1、何时需要复制寄存器?
在设计中的关键路径发现某个寄存器具有高扇出和高延迟时,使用寄存器复制是个不错的实现时序收敛的方法。
下图是一个典型的例子:
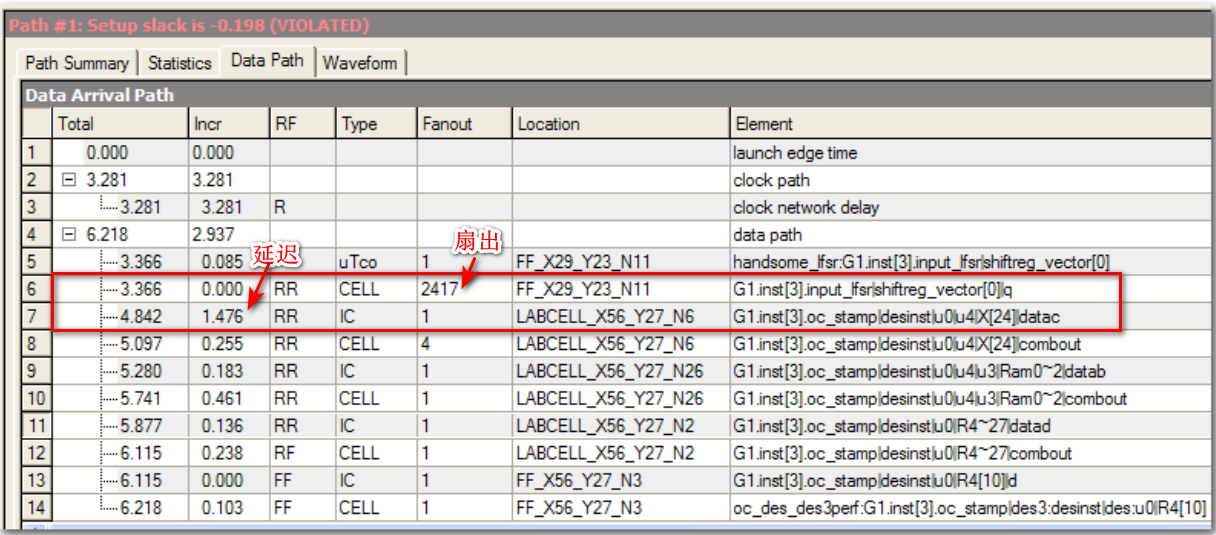
可以看出,第一个寄存器的 IC(InterConnect) 延迟为 1.476ns,该寄存器的扇出为2417。
2、复制寄存器如何优化时序?
一个常见的误解是,高扇出网络之所以延迟高,是因为单个驱动承受的负载很大。虽然对于 ASIC 是这样的道理,但对于 FPGA 通常不适用。因为FPGA 架构是高度重缓冲(highly re-buffered)的,因此每条独立的路径由都是低扇出的。
仅仅减少扇出对时序收敛没有多大帮助。 FPGA 延迟的很大一部分来自实际路径本身(指走线延迟),与其负载无关,因此复制寄存器只有在减少路径距离时才有用。
在下面的示例中,有一条从绿色寄存器到蓝色 LUT 的关键路径:
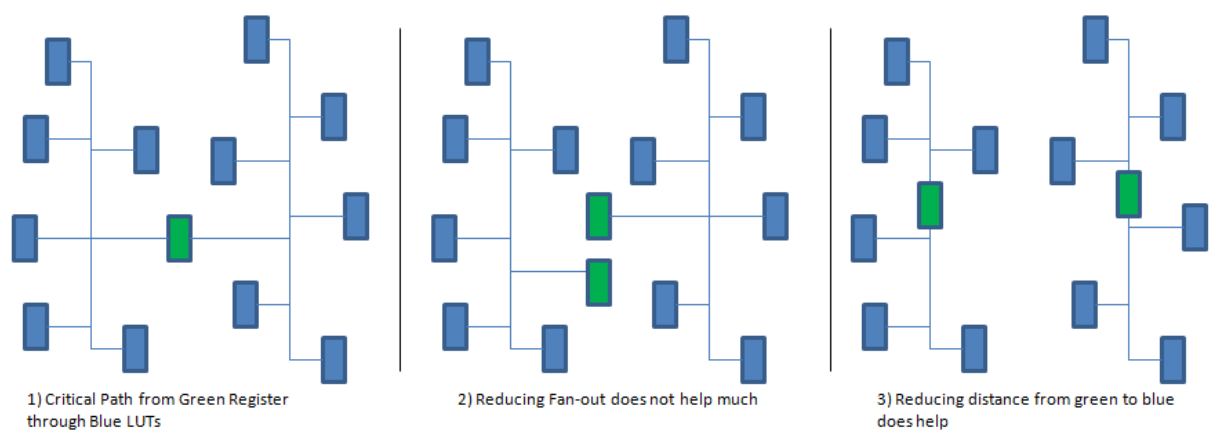
中间的图片复制了源寄存器,但复制寄存器仍布置在原始寄存器旁边。这样2个绿色源寄存器上的负载都减少了,但它们到负载的路径距离却几乎没变,所以时序上的优化微乎其微。在右边的图片中,寄存器被移动得更靠近它们所驱动的负载,这样就减少了路径距离从而优化了时序。
假设上面的蓝色节点被锁定,或者由于某些约束条件、又或者仅仅因为逻辑被拉开以驱动其他逻辑而必须放置在它们各自的左/右位置时,如果被复制的寄存器的需要在左侧驱动某些逻辑,且同时还需要在右侧驱动某些逻辑,那就无法将其布置在靠近负载的地方,这种情况下复制寄存器对于优化时序就并无多大的帮助。
另一种情况是寄存器的扇出很小,但负载都是硬核(IP)。例如某个寄存器可能会驱动 10 个 M20K 块(对应Xilinx的BRAM资源)。10的扇出并不算大,但是因为M20K是专用的底层硬件资源,寄存器不可能做到和所有M20K都靠的很近,这样到最远的M20K就会有很大的布线延迟。而通过复制寄存器的方式就可以使得每个被复制的寄存器都放置在更靠近它驱动的 M20K 的位置,从而减少布线延迟。
还有一个问题是要意识到这种方法本质上是在从前级的路径中“借裕量”。让我们看一下将源寄存器复制 4 次的情况,这种情况允许将被复制寄存器放置得更靠近每个负载。绿色寄存器是我们感兴趣的路径的源头,但它同时也是其他路径的负载:
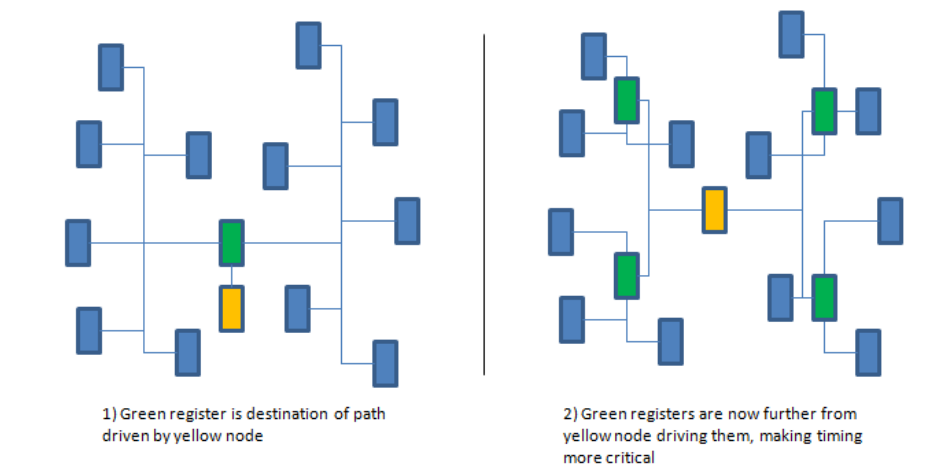
左边图1)中,绿色寄存器由黄色节点驱动。右侧的图 2) 则显示了我们将绿色寄存器复制4次后发生的情况。现在将绿色寄存器放置得离它们的负载更近,所以增加了这些路径上的裕量。相反,从黄色节点到绿色寄存器的路径变得更长,这使得这些路径上的裕量减少。
通常情况下,通向高扇出寄存器的路径上都有很多裕量,因此“借裕量”不是一个问题。在复制寄存器之前,我通常会运行:
