目录
Q1:为什么String类要定义成不可变类型?
方便String对象缓存HashCode值
字符串常量池的需要
衍生问题:String str = new String("hello world") 创建了几个对象?
为了保障程序的安全性
Q2:String的不可变特性体现在哪?
Q3:JDK9之后的String类为什么要变为byte数组?
Q4:为什么不推荐String类用于字符串拼接?
Q5:String.intern()方法的作用?不同JDK版本有何区别?
String.intern()是什么?
intern方法在不同JDK版本中的区别?
Q1:为什么String类要定义成不可变类型?
方便String对象缓存HashCode值
在日常工作中,String对象常用作HashMap等容器中作为键值对的(key)键存在,它会用于计算哈希桶的索引位置。故String对象设计为不可变可以保障每次计算的哈希码为固定值,因此可以放心地作为HashMap中的key出现。且String类中定义了一个成员变量来存储哈希值,这体现了一种性能优化手段,意味着不必每次都去计算哈希码。
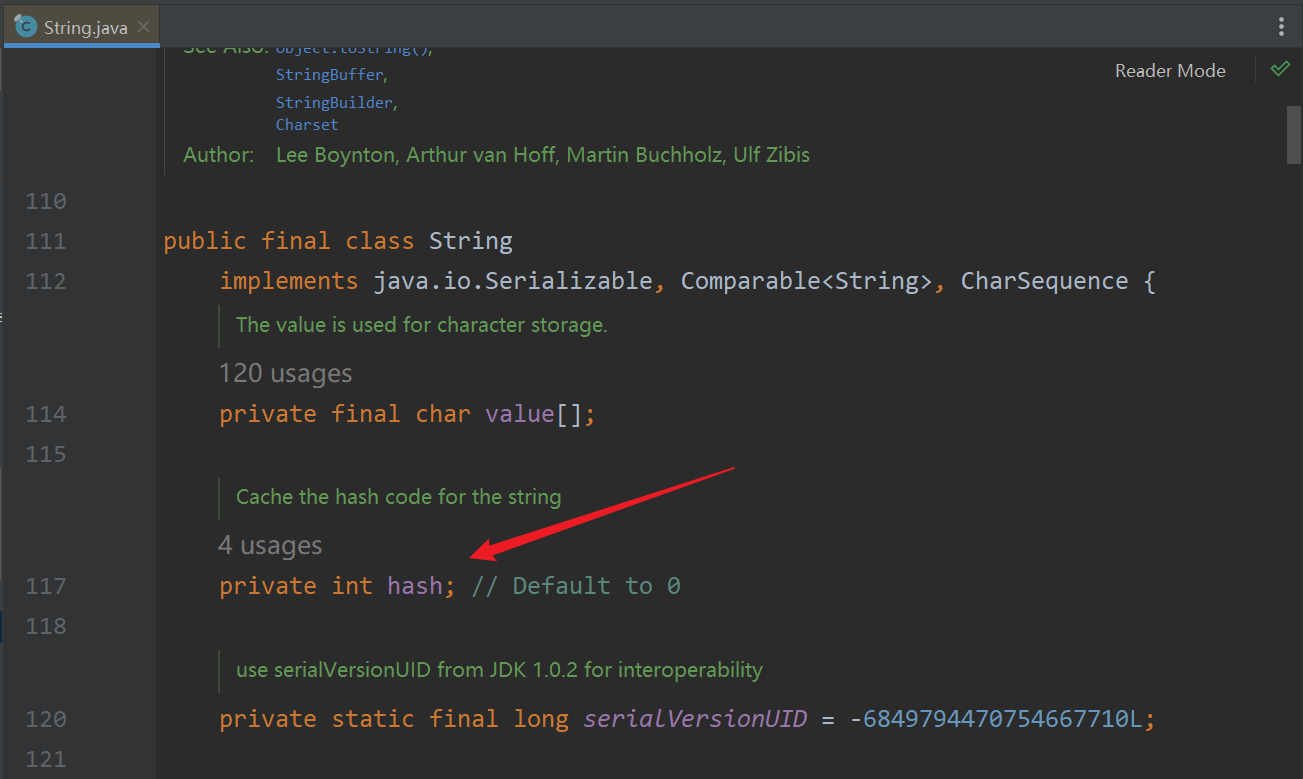
String类默认重写了equals 和 HashCode方法,也就说明可以进行等值判断。


字符串常量池的需要
字符串常量池是Java堆内存中一个特殊的存储区域。当创建一个String对象时,如果该字符串已经存在于常量池中,则不会创建一个新对象,而是将变量指向常量池中已经存在的那个字符串对象。
String str1 = "hello world";
String str2 = "hello world";上面示例代码虽然定义了两个String对象,但实际在堆内存中只存在一份 "hello world" 对象。
内存布局如下所示:

衍生问题:String str = new String("hello world") 创建了几个对象?
