🔥博客主页: 小羊失眠啦.
🎥系列专栏:《C语言》 《数据结构》 《C++》 《Linux》 《Cpolar》
❤️感谢大家点赞👍收藏⭐评论✍️

文章目录
- 前言
- 一、冯诺依曼体系
- 二、系统管理
- 三、进程理解
- 3.1 代码与数据
- 3.2 进程控制块
- 四、查看进程
- 4.1 ps 指令
- 4.2 top 指令
- 4.3 /proc 目录
- 4.4 父子进程
- 4.5 小结
- 五、fork 创建子进程
前言
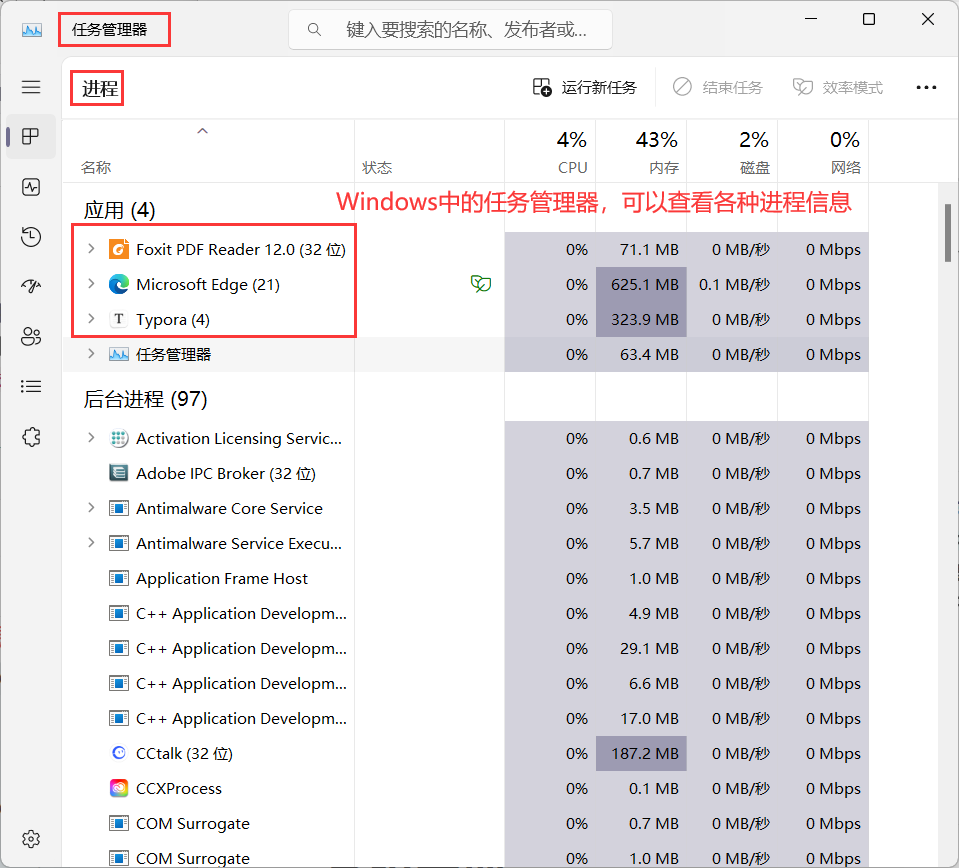
进程 是计算机中的重要概念,每个运行中的程序都有属于自己的 进程 信息,操作系统可以根据这些信息来进行任务管理,比如在我们Windows中的任务管理器中,可以看到各种运行中的任务信息,这些任务就可以称之为 进程,简单的 进程 二字后面包含着许多知识,比如为什么OS需要对任务进行管理、任务信息是如何组成的、如何创建新任务等,下面我将带大家从 冯诺依曼 结构体系开始,理解学习 进程 相关知识
一、冯诺依曼体系
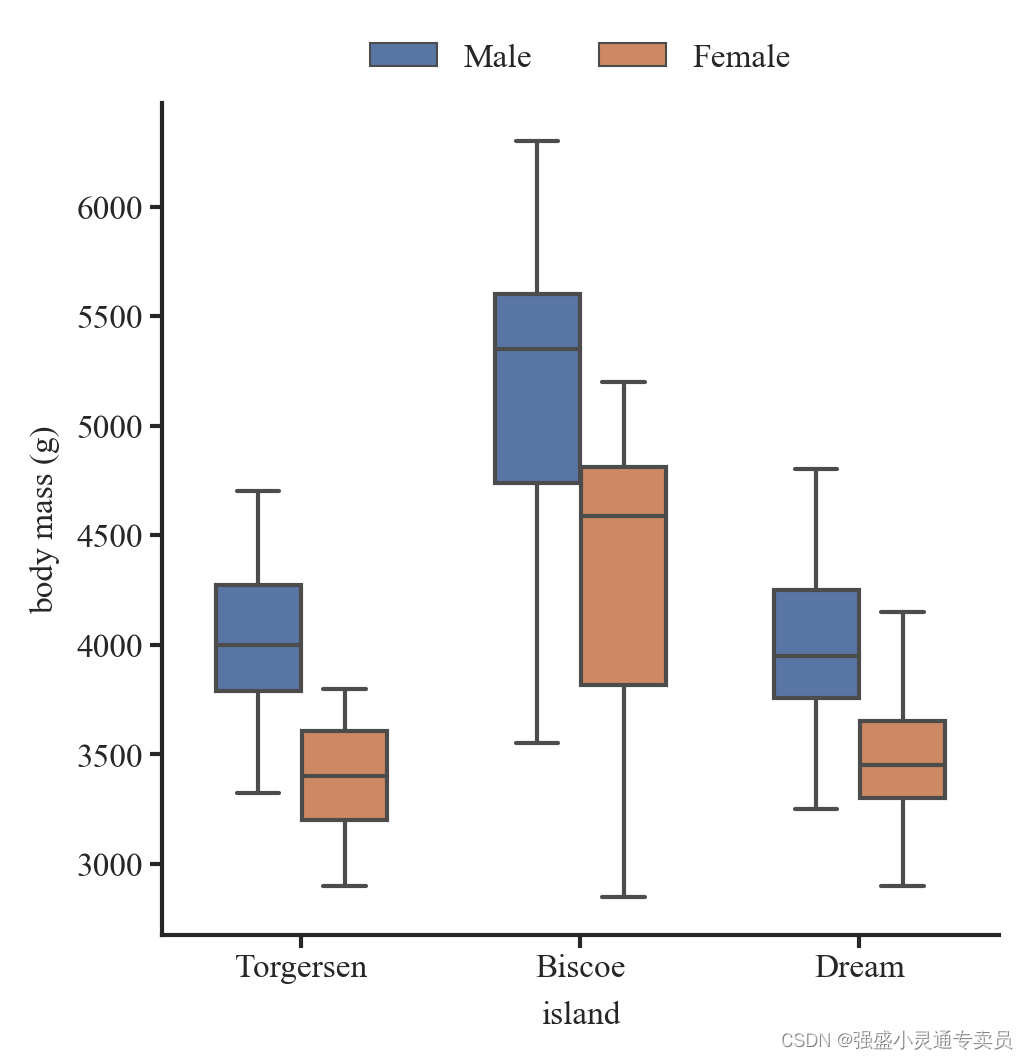
我们今天所有的计算机都离不开 冯诺依曼 体系,这位伟大的计算机科学家早在二十世纪四十年代就提出了这种结构,即计算机应由五部分组成:输入设备、存储器、运算器、控制器、输出设备
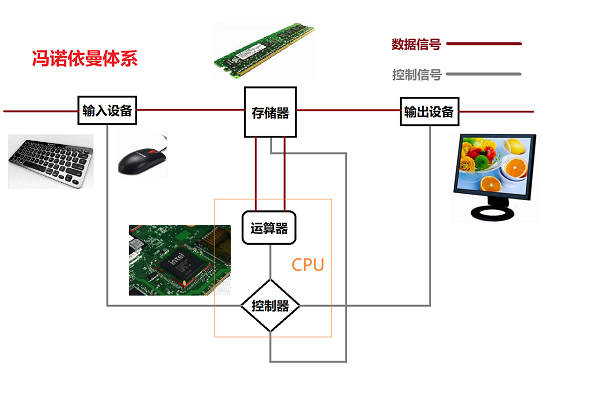
各组成部分举例:
- 输入设备:
键盘、鼠标、声卡、网卡、摄像头等 - 输出设备:
显示屏、喇叭、网卡、打印机等 - 存储器:
只读存储器、随机存取存储器 - 运算器+控制器:
CPU中央处理器
注意: 输入、输出设备 称为外围设备,即 外设,而 外设 一般都会比较慢,比如磁盘;CPU中央处理 的速度是最快的,通过与 存储器 的配合,可以做到高效率处理数据;如果没有 存储器 的存在,那么计算机的整体效率就取决于 外设,正是因为 存储器 的存在,可以对数据进行预加载,CPU 计算时,直接向 存储器 要数据就行了,效率很高。

