上一篇分析了DirectArena内存分配大小的大概流程(Netty池化内存管理机制),知道了其先命中缓冲,如果没有命中,再去分配一款连续内存。现在分析命中缓存的相关逻辑。前面说到PoolThreadCache中维护了三个缓存数组(实际上是6个,这里仅以Direct为例,Heap类型的逻辑是一样的):tinySubPageDirectCaches、smallSubPageDirectCaches、normalDirectCaches,分别代表tiny类型、small类型、normal 类型的缓存数组。这三个数组保存在PoolThreadCache的成员变量中,代码如下
final class PoolThreadCache { private static final InternalLogger logger = InternalLoggerFactory.getInstance(PoolThreadCache.class); final PoolArena<byte[]> heapArena; final PoolArena<ByteBuffer> directArena; // Hold the caches for the different size classes, which are tiny, small and normal. private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches; private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches; private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches; private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches; private final MemoryRegionCache<byte[]>[] normalHeapCaches; private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;}
在构造方法中进行了初始化,代码如下:
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
this.freeSweepAllocationThreshold = freeSweepAllocationThreshold;
this.heapArena = heapArena;
this.directArena = directArena;
if (directArena != null) {
tinySubPageDirectCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageDirectCaches = createSubPageCaches(
smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalDirect = log2(directArena.pageSize);
normalDirectCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, directArena);
directArena.numThreadCaches.getAndIncrement();
} else {
// No directArea is configured so just null out all caches
tinySubPageDirectCaches = null;
smallSubPageDirectCaches = null;
normalDirectCaches = null;
numShiftsNormalDirect = -1;
}
if (heapArena != null) {
// Create the caches for the heap allocations
tinySubPageHeapCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageHeapCaches = createSubPageCaches(
smallCacheSize, heapArena.numSmallSubpagePools, SizeClass.Small);
numShiftsNormalHeap = log2(heapArena.pageSize);
normalHeapCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, heapArena);
heapArena.numThreadCaches.getAndIncrement();
} else {
// No heapArea is configured so just null out all caches
tinySubPageHeapCaches = null;
smallSubPageHeapCaches = null;
normalHeapCaches = null;
numShiftsNormalHeap = -1;
}
// The thread-local cache will keep a list of pooled buffers which must be returned to
// the pool when the thread is not alive anymore.
ThreadDeathWatcher.watch(thread, freeTask);
}
以tiny类型为例,具体分析一下SubPage的缓存结构,实现代码如下:
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0) {
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