这个问题有两个回答:2或1
为2的情况:
字符串常量池中不存在"hello world",这时在堆内存中的新生代伊甸园区(大对象可能会分配在老年代)需要创建一个String类型的对象,且还需要在字符串常量池中放入一个值为 "hello world" 的对象。
为1的情况:
字符串常量池中存在值为"hello world"的String对象,这时在堆内存中的伊甸园区需要创建一个String类型的对象,其它不需要再创建额外对象。
为了保障程序的安全性
String类被许多其它的Java类库用来当做参数,例如网络连接地址URL,反射机制所需要的String参数等等。假若String是可变类型,在网络连接被攻击时将会引起各种安全隐患。
Q2:String的不可变特性体现在哪?
以JDK8作为demo,看看类的设计有哪些体现了String不可变性
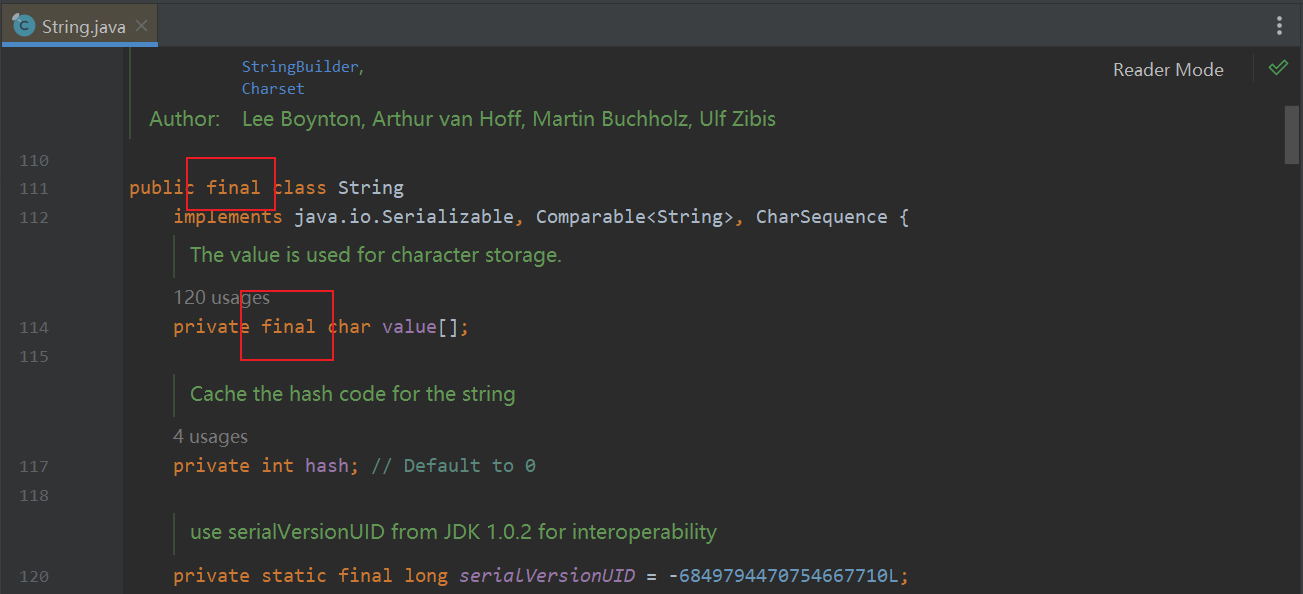
大家都知道,在类上加上final关键字会使该类会拥有不可被其它类继承的特性,变量上使用该关键字会使其引用地址不可被更改【内部数值可以更改】。很多人误以为这两点是String类不可变的最大功臣,其实不然,String类不可变的根本原因是因为它是使用一个内部私有【外部类不可见】的 char数组来实现,且类内部没有对外提供修改该数组的方法。
Q3:JDK9之后的String类为什么要变为byte数组?