report_timing –setup –to [get_keepers {high_fanout_reg}] –panel_name “Slack we can steal”
这条语句会返回驱动高扇出寄存器的路径上的建立时间裕量。如果明显存在充裕的裕量,那么此时就可以实现“借裕量”。如果忘记查看裕量,那么这些路径可能会在下一次通过时显示为关键路径,同时获得的收益不会像预期的那么大。
3、复制组合节点以改善性能
有时具有高扇出的节点不是寄存器而是路径中间的组合逻辑节点。同样的,开发者也希望以与解决高扇出寄存器问题相同的方式来解决此问题,即复制组合逻辑节点。问题在于复制寄存器解决问题的方法本质上是从前级借取裕量从而改善时序。如果被复制的节点不是一个寄存器而是一个组合逻辑节点,那么裕量必然也是从同一条路径上借来的,该路径的总裕量是不会增加的。
在上图中,假设绿色节点是一个具有大扇出的组合逻辑 LUT,且是设计中关键路径的一部分。如果用户将绿色节点复制四次,以便它可以像 2) 那样放置在更靠近负载的位置,则到负载的路径将变得更短,但是从黄色节点到绿色节点的路径却增长了相同的量,总体上关键路径没有改善。
有一种方法可以适配组合逻辑,它不仅需要复制高扇出的组合逻辑节点,还需要复制它前级的所有逻辑和寄存器。这只能在 RTL 中通过复制源代码中的原始寄存器以及它们之后的所有逻辑来完成。
4、复制寄存器的三种方法
复制寄存器有三种基本方法:
物理综合寄存器复制
最大扇出
手动逻辑复制
这个排序是基于难度的,第一个选项只不过是一个综合工具的选项,而第三个选项却需要仔细考虑如何复制寄存器以及它将驱动哪些负载。让我们从分析设计中的关键路径开始:
report_timing -to_clock { clk } -setup -npaths 500 -detail full_path -panel_name {Setup: clk}
在列出前 500 条路径后,我在 Summary of Paths 中将它们全部突出显示,然后右键单击-> Locate Path -> Chip Planner。
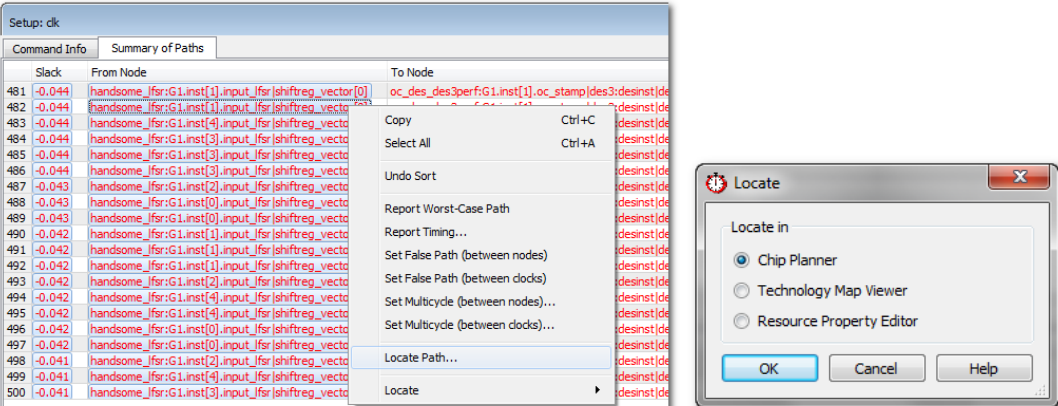
请注意,所有 500 条路径都将移动到 Chip Planner 的 Located Objects 窗口,但 Chip Planner 中只会显示最差的路径。用户可以选择单独的路径来显示它们,或者双击 Located 500 Paths 来显示它们:

双击后,我们看到所有 500 条路径。有一个扇出为 2417 的寄存器,其中最差的互连延迟为1.476ns。
(1)寄存器复制——物理综合
最简单的方法是在 Assignments -> Settings -> Physical Synthesis -> Perform Register Duplication 下找到一个选项:

对于不满足时序的设计,这应该是第一个尝试的方法,原因是它很简单。我打开所有三个选项“Perform physical synthesis for combinational logic(执行针对组合逻辑的物理优化)”,“Perform register retiming(执行重定时)”和 “Perform register duplication(执行寄存器复制)” 以尝试改进时序,而没有真正区分不同设置的作用。这些选项的唯一主要缺点是它们会增加运行时间,尽管对于正常工作量水平而言,增加的时间通常并不显着。
最后,它可能不会复制用户认为应该复制的内容。它可能没有意识到复制的重要性。它还具有各种不会重复的逻辑规则。示例包括驱动异步复位的逻辑、由无时序约束的输入端口驱动的逻辑等。物理综合不会优化这些类型的寄存器是有充分理由的,因为它们可能导致设计的行为不同于用户的意图。
我列出潜在问题只是因为好处非常明显,用户可以通过综合选项就获得他们想要的改进。
(2)最大扇出值
复制寄存器的第二个方法是最大扇出值约束。这个是众所周知的,因为它经常用于第三方综合工具。用户告诉综合工具寄存器的最大扇出是多少,一旦达到该限制,综合就会复制寄存器。对于正在分析的设计,有 5 个寄存器我们想要约束其最大扇出。我应用了 200 的最大扇出约束。由于它们的最大扇出值为 2417,因此总共有 13 个寄存器,12寄存器的个扇出为 200,另一个寄存器的扇出则为 17。
约束可以直接在 RTL 中输入,也可以在 Assignment Editor 中作为赋值输入,这两种方法各有利弊。
要通过 RTL 输入,请在 Quartus 中打开 VHDL 或 Verilog 文件并转到Edit -> Insert Template 并找到 Verilog 或 VHDL 综合属性以找到最大扇出:
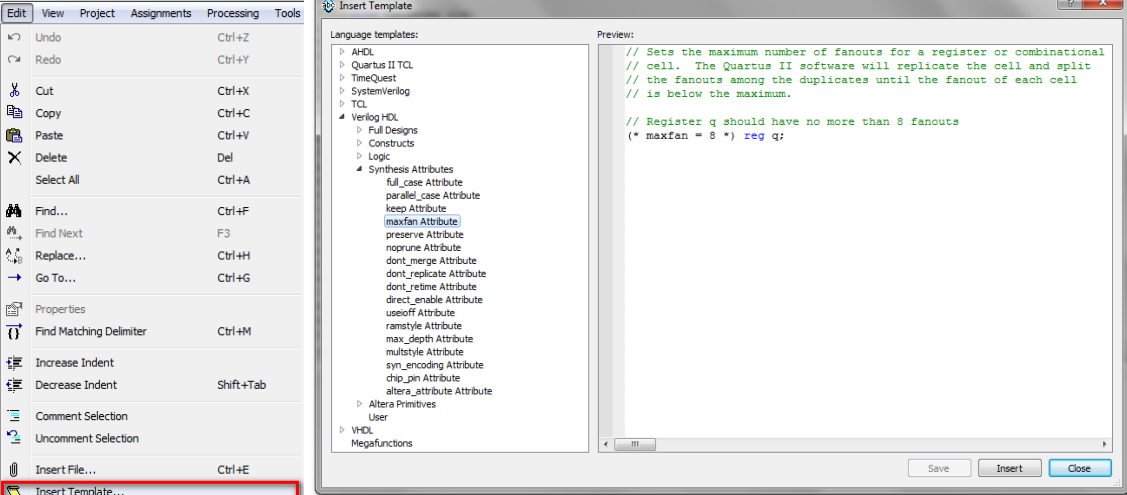
对于 Verilog,语法如下所示:
(* maxfan = 50*) reg highfanout_register;
这些方法来自自带的模板,但 Quartus 也能理解其他方法。例如,Synplify 使用 syn_maxfan 属性,而 Quartus 综合同样适用。
除了修改源代码之外的另一种选择是通过 Assignment Editor 输入约束,以便将其存储在 .qsf 中。在示例项目中,我输入了以下约束:

像这样存储在 .qsf 中:
set_instance_assignment -name MAX_FANOUT 200 -to "handsome_lfsr:G1.inst[3].input_lfsr|shiftreg_vector[0]"
set_instance_assignment -name MAX_FANOUT 200 -to "handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]"