冯诺依曼 体系的高明之处在于可以大大提高计算机的运算效率,得益于 存储器 这个关键部件
结论:
- 在数据层面,一般
CPU不和外设直接沟通,而是直接和内存(存储器)打交道
程序必须先加载到内存中,这是由硬件体系决定的 外设只会和内存打交道
二、系统管理
有了计算机体系后,就需要 操作系统(OS) 对计算机进行管理,就像一个庞大的学校中会有各种教职工,当然计算器是否好用是很大程度上取决于 操作系统 是否给力
回归正文,先说结论:操作系统 是一款进行软硬件资源管理的软件
我们普通用户无法直接与计算机中的硬件打交道,也就是说,在没有 操作系统 的情况下,我们几乎是无法使用计算机的,于是一些计算机大牛就创造出了各种好用的 操作系统
举些栗子:
- 最经典的
Unix操作系统 - 我们学习的
Linux操作系统 - 市面上流通最广的
Windows操作系统 - 高效精致的
Mac操作系统,基于Unix - 生态丰富的
Android操作系统,基于Linux - 还有很多操作系统,这里就不一一列举,或许下一个操作系统就由你创造

操作系统 管理的本质: 先描述,再组织
- 描述:通过
struct结构体对各种数据进行描述 - 组织:通过
链表等高效的数据结构对数据进行组织管理
比如在
Linux中是通过链表这种数据结构来进行数据组织的
大体逻辑:操作系统 -> 硬件驱动 -> 硬件
具体的逻辑如下图所示:

我们开发者位于 用户 这一层,开发各种功能,提供给上一层的 用户群体 使用
操作系统的目的:
操作系统是一个极其庞大的系统,操作系统通过对下管理好软硬件资源的手段,对上给用户提供良好(安全、稳定、高效、功能丰富等)的执行环境,这是操作系统的目的
注意:
-
操作系统给我们提供非常良好的服务,并不代表操作系统会相信我们,反而,操作系统不相信任何人 -
举例理解:就好比银行给我们提供良好的服务,但所有服务都是基于一个小小的柜台窗口,因为银行在为我们提供服务时要确保自身的安全,因此银行的服务是基于
窗口进行的 -
在
操作系统中也有类似的窗口,不过它被称为系统调用,也就是系统接口