承接上文,JDK9之前String类中使用的是char数组,为什么在后续版本中要更换为byte数组呢?
先给出结论:优化Java虚拟机(JVM)中String对象占用的内存大小
具体理由如下:
char类型的数据在JVM中占用了两个字节的空间,使用的是UTF-16编码。这就导致了原本String中的字符原本仅需一个字节表示的对象会占用两个字节,且实际工作经验表明使用频率最高的还是单字节的字符。所以将原本的char数组更换为byte数组,并提供了一个编码标志位属性coder,用来表示不同编码格式。
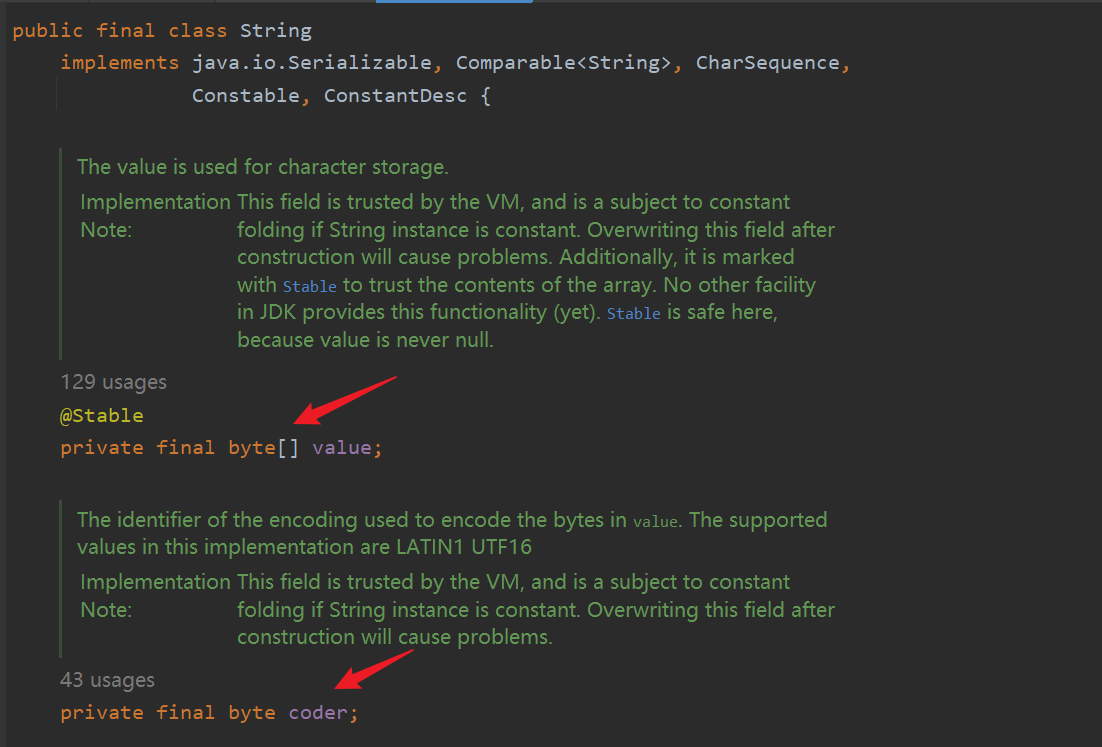