set_instance_assignment -name MAX_FANOUT 200 -to "handsome_lfsr:G1.inst[1].input_lfsr|shiftreg_vector[0]"
set_instance_assignment -name MAX_FANOUT 200 -to "handsome_lfsr:G1.inst[2].input_lfsr|shiftreg_vector[0]"
set_instance_assignment -name MAX_FANOUT 200 -to "handsome_lfsr:G1.inst[4].input_lfsr|shiftreg_vector[0]"
编译后,其中一个寄存器变成十三个独立的寄存器,名称如下:
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_1
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_2
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_3
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_4
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_5
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_6
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_7
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_8
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_9
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_10
handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]~SynDup_11
第一个寄存器扇出为 17,其余寄存器扇出为 200。
(3)手动逻辑复制
最后一个选项是手动逻辑复制。这通常是最困难的选项,但同时也给了用户更多的设计自由。它们不仅控制复制哪些寄存器,而且控制每个复制寄存器扇出的负载。最常见的情况是寄存器扇出以分离层次结构。
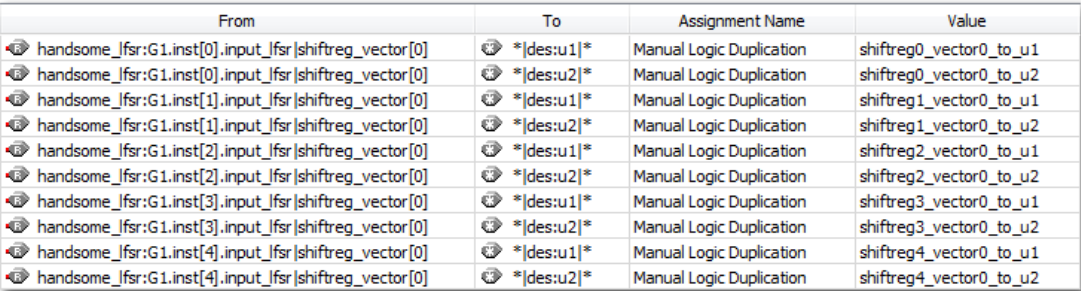
同样,有两种方法可以进行此设置。它可以在 RTL 中或通过将约束存储在 .qsf 中的 Assignment Editor 完成。让我们先看看 Assignment Editor 的例子。该方法被称为手动逻辑复制。 From 列要有有被复制的原始寄存器的名称。 To 列包含一个通配符,表示被复制寄存器将驱动哪些负载,而 Value 则包含新的寄存器名称:
From = 高扇出寄存器名称
To = 被复制寄存器将驱动的节点的通配符
Assignment Name = 手动逻辑复制
Value = 新寄存器的名称
在示例设计中,查看时序报告,我注意到高扇出寄存器驱动了三个不同的层次结构。因此,我想为两个层次结构分别创建两个副本,将原始寄存器留给第三个层次结构。由于这个高扇出寄存器在设计中存在五次,这意味着需要进行 10 次复制:
像这样存储在 .qsf 中:
set_instance_assignment -name DUPLICATE_ATOM shiftreg0_vector0_to_u1 -from "handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]" -to "*|des:u1|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg0_vector0_to_u2 -from "handsome_lfsr:G1.inst[0].input_lfsr|shiftreg_vector[0]" -to "*|des:u2|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg1_vector0_to_u1 -from "handsome_lfsr:G1.inst[1].input_lfsr|shiftreg_vector[0]" -to "*|des:u1|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg1_vector0_to_u2 -from "handsome_lfsr:G1.inst[1].input_lfsr|shiftreg_vector[0]" -to "*|des:u2|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg2_vector0_to_u1 -from "handsome_lfsr:G1.inst[2].input_lfsr|shiftreg_vector[0]" -to "*|des:u1|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg2_vector0_to_u2 -from "handsome_lfsr:G1.inst[2].input_lfsr|shiftreg_vector[0]" -to "*|des:u2|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg3_vector0_to_u1 -from "handsome_lfsr:G1.inst[3].input_lfsr|shiftreg_vector[0]" -to "*|des:u1|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg3_vector0_to_u2 -from "handsome_lfsr:G1.inst[3].input_lfsr|shiftreg_vector[0]" -to "*|des:u2|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg4_vector0_to_u1 -from "handsome_lfsr:G1.inst[4].input_lfsr|shiftreg_vector[0]" -to "*|des:u1|*"
set_instance_assignment -name DUPLICATE_ATOM shiftreg4_vector0_to_u2 -from "handsome_lfsr:G1.inst[4].input_lfsr|shiftreg_vector[0]" -to "*|des:u2|*"
另一种选择是在源代码中复制寄存器。这意味着在 RTL 中创建与原始寄存器具有相同行为的寄存器,并让它们驱动预期负载。许多用户手动完成此操作,结果却被 Quartus 阻挠,Quartus 默认合并所有重复的寄存器。这种情况有几种解决方法:
阻止 Quartus 综合时合并设计中的任何重复寄存器。这可以在 Assignments -> Settings -> Analysis & Synthesis -> More Settings -> Remove Duplicate Registers 下完成,并将其设置为 Off。我通常不推荐这样做,因为大多数设计都有大量意外的重复寄存器,删除它们往往会得到更好的结果。这就是此选项默认打开的原因。
防止 Quartus 综合时删除特定层次结构中的重复寄存器。这可以通过选择寄存器被复制的层级(或在其上方的层级)并右键单击 Locate in Assignment Editor 来完成。然后从top Filter 复制层次结构名称并将其粘贴到 To 列中。最后,选择名为 Remove Duplicate Registers 的 Assignment Name,并将其设置为 Off。

除了赋值给层次结构,Remove Duplicate Registers = Off 也可以直接赋值给寄存器
最后一个选项是在 RTL 中应用 dont_merge 属性。这可以以类似于最大扇出约束的方式添加,并且通常有助于使用 Quartus 文本编辑器中的编辑 -> 插入模板。
所以对于 Verilog,语法如下所示:
(* dont_merge *) reg highfanout_register;
将 don't_merge 添加到代码中的好处是它将重复保留在 RTL 中。其他方法结合使用复制 RTL 中的逻辑,同时赋值以防止合并这些重复项的综合是通过项目赋值进行的。当然,这两种方法各有利弊……