// TODO: maybe use cacheSize / cache.length
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}
从以上代码可以看出,createSubPageCaches()方法中的操作其实就是创建了一个缓存数组,这个缓存数组的擦灰姑娘度是numCaches。
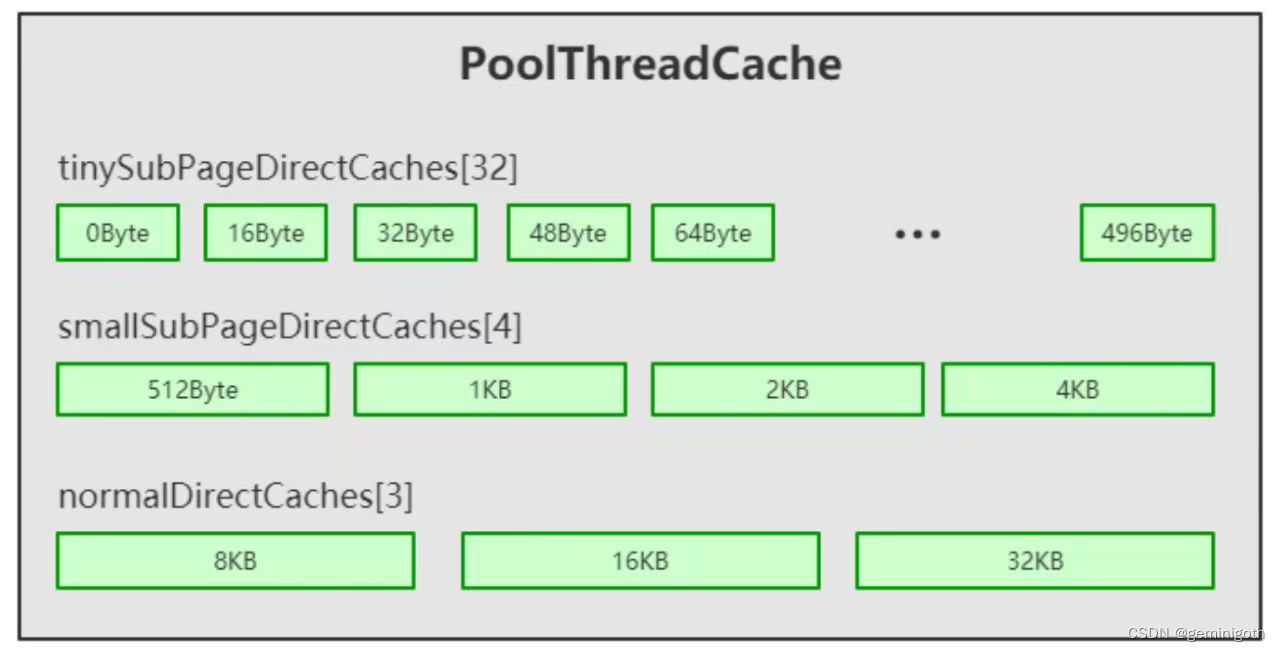
在PoolThreadCache给数组tinySubPageDirectCaches赋值前,需要设定的数组长度就是对应每一种规格的固定值。以 tinySubPageDirectCaches[1]为例(下标选择1是因为下标为0代表的规格是0Byte,其实就代表一个空的缓存),在tinySubPageDirectCaches[1]的缓存对象中所缓存的ByteBuf的缓冲区大小是16Byte,在tinySubPageDirectCaches[2]中缓存的ByteBuf的大小为32Byte,以此类推,tinySubPageDirectCaches[31]中缓存的ByteBuf大小事496Byte。具体类型规则的配置如下。
不同类型的缓存数组规格不一样,tiny类型的数组长度是32,small类型的数组长度是4,normal类型的数组长度是3。缓存数组中的每一个元素都是MemoryRegionCache类型,代表一个缓存对象。每个MemoryRegionCache对象中维护了一个队列,队列的容量大小有PooledByteBufAllocator类中定义的tinyCacheSize、smallCacheSize、normalCacheSize的值来决定。
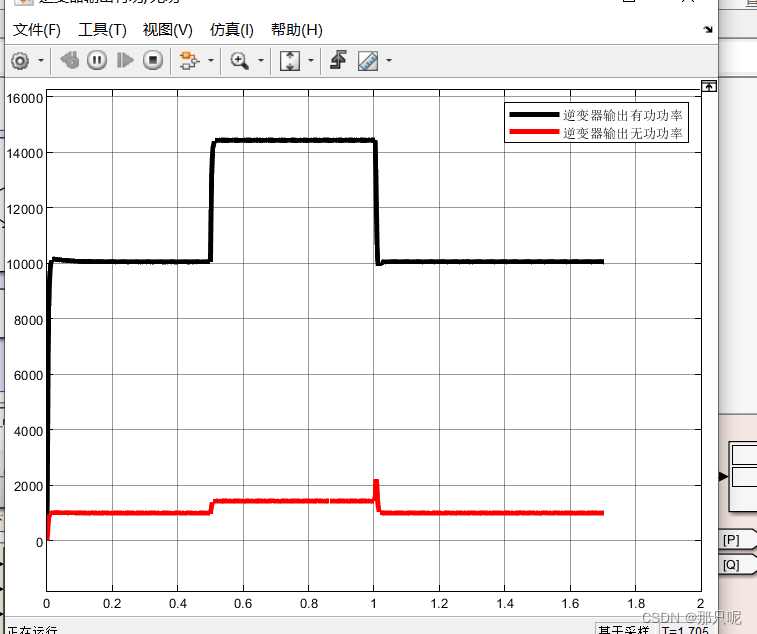
MemoryRegionCache对象的队列中的元素ByteBuf类型,ByteBuf的大小也是固定的。这样,Netty就将每种ByteBuf的容量大小划分成了不同的规格。同一个队列中,每个ByteBuf的容量大小是相同的规格。比如,在tiny类型中,Netty将其长度分成了32种规格,每种规格都是16的整数倍,也就是包含0Byte、16Byte、32Byte、48Byte。。。496Byte,总共32种规格。small类型被分成4种规格,512Byte、1KB、2KB、4KB。normal类型被分成3种规格,8KB、16KB、32KB。由此,PoolThreadCache中缓存数组的数据结构如下图:
在基本了解缓存数组的数据结构之后,继续剖析在缓存中分配内存的逻辑,回到PoolArena的allocate方法,代码如下:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
//判断是不是tiny类型
if (tiny) { // < 512
//缓存分配
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
//通过tinyIdx获取tableIdx
tableIdx = tinyIdx(normCapacity);
//SubPage的数组
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
//获取对应的节点
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
//默认情况下,Head的next也是自身
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
if (normCapacity <= chunkSize) {
//首先在缓存上进行内存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
//分配成功,返回
return;
}
//分配不成功,做实际的内存分配
allocateNormal(buf, reqCapacity, normCapacity);
} else {
// 大于这个值,就不能在缓存个上分配
allocateHuge(buf, reqCapacity);
}
}首先通过normalizeCapacity方法进行内存规格化,代码如下:
int normalizeCapacity(int reqCapacity) {
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
if (reqCapacity >= chunkSize) {
return reqCapacity;
}
//如果是tiny类型的大小
if (!isTiny(reqCapacity)) { // >= 512
// Doubled
//找一个2的 n次方的数值,确保数值大于等于reqCapacity
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
return normalizedCapacity;
}
// 如果是16的倍数
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
//不是16的倍数,变成最小大于当前值的值+16
return (reqCapacity & ~15) + 16;
}上面的代码中if (!isTiny(reqCapacity))的作用是,如果分配的缓冲空间的大于tiny类型的大小,则会找一个2的n次方的数值,以便确保这个数值大于等于reqCapacity。如果是tiny类型,则继续往下执行 if ((reqCapacity & 15) == 0) ,这里判断如果是16的倍数,则直接返回。如果不是16的倍数,则返回 (reqCapacity & ~15) + 16 ,也就是变成最小大于当前值的16的倍数值。从上面规格化逻辑可以看出,这里将缓存大小规格化固定大小,确保每个缓存对象缓存的ByteBuf容量统一。allocate方法中的 isTinyOrSmall 则是根据规格化后的大小判断类型是tiny还是small。
boolean isTinyOrSmall(int normCapacity) {