且后续更新中还新增了一个优化字符串的属性COMPACT_STRINGS
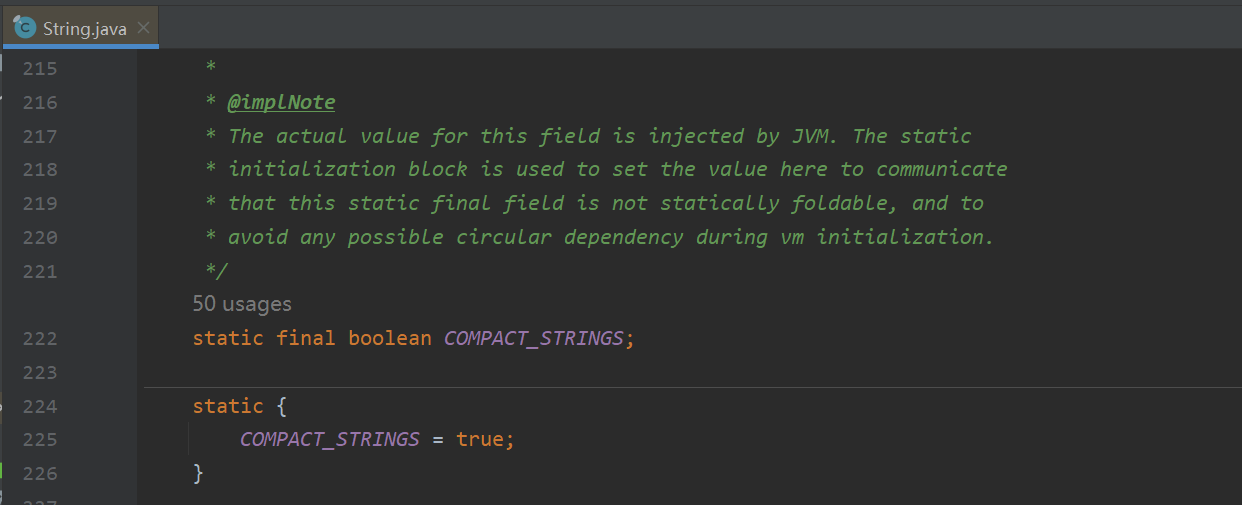
这个字段翻译过来的意思很好理解,就是压缩字符串,静态代码块中默认赋值为true。
它在String对象的构造器中发挥着巨大作用
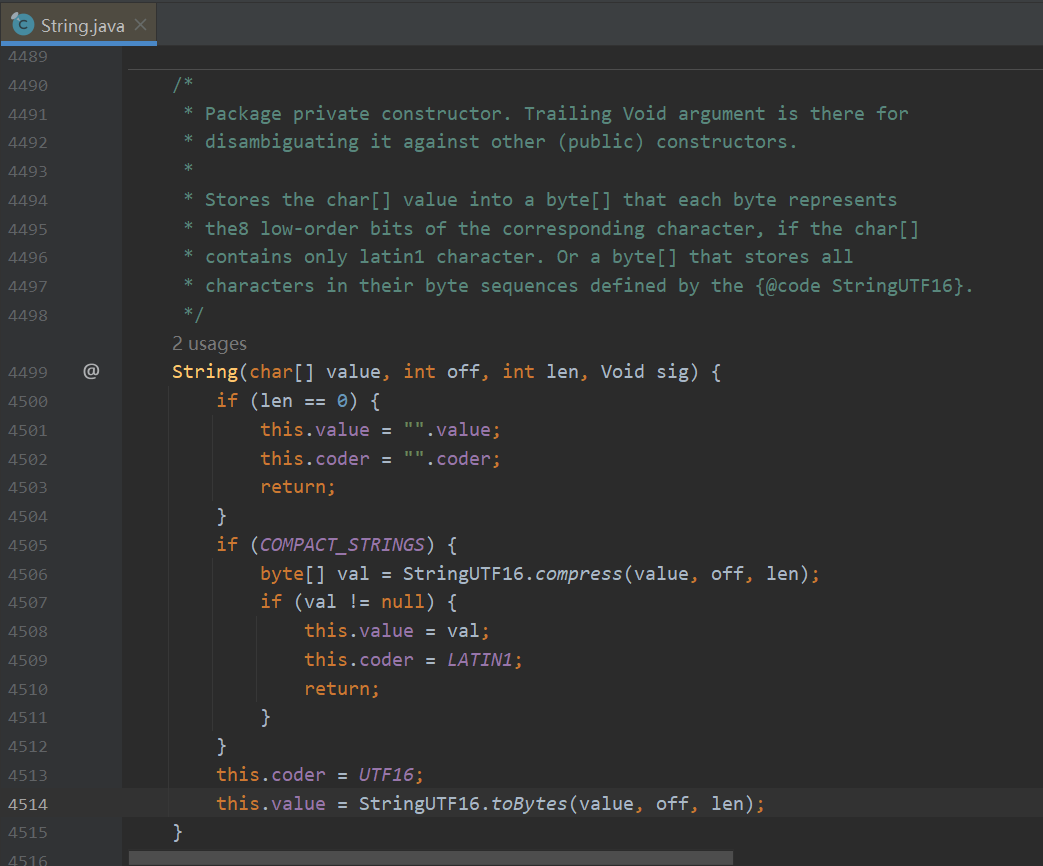
这段代码非常好理解,COMPACT_STRINGS = true时尝试对字符串进行压缩,将coder = LATIN1
对于 String str = "hello" 来说,JDK9之前可能至少需要10个字节来存储,但优化后仅需5个字节。
Q4:为什么不推荐String类用于字符串拼接?