5、在 HDL 中复制与 Assignment Editor
正如刚才所示,最大扇出和手动逻辑复制策略可以在 RTL 中完成,也可以通过Assignment Editor完成,这些分配存储在 .qsf 中。两者各有利弊,我将简要讨论。以下是一些问题:
(1)可移植性
当在 HDL 中复制时,它的可移植性非常好。设计层次结构可以改变,HDL 可以很方便移动到新的设计、项目等。当赋值存储在 .qsf 中时,用户必须要在移植时同时将它们转移到新项目中。如果寄存器的层次结构发生变化,他们必须要修改赋值(通配符可以帮助解决这个问题)。我看到用户进行了影响层次结构的设计更改,发现时序变得更糟,因为他们忘记修改 .qsf 中的赋值路径。在 RTL 中进行复制可以解决这个问题。
(2)不依赖某个特定的平台
许多用户都希望他们的 HDL 尽可能不依赖某个特定的平台,从而实现跨平台移植,这使得他们在开发中尽量避免添加像”max fan-out values“等综合属性。虽然我同意这个目标,但我发现赋值非常不引人注目,当使用不理解属性的综合工具时,它们通常会忽略赋值但却不会出错。
(3)读取方式
当用户修改 RTL 时,更容易看到他们并不寻找的赋值。例如,如果他们想要更改寄存器名称,他们会在其旁边看到赋值,并且一定会保留它。如果它在 .qsf 中,用户可能不知道寄存器被复制,并且通过更改名称来停止复制。对于想要查看“所有赋值”的用户来说,搜索数百个 HDL 文件可能很困难,而打开 .qsf 并在赋值上进行搜索非常简单。总而言之,在 HDL 或 .qsf 中放置赋值可以以不同的方式读取,用户必须决定什么对他们来说才是重要的。
(4)复制组合逻辑
在Assignment Editor 中的手动逻辑复制赋值只会复制寄存器。通过复制 RTL 中的寄存器,用户还可以复制下游组合逻辑,这可能是时序收敛所必需的。例如,假设一个状态机创建一个组合控制信号,该信号驱动两个 DDR3 接口,一个在器件顶部,另一个在底部,并且这些路径由于必须经过的距离过长而始终无法时序收敛。用户可以在 HDL 中复制该信号的状态机和所有控制逻辑,允许将一个实例放置在顶部 DDR3 内核附近,另一个实例则放置在底部附近。这种寄存器和逻辑的复制只能在 RTL 中完成。
6、结果
关键路径从一个扇出为 2417 的寄存器开始。这是基础编译,我从中尝试了3种不同的方法,物理综合寄存器复制,每个寄存器上的最大扇出 200,以及手动逻辑复制。
(1)Base Compile
Slack: -198ps
TNS: 14.439ns
Failing Paths: 413
Note: TNS = Total Negative Slack, 负的时序裕量之和。
(2)Physical Synthesis – Register Duplication
Slack: -198ps
TNS: 14.439ns
Failing Paths: 413