return (normCapacity & subpageOverflowMask) == 0;
}
这个方法通过判断normCapacity是否小于一个Page的大小(8KB)来判断类型(tiny或者small)。继续看allocate方法,如果当前大小类型是tiny或者small,则通过isTiny(normCapacity)判断是否是tiny类型,代码如下:
static boolean isTiny(int normCapacity) {
return (normCapacity & 0xFFFFFE00) == 0;
}
这个方法是判断如果小于512Byte,则认为是tiny类型。如果是tiny类型,则通过cache.allocateTiny(this,buf,reqCapacity,normCapacity)在缓存上进行分配。以tiny类型为例,分析在缓存分配ByteBuf的流。allocateTiny是缓存分配的入口,PoolThreadCache的allocateTiny方法的实现代码如下:
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
这里有个方法cacheForTiny(area,normCapacity),其作用是根据normCapacity找到tiny类型缓存数组中的一个缓存对象。cacheForTiny方法的代码如下
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
int idx = PoolArena.tinyIdx(normCapacity);
if (area.isDirect()) {
return cache(tinySubPageDirectCaches, idx);
}
return cache(tinySubPageHeapCaches, idx);
}
其中, PoolArena.tinyIdx(normCapacity) 是找到tiny类型缓存数组的下标,继续看tinyIdx方法的代码
static int tinyIdx(int normCapacity) {
return normCapacity >>> 4;
}
这里相当于直接将normCapacity除以16,通过前面的内容已经知道,tiny类型缓存数组中每个元素规格化的数据都是16的倍数,所以通过这种方式可以找到其下标,如果是16Byte会获得下标为1的元素,以此类推。
在cacheForTiny方法中,通过if(area.isDirect()) 判断是否分配堆外内存,因为是按照堆外内存进行举例的,所以这里为true。 cache(tinySubPageDirectCaches, idx) 方法的实现代码如下:
private static <T> MemoryRegionCache<T> cache(MemoryRegionCache<T>[] cache, int idx) {
if (cache == null || idx > cache.length - 1) {
return null;
}
return cache[idx];
}
可以看到,直接通过下标的方式获取了缓存数组中的对象,回到PoolTHreadCache的allocateTiny方法,代码如下:
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
获取缓存对象后,来看allocate(cacheForTiny(area,normCapacity),buf,reqCapacity)方法的实现
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
// no cache found so just return false here
return false;
}
boolean allocated = cache.allocate(buf, reqCapacity);
if (++ allocations >= freeSweepAllocationThreshold) {
allocations = 0;
trim();
}
return allocated;
}
分析上面的代码,看到cache.allocate(buf,reqCapacity)继续进行分配。来看一下内部类MemoryRegionCache的allocate(PooledByteBuf<T>buf,int reqCapacity)方法的具体代码
public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {
Entry<T> entry = queue.poll();
if (entry == null) {
return false;
}
initBuf(entry.chunk, entry.handle, buf, reqCapacity);
entry.recycle();
// allocations is not thread-safe which is fine as this is only called from the same thread all time.
++ allocations;
return true;
}
在这个方法中,首先通过queue.poll()方法弹出一个Entry,MemoryRegionCache内部维护着一个队列,而队列中的每一个值都是一个Entry。来看Entry类的实现代码。
static final class Entry<T> {
final Handle<Entry<?>> recyclerHandle;
PoolChunk<T> chunk;
long handle = -1;
Entry(Handle<Entry<?>> recyclerHandle) {
this.recyclerHandle = recyclerHandle;
}
void recycle() {
chunk = null;
handle = -1;
recyclerHandle.recycle(this);
}
}