三、进程理解
有了 操作系统 相关知识的铺垫后,就可以正式开始介绍 进程 了
我们可以将 操作系统 的职能分为四大板块
- 内存管理
- 进程管理
- 文件管理
- 驱动管理
本文探讨的 进程 相关知识属于 进程管理 板块
进程:
- 我们以前的任何启动并运行程序的行为,都是由
操作系统帮助我们将程序转换为进程,然后完成特定任务 - 一般课本定义:
进程是程序的一个执行实例,是正在执行的程序(这种说法不全面) - 正确定义:
进程由两边组成,分别是相关代码和数据和内核关于进程的相关数据结构
也就是说,一个 进程 应该有两部分,数据 与 信息,此处的 信息(进程控制块) 是由 操作系统 对代码和数据进行描述后生成的 信息块 ,原因很简单,方便进行管理,而这就是管理本质的体现: 先描述,再组织
我们对 进程 的相关学习是建立在 进程控制块 上的,上面包含了其对应 进程 的各种信息,下面就来学习一下 数据 与 信息 这两部分知识吧
3.1 代码与数据
数据生万物,任何一个进程都有自己的代码和数据,比如我们常见的 C语言 源文件,经过编译后生成的可执行程序中,就包含着二进制代码和其创建修改的时间、所处位置信息

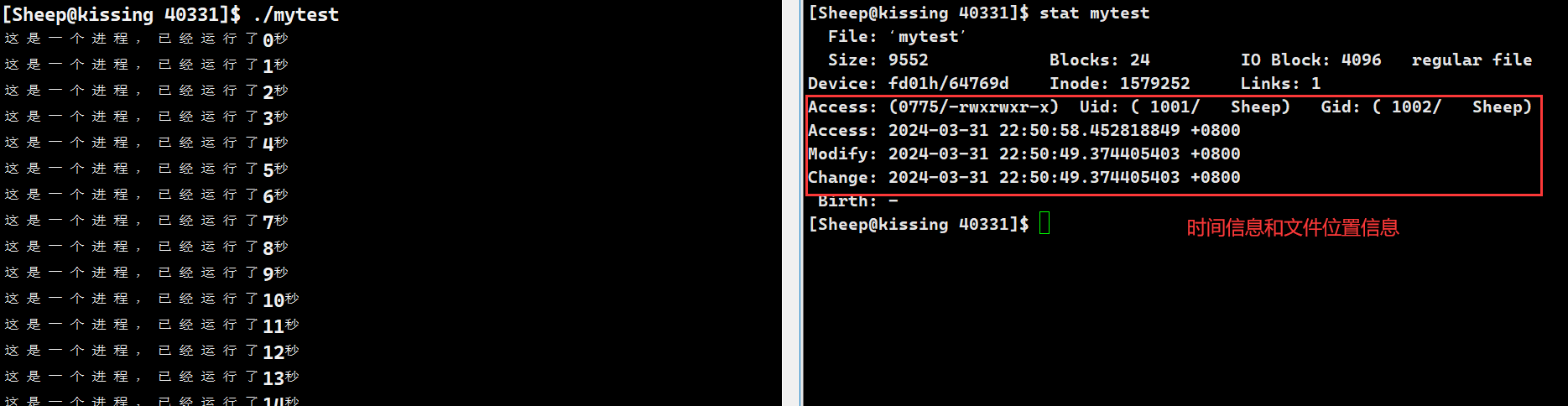
当可执行程序 mytest 运行时,各种数据就会被描述,生成相应的进程控制块
3.2 进程控制块
进程控制块即PCB(process control block),Linux 中的 PCB 是 task_struct,程序会被描述生成相应的task_struct 装载至 内存 中

进程控制块包含内容:
-
标示符: 描述本进程的唯一标示符,用来区别其他进程
-
状态: 任务状态,退出代码,退出信号等
-
优先级: 相对于其他进程的优先级
-
程序计数器: 程序中即将被执行的下一条指令的地址
-
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
-
上下文数据: 进程执行时处理器的寄存器中的数据
-
