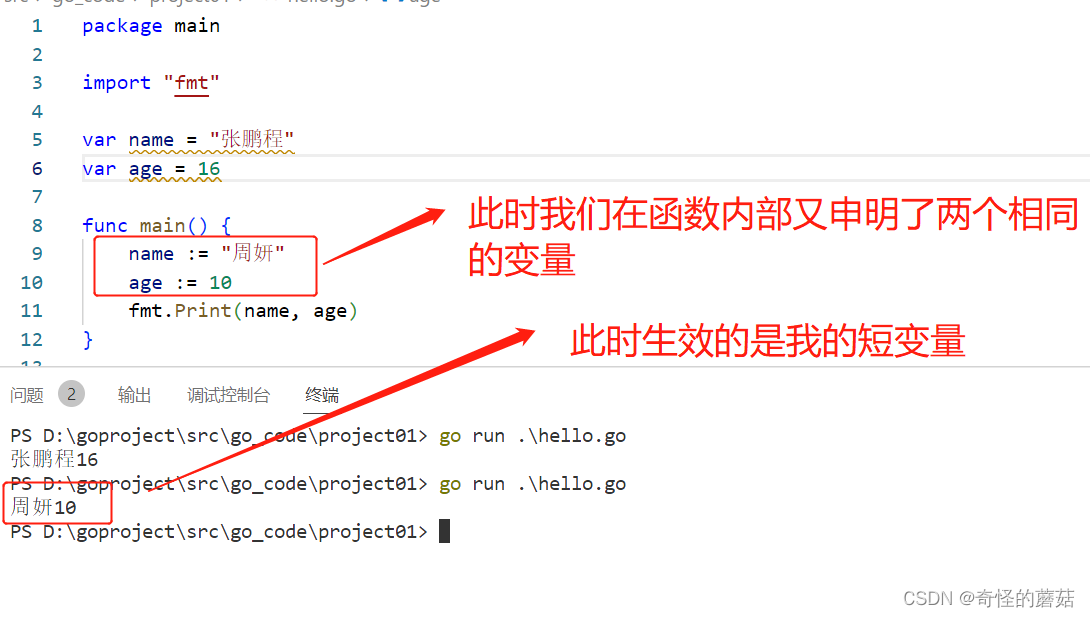
目录
Thread
线程的创建
线程的常见属性
中断线程
等待线程
休眠线程
线程的状态
多线程相比于单线程的优势
Thread
在Java中操作多线程,最常用的类就是Thread。
Thread 类是 JVM 用来管理线程的一个类,换句话说,每个线程都有一个唯一的 Thread 对象与之关联。Thread是java. lang下面的类,所以不需要import别的包。每个Thread 的对象就对应到系统中的一个线程(也就是一个PCB)
线程的创建
1. 继承Thread,重写 run 方法
class MyThread extends Thread{
@Override
public void run() {
while (true)
{
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class ThreadDemo1 {
public static void main(String[] args) {
Thread thread = new MyThread();
thread.start(); //多线程
while (true){
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
上述代码中,thread.start 表示创建一个新的线程,也就是调用操作系统的API,通过操作系统内核创建新线程的PCB,同时把要执行的指令交给这个PCB(线程是PCB描述的);新的线程负责运行 run() 方法,当PCB被调度到 CPU 上执行的时候,也就到了线程 run 方法中的代码了;
需要注意的是:start 并没有调用 run 方法,只是创建了新的线程,由新的线程来执行 run ,当 run 方法执行完了之后,新的这个线程就会自动销毁。要注意此处 start 和 run 的区别,start 是真正创建了一个线程,每一个线程都是一个独立的执行流,而run只是描述了线程要干的活;如果是在main 中直接调用 run 方法,那此时就没有创建新线程,而只有 main 一个线程在执行。
同时 new Thread 对象操作是不创建线程的,在调用 start 才是创建线程的时候。
在操作系统中,操作系统调度线程的时候,是 "抢占式执行" ,具体哪个线程先执行,哪个线程后执行,都是取决于操作系统调度器的具体实现策略。
对于线程安全问题,主要原因也就是这里的 "抢占式执行" "随即调度"
在上述代码中,就包含有两个线程,一个是主线程 main,还有一个是 thread;当我们运行上诉代码的时候,通过jdk自带的工具 jconsole 来查看当前的程序中包含有几个线程

从中我们看出,是包含有主线程 main 和 创建的线程 thread 的。其他的线程便是在这个进程中其他的线程,包括JVM自带的线程等。
当我们运行的时候:
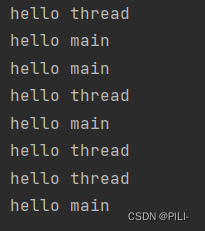
运行结果也说明了,两个线程是并发运行,对于线程 main 和 线程 thread 谁先执行,后执行,我们也是不得而知的。
2. 实现 Runnable 接口
class MyRunnable implements Runnable{
//Runnable作用:是描述一个 “ 要执行的任务 ” ,run方法就是任务的执行细节
@Override
public void run() {
System.out.println("hello thread");
}
}
public class ThreadDemo2 {
public static void main(String[] args) {
//这只是描述了一个任务
Runnable runnable = new MyRunnable();
//把任务交给线程来处理
Thread thread = new Thread(runnable);
thread.start();
}
}
3. 使用匿名内部类,继承 thread
这种写法本质上和第一种是一样的。
1. 创建一个 Thread 的子类,子类没有名字,所以是"匿名"
2. 创建了子类的实例,并且让 thread 引用指向该实例
public class ThreadDemo3 {
public static void main(String[] args) {
Thread thread = new Thread(){
@Override
public void run() {
System.out.println("hello thread");
}
};
thread.start();
}
}4. 使用匿名内部类,实现 Runnable
这种写法本质上和2是一样的
此处是创建了一个类,实现 Runnable ,同时创建了类的实例,并且传给了 Thread 的构造方法
public class ThreadDemo4 {
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello thread");
}
});
thread.start();
}
}5. 使用 Lambda 表达式
这也是我们最常用的方式 ,把要执行的任务用 lambda 表达式来描述,直接把 lambda 传给 Thread 构造方法。
(函数参数)->{ 函数体 }