先来看看String类中对于字符串拼接是怎样实现的。
对于如下这段代码,使用javap -c StringTest.class 查看字节码文件


红框中也就是字符串拼接的核心操作【之前JDK版本中是利用StringBuilder对象进行拼接】
参考其它博主的字节码
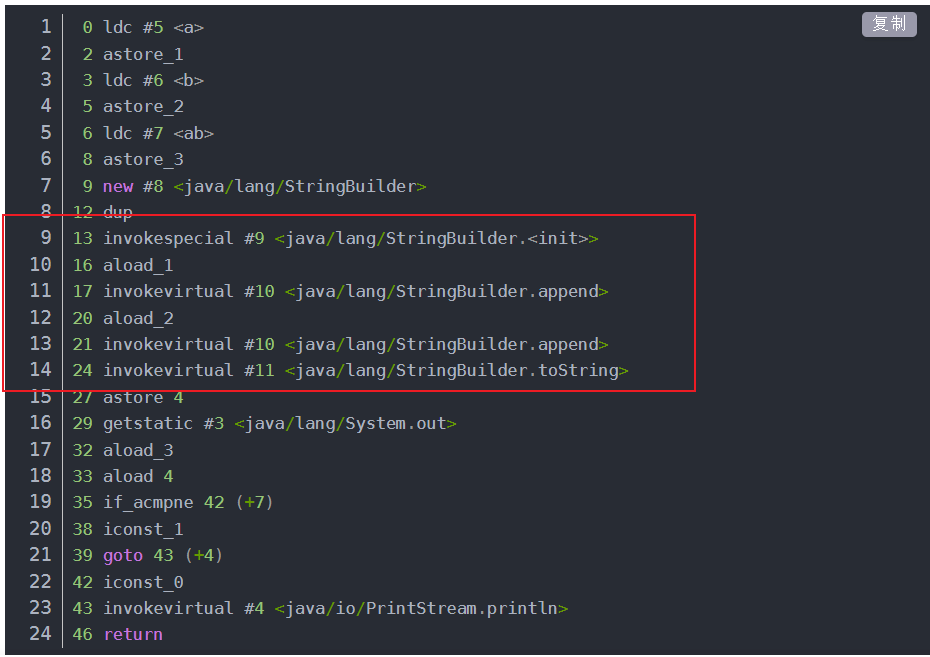
上述的makeConcatWithConstants 其实是通过动态调用的方式执行java.lang.invoke.StringConcatFactory类中的makeConcatWithConstants方法进行字符串连接。
尽管JDK团队已经对其进行了优化,但效率与StringBuilder及StringBuffer比还是惨不忍睹。
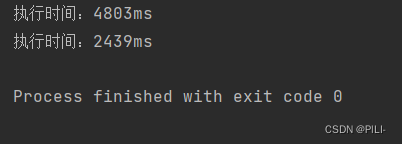
下面做一个效率测试,三者对同一个字符串对象进行拼接,循环1万次,统计耗时。
public class StringTest2 {
private static final long TEN_THOUSAND = 10000;
public static void main(String[] args) {
String str = "string";
StringBuilder stringBuilder = new StringBuilder("stringBuilder");
StringBuffer stringBuffer = new StringBuffer("stringBuffer");
System.out.println("string...");
long startTime = System.currentTimeMillis();
for (int i = 0; i < TEN_THOUSAND; i++) {
str += i;
}
System.out.println("string耗时:" + (System.currentTimeMillis() - startTime) + " ms");
System.out.println("stringBuilder...");
long startTime2 = System.currentTimeMillis();
for (int i = 0; i < TEN_THOUSAND; i++) {
stringBuilder.append(i);
}
System.out.println("stringBuilder:" + (System.currentTimeMillis() - startTime2) + " ms");