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表
-
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等
-
其他信息
注: ./可执行程序 其实就是将可执行程序加载至内存中,再执行描述+组织
四、查看进程
我们可以通过指令来查看正在运行中的进程信息
4.1 ps 指令
ps ajx | head -1 && ps ajx | grep 进程名 | grep -v grep
功能: 查看进程信息,其中利用管道进行了信息筛选,使得进程信息更加清晰

注意: 我们可以通过函数来主动查看进程的 PID
//函数:获取当前进程PID值
#include<unistd.h>
#include<sys/types.h>
pid_t getpid(void);
将程序简单编写下,就可以验证进程块中的进程信息了
#include<stdio.h>
#include<unistd.h> //Linux中睡眠函数的头文件
#include<sys/types.h>
int main()
{
int sec = 0;
while(1)
{
printf("这是一个进程,已经运行了%d秒 当前进程的PID为:%zu\n", sec, getpid());
sleep(1); //单位是秒,睡眠一秒
sec++;
}
return 0;
}

注: 当程序重新运行后,会生成新的 PID
因为查看进程的指令太长了,所以我们可以结合前面学的自动化构建工具 make ,编写一个 Makefile 文件,文件内容如下所示:
mytest:test.c
gcc $^ -o $@ -g
.PHONY:clean
clean:
rm -rf mytest
.PHONY:catP
catP:
ps ajx | head -1 && ps ajx | grep mytest | grep -v grep
其中的 make catP 指令就是我们刚刚查看 进程 的那一大串指令