public class ThreadDemo5 {
public static void main(String[] args) {
Thread thread = new Thread(()->{
System.out.println("hello thread");
});
thread.start();
}
}所以说,线程常见的构造方法也就是以下几种:
|
Thread()
|
创建线程对象
|
|
Thread(Runnable target)
|
使用
Runnable
对象创建线程对象
|
|
Thread(String name)
|
创建线程对象,并命名
|
|
Thread(Runnable target, String name)
|
使用
Runnable
对象创建线程对象,并命名
|
一般线程的默认名就是 thread-0 这类的,例如刚刚看的线程名就是 Thread-0

线程的常见属性
| 属性 | 获取方法 |
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 |
isInterrupted()
|
1. ID是线程的唯一标识,不同线程之间不会重复。
2. 名称表示构造方法中起的名字,一般系统会以thread-n的方式命名。
3. 状态表示线程所处的情况,后序会讲解。
4. 优先级高的线程理论上是会更容易被调用
5. 后台线程(守护线程):不会阻止进程结束,后台线程工作没做完,进程也是可以结束的;前台进程,是会阻止进程结束的,前台进程的工作没做完,进程是结束不了的。
需要注意的是:JVM会在一个进程中的所有非后台线程结束后,才会结束执行。
代码里手动创建的线程,默认都是前台线程,包括 main 主线程,其他 jvm 自带的线程一般都是后台的,也可以手动 setDaemon 将其设置为后台线程。
6. 是否存活,就可以理解为 run 方法是否运行结束了。
在调用 start 之前,调用该方法结果为false,在执行结束后,结果也为false,执行过程中为true。因为在内核中线程的 run 执行完之后,线程就销毁了,PCB也随之释放。但thread这个对象还是存在的,不一定被释放了。
7. 中断下文会进行描述。
Thread.currentThread(); 表示获取当前线程。比如在thread中被调用就是获取到 thread线程。是一个静态方法,类似于 this 。
public class ThreadDemo17 {
public static void main(String[] args) {
Thread thread = new Thread(()->{
System.out.println(Thread.currentThread().getName() + "还在执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "执行结束");
});
System.out.println("name: " + Thread.currentThread().getName());
System.out.println("id: " + Thread.currentThread().getId());
System.out.println("state: " + Thread.currentThread().getState());
System.out.println("priority: " + Thread.currentThread().getPriority());
System.out.println("Daemon: " + Thread.currentThread().isDaemon());
System.out.println(Thread.currentThread().getName() + " " + Thread.currentThread().isAlive());
System.out.println(Thread.currentThread().getName() + " " + Thread.currentThread().isInterrupted());
System.out.println(thread.getName() + " " + thread.isAlive());
thread.start(); //此时线程thread才真正创建
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(thread.getName() + " " + thread.isAlive());
}
}
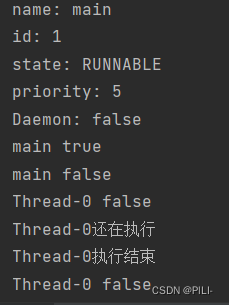
从执行结果来看,也是可以看出两个线程之间的并发执行,和对应属性的变化。(添加 sleep 方法是为了调整好执行顺序来查看执行状态)
中断线程
要注意:线程中断,并不是让线程立即就停止,而是通知线程应该停止了。而线程是否真的停止了,取决于具体的代码实现。
所以说,会有三种不同的情况:
1. 通知线程中断,线程就立即中断了;
2. 通知线程中断,线程可能要过一会,等执行完某个语句,再进行中断;
3. 通知线程中断,线程不予理会,继续执行;
1.使用标志位来控制线程是否要停止
public class ThreadDemo7 {