分析:这些结果与Base Compile 相同,因此Register Duplication 没有做任何事情。我将此提交给软件以找出原因,答案是需要复制的寄存器由输入端口驱动,并且没有时序赋值。因此,如果寄存器被复制,每个被复制寄存器将在不同时间对输入进行采样,并可能向下游逻辑发送不同的值。为了安全起见,物理综合不会复制寄存器。这是一件非常好的事情,因为它可能会破坏设计,但指出了物理综合没有来自用户的输入的问题,因此用户对发生的事情的控制较少。
作为测试,我在需要复制的寄存器之前添加了一个寄存器。这允许物理综合复制寄存器,并得到与以下最大扇出结果非常相似的结果。
(3)Max Fan-out of 200(Assignment Editor)
Slack: -118ps
TNS: 0.637ns
Failing Paths: 20
分析:虽然裕量没有改善太多,但失败路径的数量和 TNS 得到了相当大的改善。
(4)Manual Logic Duplication(Assignment Editor)
Slack: -49ps
TNS: 0.126ns
Failing Paths: 4
分析:这个流程只对每个寄存器做了两次复制,但给出了最好的结果。这是最困难的,不仅在于进行赋值,而且在于检测信号扇出到三个不同的层次结构。
最后再来看一下不同流程中的关键路径:
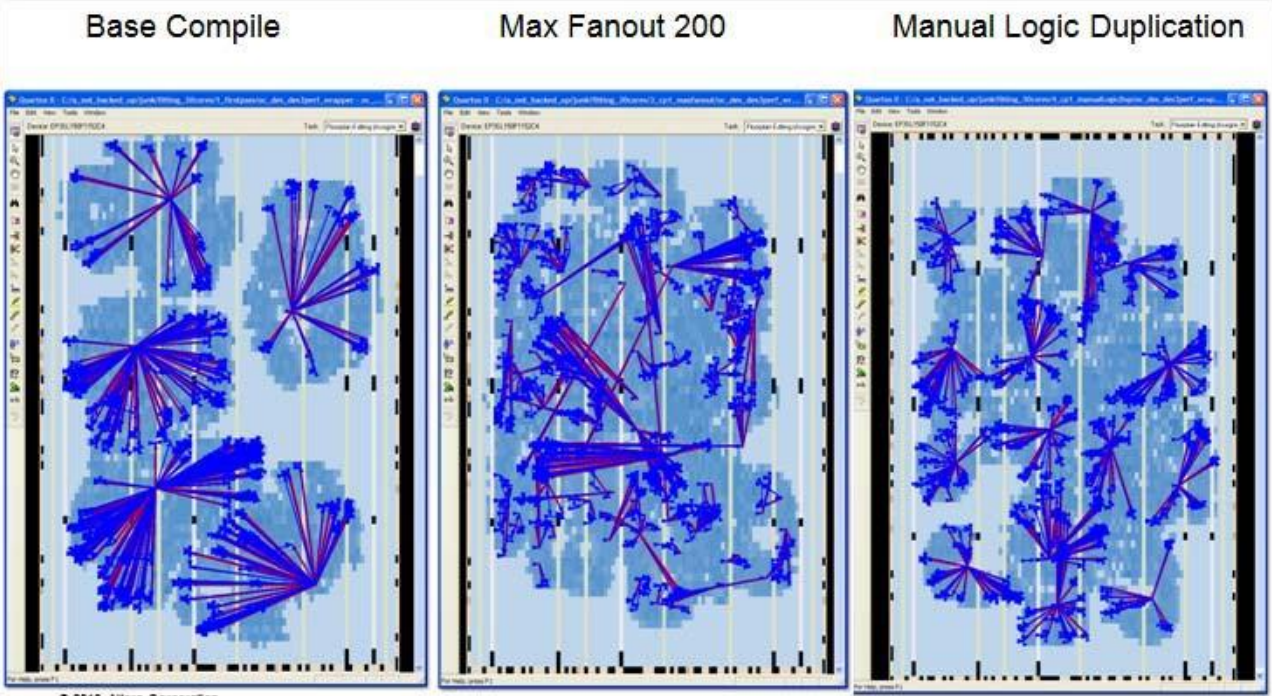
Base Compile显示出有 5 个高扇出寄存器,以及它们到负载的最长路径。max fan-out constraint显示了许多较小的扇出,但它们也更加随机。最后,manual logic duplication 创建了 15 个不同的组,这些组更小且更受控制,模仿了自然的设计层次结构。
7、总结
在这个设计中,虽然寄存器复制有帮助,但总的改进只有大约 150ps。我见过比这更大的改进,但寄存器复制不会带来巨大的时序优化。这种设计也有些独特,因为所有关键路径都来自高扇出寄存器。在大多数设计中,还有其他路径难以满足时序要求。我已经看到,复制寄存器可以让综合工具专注于其他路径,并允许高扇出寄存器的负载移动到简化其他逻辑时序的位置,从而改善整体设计的时序。寄存器复制不是时序收敛的完美技巧,但它通常都挺有用的,希望通过本指南,能让更多用户受益。
8、参考
主要参考Ryan Scoville的《Register Duplication for Timing Closure》。
📣博客主页:wuzhikai.blog.csdn.net
📣本文由 孤独的单刀 原创,首发于CSDN平台🐵
📣您有任何问题,都可以在评论区和我交流📞!
📣创作不易,您的支持是我持续更新的最大动力!如果本文对您有帮助,还请多多点赞👍、评论💬和收藏⭐!

![[GXYCTF2019]BabysqliV3.0](https://img-blog.csdnimg.cn/b65c232e6f3e4b169994eefa6b42bee2.png)