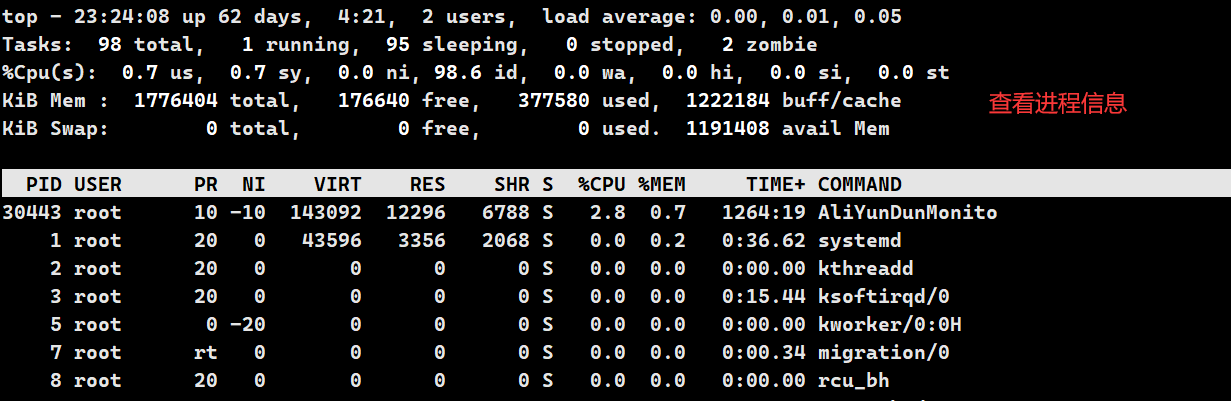
4.2 top 指令
top
这个指令之前有介绍过,相当于Windows中的 ctrl+alt+del 调出任务管理器一样,top 指令能直接调起 Linux 中的任务管理器,显然,任务管理器中包含有进程相关信息
4.3 /proc 目录
/proc/
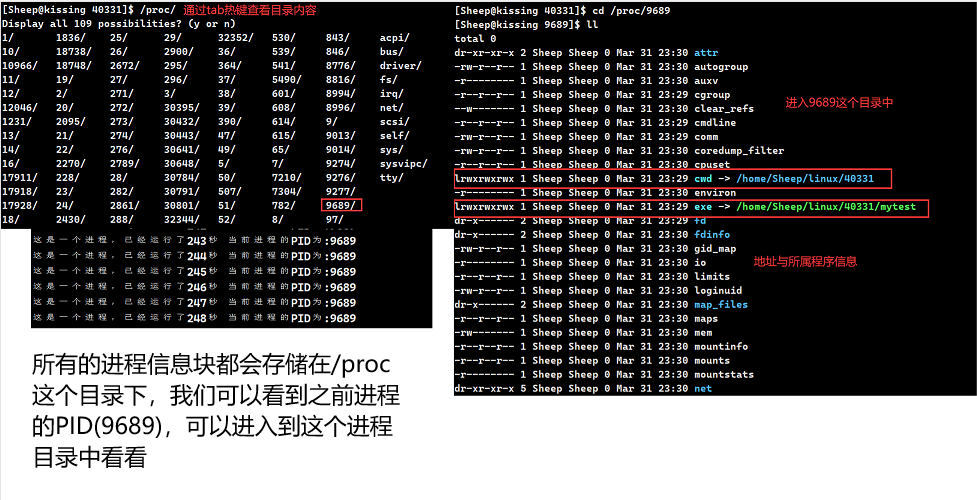
此时可以看出 PID 存在的重要性
4.4 父子进程
进程间存在 父子关系
比如在当前 bash 分支下运行程序,那么程序的 父进程 就是当前 bash 分支
其中,PID 是当前进程的ID,PPID 就是当前进程所属 父进程 的ID
我们一样可以通过函数来查看 父进程 的ID值
//函数:获取当前进程PPID值
#include<unistd.h>
#include<sys/types.h>
pid_t getppid(void); //用法跟上面的函数完全一样
同样对代码进行小修改,执行指令查看进程信息,可以得到如下结果:

感兴趣的同学可以去看看 bash 进程的目录中有什么内容
4.5 小结
简单总结一下:
- 我们可以通过
ps、top、/proc查看进程信息 - 可以利用函数查看当前进程的
PID或PPID值 - 如果指令很长,可以利用
Makefile文件 - 进程间存在父子关系,默认进程的父进程为
bash
注:
- 进程可以创建也可以销毁,通过指令
kill -9 PID可以销毁指定进程,包括bash,当然这个指令需要在新的窗口中执行 - 也可以通过热键
ctrl+c强制终止当前进程的运行
五、fork 创建子进程
/*
* 创建子进程
* 这个函数有两个返回值
* 进程创建成功时,给父进程返回子进程的PID,给子进程返回0
* 创建失败时,返回 -1
*/
int fork(void)
fork 函数是一个非常重要的函数,它能在当前进程下主动创建 子进程 ,用于程序中
编写代码如下:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