private static boolean flag = true;
public static void main(String[] args) {
Thread thread = new Thread(()->{
while(flag){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("hello");
}
});
thread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 在主线程里就可以随时通过 flag 变量的取值,来操作 t 线程是否结束
flag = false;
}
}

正如执行结果所示,这段代码是通过修改变量 flag 的值来控制线程的中断,因此,线程是否中断,什么时候中断,是取决于线程内部代码实现的。但这种自定义变量来控制线程中断,有时候没办法及时响应,因为有些情况 sleep 的休眠时间过长。
2.使用Thread自带的标志位,进行判定
thread.interrupt();
就表示通知 thread 线程要中断了,在main线程中调用,就相当于 main 通知 thread 应该中断了。
public class ThreadDemo8 {
public static void main(String[] args){
Thread thread = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
thread.interrupt();
}
}
!Thread.currentThread().isInterrupted()
当线程被通知中断的时候,这条语句输出为false;当线程没有被通知中断的时候,语句输出为 true。

从执行结果中可以看出, 线程 thread 输出三次之后,主线程 main 调用 thread.interrupt() 使线程thread收到中断信号,要注意,此时线程 thread 会发生两件事:
1.改变线程内部标志位,也就是 Thread.currentThread().isInterrupted() 变为 true ;
2.如果线程在 sleep ,就会触发异常,也就执行e.printStackTrace();语句,把 thread 线程唤醒,让线程 thread 从 sleep 中提前返回。正如执行结果所示。
但是此时,线程 thread 还是继续循环执行,这是因为,在sleep被唤醒的时候,还会做另一件事:清空标志位,也就是把刚才设置标志位为 true,现在再设置为 false。因此thread也就继续循环输出了;
这样就再次说明了一点:线程中断,不是真的中断,而只是通知线程应该中断了,具体会不会中断,还得看具体的代码实现。
所以,这就是线程中断的第一种情况,通知 thread 线程中断了,但是线程忽略了中断请求。
下面介绍第二种,通知线程中断,线程立即中断。
public class ThreadDemo8 {
public static void main(String[] args){
Thread thread = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
break; //加上break: 线程t立即响应你的中断请求
}
}
});
thread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
thread.interrupt();
}
}第三种,线程收到中断请求后,过一会再进行中断。
public class ThreadDemo8 {
public static void main(String[] args){
Thread thread = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
try { //理解成稍后再进行中断
Thread.sleep(2000); //这里也可以是具体的实现代码
} catch (InterruptedException ex) {
throw new RuntimeException(ex);
}
break;
}
}
});
thread.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
thread.interrupt();
}
}
因此,interrupt 只是告诉线程应该中断了,但线程并不是真的就中断了,具体是要取决于代码实现的。
这里还有另一种情况,就是如果线程 thread 不在 sleep ,此时外部调用 interrupt 通知线程 thread 中断,标志位状态变为 true,这个时候线程 thread 还是会正常执行的,因为 interrupt 方法只是通知线程中断,但并不是立刻停止执行,所以它还是会继续往下执行,直到执行到 sleep,这个时候抛出异常,如果此时标志状态为 true ,表示的是这个线程处于中断状态,就无法处理这个异常,所以会把中断标志重置为 false ,然后去处理异常。
总之,还是那句话,调用 interrup 之后,线程不是立马就中断了,而是要看具体的代码实现。
等待线程
thread.join();
线程是一个随机调度的过程,等待线程,本质上,就是在控制两个线程的结束顺序。
public class ThreadDemo9 {
