止影响清洗后的数据
groupDf = dataDF
# 重命名行(index)为销售时间所在列的值
groupDf.index = groupDf['销售时间']
groupDf.head()

图15:重命名行(index)为销售时间所在列的值
4. a、分析每天的消费金额
# a、分析每天的消费金额
plt.figure(figsize=(20,10))# 设置画布大小
plt.plot(groupDf['实收金额'])
# plt.plot(x, y, format_string, **kwargs)可以绘制点和线, 并且对其样式进行控制
# x X轴数据,列表或数组,可选
# y Y轴数据,列表或数组
# format_string 控制曲线的格式字符串,可选
# kwargs 第二组或更多(x,y,format_string),可画多条曲线
plt.title('按天消费金额(ZShiJ)')# 设置图像标题
plt.xlabel('时间') # 设置x轴的标签文本
plt.ylabel('实收金额')# 设置y轴的标签文本
plt.savefig("day.png")# 保存图片
plt.show() # 把图像显示出来。
 图16:a、分析每天的消费金额
图16:a、分析每天的消费金额

图17:按天消费金额
分析:由图17按天消费金额,可以看出,每天的消费金额有所不同,但是除了极个别天会出现消费的金额较大,大部分人消费情况基本都在500元以内。
5. b、分析每月的消费金额
# b、分析每月的消费金额
# 将销售时间聚合按月分组
gb = groupDf.groupby(groupDf.index.month)
print(gb)

图18:b、分析每月的消费金额
6. 描绘按月消费金额图
# 描绘按月消费金额图
# 对进行按月份分组好数据进行求和,从而看到每个月份的销售数量,应收金额,实收金额的数据和
monthDF = gb.sum()
print(monthDF)
# plt.figure(figsize=(8,7))# 设置画布大小
plt.plot(monthDF['实收金额'])# 根据实收金额绘制按月消费金额图的线图
plt.title('按月消费金额(ZShiJ)')# 设置图像标题
plt.xlabel('时间') # 设置x轴的标签文本
plt.ylabel('实收金额') # 设置y轴的标签文本
plt.savefig("month.png")# 保存图片
plt.show() # 把图像显示出来。

图19:描绘按月消费金额图

图20:按月消费金额
分析:由图20按月消费金额的结果显示,我们可以看出7月消费金额最少,我认为这是因为7月份的数据不完整,所以不具参考价值。
1月、4月、5月和6月的月消费金额差异不大,2月和3月的消费金额迅速降低,这可能是2月和3月处于春节期间,大部分人都回家过年的原因。
7. c、分析药品销售情况(截取销售数量最多的前十种药品,并用条形图展示结果)
# c、分析药品销售情况(截取销售数量最多的前十种药品,并用条形图展示结果)
# 聚合统计各种药品的销售数量
# 对“商品名称”和“销售数量”这两列数据进行聚合为Series形式
medicine = groupDf[['商品名称','销售数量']]
# groupby按照商品名称进行分组,算出商品名称对应相应的销售数量
bk = medicine.groupby('商品名称')[['销售数量']]
# 按照商品名称对药品的销售数量进行求和
re_medicine = bk.sum()

图21:c、分析药品销售情况
8. 降序排序截取销售数量最多的十种药品
# 对药品销售数量按降序排序
re_medicine = re_medicine.sort_values(by='销售数量', ascending=False)# 降序排序
re_medicine.head()
# 截取销售数量最多的十种药品
top_medicine = re_medicine.iloc[:10,:]
print(top_medicine)

图22:降序排序截取销售数量最多的十种药品
9. 条形图展示销售数量前十的药品
# 用条形图展示销售数量前十的药品
# 对数据的top_medicine进行条形图的可视化
top_medicine.plot(kind = 'bar',color = 'pink')
plt.title('销售前十的药品(ZShiJ)')# 设置图像标题
plt.xlabel('药品') # 设置x轴的标签文本
plt.ylabel('数量') # 设置y轴的标签文本
plt.savefig("top_medicine.png")# 保存图片
plt.show() # 把图像显示出来。

图23:条形图展示销售数量前十的药品

图24:销售前十的药品
分析:由图24销售前十的药品可以得到销售数量最多的前十种药品信息,这些信息将会有助于加强医院对药房的管理,比如多进一些销售数量多的药品。
异常问题与解决方案
问题1:去重复值用错函数

图25:没有成功去重复值
解决方案:Dropna是删除空值和缺失值,删除重复值需要使用drop_duplicates,drop_duplicates是pandas内的一个删除函数,subset:表示要进去重的列名,默认为 None。

图26:计算总消费次数
问题2:需要注意数据类型转换

图27:数据类型转换
解决方法:一定要记得将原始数据字符串格式日期转换成正常的数据日期,否则会影响后面建模。
参考资料
[1] 详解pandas最常用的3种去重方法
[2] Pandas常用函数大合集
[3] plt.plot()函数解析
[4] Pandas数据排序
[5] 可视化之用pandas绘制简单的图形
回到文章开头