/*
* 测试fork创建子进程
* 理解fork函数的返回值
* 通过if语句进行分流
* 总结:fork创建子进程成功时,给父进程返回子进程PID,给子进程返回0,
如果失败返回-1;通过两次fork可以发现当父进程执行后,才会去执行子进程,
父子进程间存在独立性,即父进程被kill后,子进程任然可以运行,父子进程间存在写时拷贝机制,
当子进程的值发生改变时,只会作用于子进程中
*/
int main()
{
pid_t ret = fork(); //获取返回值
int val = 1; //比较值
if(ret == 0)
{
//在子进程内再创建(孙)子进程
pid_t rett = fork();
if(rett > 0)
{
while(1)
{
val = 2; //写时拷贝
printf("二代进程正在执行 PID:%d PPID:%d 比较值为:%d 地址:%p\n\n", getpid(), getppid(), val, &val);
sleep(1);
}
}
else if(rett == 0)
{
while(1)
{
val = 3; //写时拷贝
printf("三代进程正在执行 PID:%d PPID:%d 比较值为:%d 地址:%p\n\n", getpid(), getppid(), val, &val);
sleep(1);
}
}
else
printf("进程创建失败\n");
}
else if(ret > 0)
{
while(1)
{
val = 1; //写时拷贝
printf("一代进程正在执行 PID:%d PPID:%d 比较值为:%d 地址:%p\n\n", getpid(), getppid(), val, &val);
sleep(1);
}
}
else
printf("进程创建失败\n");
return 0;
}
程序运行结果如下:
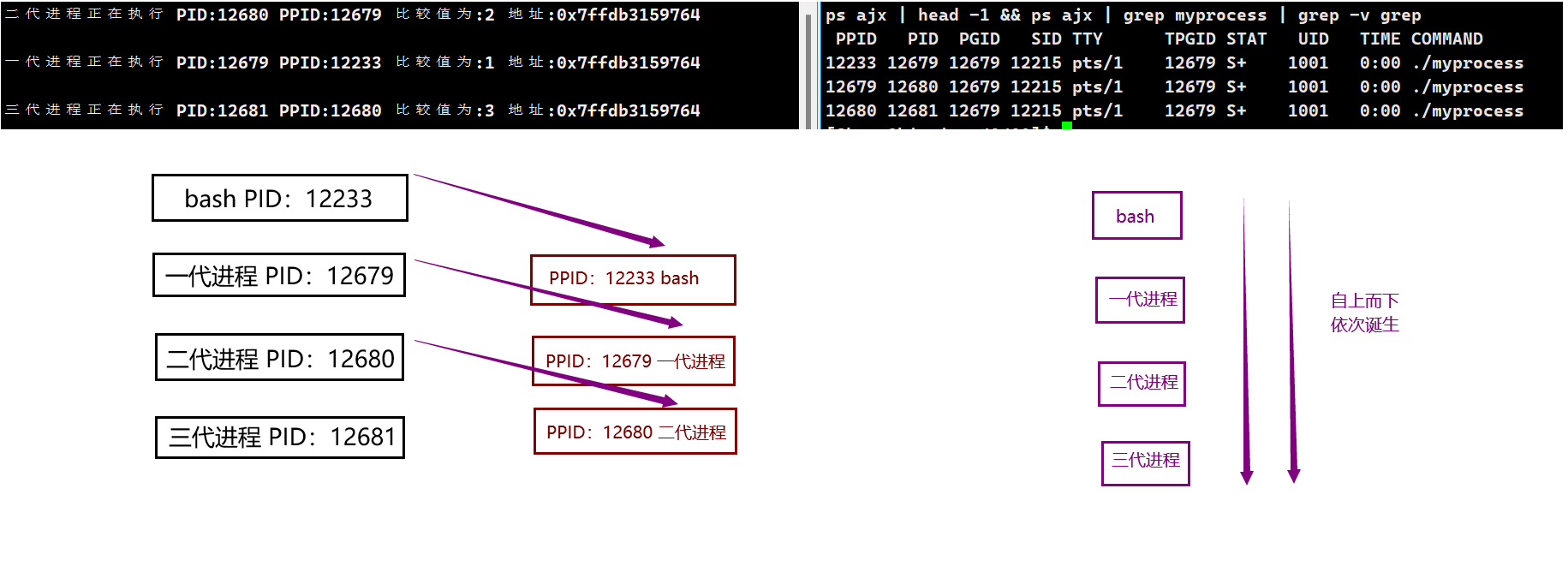