public static void main(String[] args) {
Thread thread = new Thread(()->{
for (int i = 0; i < 3; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
System.out.println("join 之前");
try {
thread.join(); //等待thread执行完
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("join 之后");
}
}

上述代码中,在 main 线程中调用 thread.join ,此时 main 线程会进入阻塞等待状态,本质上就是 main 线程等待 thread 线程执行完了之后再继续执行。
在执行完 thread.start() 后,thread 线程和 main 线程就开始并发执行。main线程执行到 thread.join() 的时候,就开始阻塞了,一直阻塞到 thread 线程执行结束, main 线程才会从 join 中恢复回来,才能继续往下执行。thread 线程肯定是比 main 先结束的,从执行结果中也可以看出。
如果是在执行 join 的时候,thread 已经结束了,join 就不会阻塞,而是立即返回,继续向下执行。
对于等待线程,死等是不常见的,这会影响开发效率,所以一般都会设置最大时间数。
|
public void join()
|
等待线程结束
|
|
public void join(long millis)
|
等待线程结束,最多等
millis
毫秒
|
|
public void join(long millis, int nanos)
| 等待线程结束,最多等 millis 毫秒+nanos纳秒 |
休眠线程
休眠线程,本质上就是让这个线程不参与调度了。(不去 CPU 上执行)也可以理解为进入阻塞状态。
|
public static void sleep(long millis)throws InterruptedException
|
休眠当前线程
millis毫秒
|
| public static void sleep(long millis, int nanos) throws
InterruptedException
| 休眠当前线程 millis毫秒+nanos纳秒 |
在操作系统内核中,会有就绪队列和阻塞队列,我们前面也讲过 PCB 是使用链表来组织的,但也并不具体,实际的情况可能不是一个简单的链表,而是以链表为核心的数据结构。
在就绪队列中,PCB都是 "随叫随到" 的,处于就绪状态,而操作系统每次需要调度一个线程去执行的时候,就从就绪队列中进行挑选。
当线程A调用 sleep ,A就会进入休眠状态,也就把线程A从就绪队列中转移至阻塞队列中,在阻塞队列中的PCB,都是 "阻塞状态" ,暂时不参加CPU的调度执行。
一旦线程进入阻塞状态,对应的PCB就进入阻塞队列了,此时就暂时无法参与调度了。
比如线程A sleep(1000) ,对应的PCB就要在阻塞队列中待1000ms。
当这个PCB回到就绪队列中,会被立即执行吗?
虽然是 sleep(1000) ,但是实际上考虑到调度的开销,对应的线程是无法在唤醒后立即执行的,实际上的时间间隔大概率是要大于 1000ms 的。
线程的状态
状态是针对当前的线程调度的情况来描述的。
1. NEW:创建了 Thread 对象,但是还没有调用 start (内核里还没有对应的PCB)
2. TERMINATED:表示内核里的PCB已经执行完毕了,但是 Thread 对象还在。
3. RUNNABLE:可运行的。包括两种状态:正在CPU上运行的,在就绪队列里,随时可以去CPU上运行的。
4. WAITING:wait / join(后面进行讲解)
5. TIME_WAITING:线程处于 sleep 中,当 sleep 时间到了,就解除阻塞。
6.BLOCK:由于加锁操作的阻塞,获取到锁的时候,解除阻塞(后面进行讲解)
4,5,6 是趋于不同原因的阻塞状态,表示线程PCB正在阻塞队列中,后序会一一介绍。
TERMINATED:一旦内核里的线程PCB销毁了,此时代码中的 thread 对象也就没意义了,内核的线程释放的时候,无法保证代码中 thread 对象也立即释放,因此就需要 TERMINATED 这个特定的状态,来把 thread 这个对象标识为 "无效" 此时这个对象也是不能再次 start 的,一个线程只能 start 一次。虽然此时的对象无法通过多线程来做一些事,但对象还存在,还是可以调用对象的一些方法属性来进行使用。
public class ThreadDemo10 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
for (int i = 0; i < 1000; i++) {
try { //加上这一段sleep之后,在后续打印中,具体看到的是RUNNABLE还是TIME_WAITING就不一定
Thread.sleep(10); //取决于当前的 t 线程是运行到哪一个环节了
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//启动之前,获取 t 的状态