System.out.println("stringBuffer...");
long startTime3 = System.currentTimeMillis();
for (int i = 0; i < TEN_THOUSAND; i++) {
stringBuffer.append(i);
}
System.out.println("stringBuffer:" + (System.currentTimeMillis() - startTime3) + " ms");
}
}
程序运行结果如下:
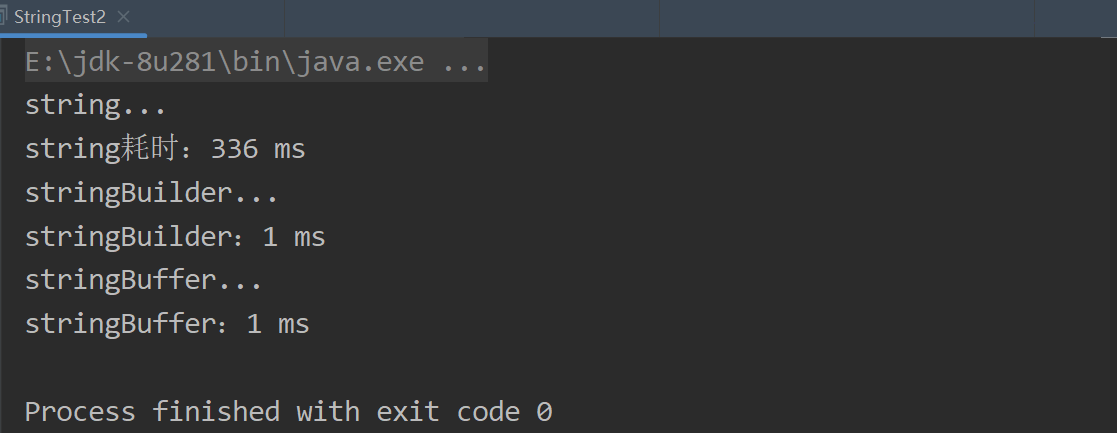
结果很明显了...,对于后两者来说,StringBuffer适合用于多线程下的字符串操作,因为其内部使用synchronized关键字保证线程安全,而StringBuilder不具有该特性。
Q5:String.intern()方法的作用?不同JDK版本有何区别?
String.intern()是什么?
String.intern()是一个Native方法,底层调用C++的 StringTable::intern方法实现。当通过语句str.intern()调用方法后,JVM 就会在当前类的常量池中查找是否存在与str等值的String,若存在,则直接返回常量池中相应String的引用;若不存在,则会在常量池中创建一个等值的String,然后返回这个String在常量池中的引用。
intern方法在不同JDK版本中的区别?
在JDK6中,JVM中的字符串常量池还在永久代。调用intern方法时,若常量池不存在等值的字符串,JVM就会在字符串常量池创建一个等值的字符串,然后返回该字符串的引用。
在JDK6之后,JVM中的字符串常量池被移到了堆空间中。调用intern方法时,与JDK6不同的是,若常量池不存在等值的字符串,这时复制堆空间中等值字符串的引用到常量池中并返回。
参考链接:
https://blog.csdn.net/qq_45800640/article/details/120284367
Java编程笔记11:字符串_魔芋红茶的博客-CSDN博客
谈谈String.intern方法_求你了,别走。的博客-CSDN博客_string.intern


![[GXYCTF2019]BabysqliV3.0](https://img-blog.csdnimg.cn/b65c232e6f3e4b169994eefa6b42bee2.png)