不难发现,子进程 是否出现取决于在当前进程中是否调用 fork 函数
fork函数工作原理:
fork创建子进程时,会新建一个属于子进程的PCB,然后把父进程 PCB的大部分数据拷贝过来使用,两者共享一份代码和数据
各进程间是相互独立的,包括父子进程
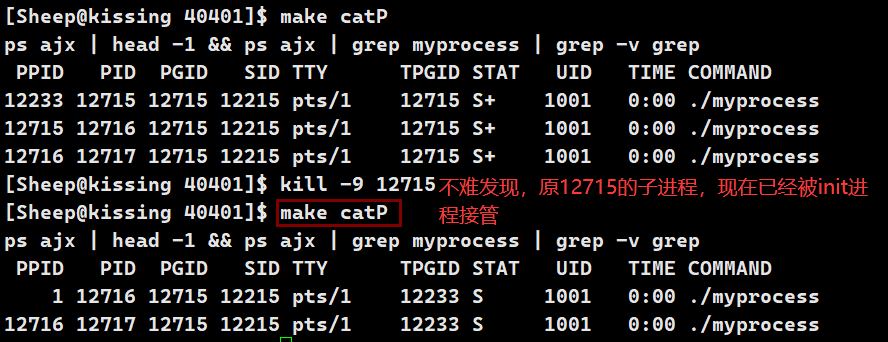
这句话的含义是当我们销毁 父进程 后,它所创建的 子进程 并不会跟着被销毁,而是被 init 1号进程接管,成为一个 孤儿进程
具体表现如下:
fork 创建子进程时还存在 写时拷贝 这种现象,即存在一个全局变量,当父进程的改变值时,不会影响子进程的值,同理子进程也不会影响父进程,再次印证 相互独立 这个现象

父子进程相互独立的原因:
- 代码是只读的,两者互不影响
- 数据:当其中一个执行流尝试修改数据时,OS 会给当前进程触发
写时拷贝机制
以上只是对 fork 函数的一个简单介绍,关于这个函数底层是如何实现的,是一件较复杂的事,限于篇幅原因,我会在以后对此函数进行补充
简单做个小结
进程小结:
bash命令行解释器本质上也是一个进程,可以被销毁- 命令行启动的所有程序,最终都会变成进程,而该进程对应的父进程都是
bash - 父进程被销毁后,子进程会变成
孤儿进程 - 进程间具有独立性,包括父子进程
- 因为
写时拷贝机制,父进程不会影响到子进程
程的值,同理子进程也不会影响父进程,再次印证 相互独立 这个现象**
父子进程相互独立的原因:
- 代码是只读的,两者互不影响
- 数据:当其中一个执行流尝试修改数据时,OS 会给当前进程触发
写时拷贝机制
以上只是对 fork 函数的一个简单介绍,关于这个函数底层是如何实现的,是一件较复杂的事,限于篇幅原因,我会在以后对此函数进行补充
简单做个小结
进程小结:
bash命令行解释器本质上也是一个进程,可以被销毁- 命令行启动的所有程序,最终都会变成进程,而该进程对应的父进程都是
bash - 父进程被销毁后,子进程会变成
孤儿进程 - 进程间具有独立性,包括父子进程
- 因为
写时拷贝机制,父进程不会影响到子进程