System.out.println("start之前: " + t.getState());
t.start();
for (int i = 0; i < 100; i++) {
System.out.println("t 执行中的状态:" + t.getState());
}
t.join();
//线程执行完毕之后,获取 t 的状态
System.out.println("t 结束之后:" + t.getState());
}
}

从上述代码的执行结果可以看出线程对应的状态,正如上文所讲,在 start 之前,t 线程的状态是NEW;
在 t 线程执行完后,线程销毁,但 t 对象还在,此时 t 线程的状态为 TERMINATED;
在线程 t 的执行过程中,t 的状态有两种,sleep 状态下为 TIMED_WAITING,其他情况下为RUNNABLE状态。但是相比于线程 t 在CPU上执行的时间来说,sleep(10)这个时间就太长了,因此从输出结果也可以看出,大部分的状态都在 TIMED_WAITING,如果想要两者之间的状态更均衡一些,就可以在 run 方法中引入更多的计算逻辑来增加时间消耗。
剩下的 WAITING 和 BLOCKED 后面再为大家解答~
多线程相比于单线程的优势
前面铺垫了那么多线程知识,我们现在也来感受一下多线程和单线程之间的执行速度差别。
一般我们的程序分为:CPU密集 和 IO密集
CPU密集:包含了大量的加减乘除等运算;
IO密集:涉及到读写文件,读写控制台,读写网络等;
为了减小误差,我们运算量稍微大一些,因为一般衡量执行时间的代码,让程序跑的久一些,也并不是坏事,因为线程本身调度是需要时间开销的,运算量越大,线程本身调度的时间开销相比之下就不那么明显了,也就变得可忽略不计,从而减小误差。
public class ThreadDemo11 {
public static void main(String[] args) throws InterruptedException {
//假设当前有两个变量,需要把两个变量各自自增 100亿次:典型的cup密集型的场景
//可以一个线程,先针对 a 的自增,然后再针对 b 自增
//还可以两个线程,分别对 a 和 b 自增
serial();
concurrency();
}
//串行执行:一个线程来完成
public static void serial(){
//为了衡量执行速度,加上个计时的操作
//currentTimeMillis 获取到当前系统的 ms 级时间戳
long beg = System.currentTimeMillis();
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
long b = 0;
for(long i = 0;i < 100_0000_0000L;i++){
b++;
}
long over = System.currentTimeMillis();
System.out.println("执行时间:" + (over - beg)+"ms");
}
public static void concurrency() throws InterruptedException {
//使用两个线程分别完成自增
Thread t1 = new Thread(()->{
long a = 0;
for (long i = 0; i < 100_0000_0000L; i++) {
a++;
}
});
Thread t2 = new Thread(()->{
long b = 0;
for (long i = 0; i < 100_0000_0000L ; i++) {
b++;
}
});
long beg = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
long over = System.currentTimeMillis();
System.out.println("执行时间:" + (over - beg)+"ms");
}
}

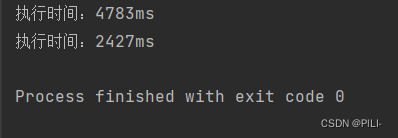
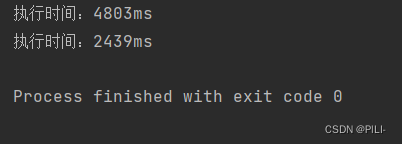
首先要注意,我们每一次执行的时间大概率都是不同的,只能说是相差不大,因为线程的随机调度。同时在获取最终时间的时候,应该在语句 t1.join 和 t2.join 后再获取,要确保 t1 和 t2 线程已经执行完。
从执行结果可以看出,多线程的情况下要比单线程的执行速度快很多,这也是因为多线程可以更充分的利用到多核心CPU资源。
所以说,多线程,在这种 CPU 密集型的任务中,就有着非常大的作用,可以充分利用多核 CPU 资源,从而加快程序的运行速度。
当然,多线程在 IO 密集型的任务中,也有着较大的作用。例如,在我们打开一些数据量比较大的游戏的时候,程序就需要进行一些耗时的 IO 操作,要加载大量的数据文件,涉及到大量的读取硬盘操作,阻塞了界面的相应,就会出现 "程序未响应" 的情况,这时候用多线程就可以有很好的改善,也就是一个线程负责 IO,一个线程负责相应用户的操作。
![[GXYCTF2019]BabysqliV3.0](https://img-blog.csdnimg.cn/b65c232e6f3e4b169994eefa6b42bee2.png)