机器学习(算法篇)完整教程(附代码资料)主要内容讲述:机器学习算法课程定位、目标,K-近邻算法定位,目标,学习目标,1 什么是K-近邻算法,1 Scikit-learn工具介绍,2 K-近邻算法API。K-近邻算法,1.4 k值的选择学习目标,学习目标,1 kd树简介,2 构造方法,3 案例分析,4 总结。K-近邻算法,1.6 案例:鸢尾花种类预测--数据集介绍学习目标,1 案例:鸢尾花种类预测,2 scikit-learn中数据集介绍,1 什么是特征预处理,2 归一化,3 标准化。K-近邻算法,1.8 案例:鸢尾花种类预测—流程实现学习目标,1 再识K-近邻算法API,2 案例:鸢尾花种类预测,总结,1 什么是交叉验证(cross validation),2 什么是网格搜索(Grid Search)。线性回归,2.1 线性回归简介学习目标,1 线性回归应用场景,2 什么是线性回归,1 线性回归API,2 举例,1 常见函数的导数。线性回归,2.6 梯度下降法介绍学习目标,1 全梯度下降算法(FG),2 随机梯度下降算法(SG),3 小批量梯度下降算法(mini-bantch),4 随机平均梯度下降算法(SAG),5 算法比较。线性回归,2.8 欠拟合和过拟合学习目标,1 定义,2 原因以及解决办法,3 正则化,4 维灾难【拓展知识】。线性回归,2.9 正则化线性模型学习目标,1 Ridge Regression (岭回归,又名 Tikhonov regularization),2 Lasso Regression(Lasso 回归),3 Elastic Net (弹性网络),4 Early Stopping [了解],1 API。逻辑回归,3.4 分类评估方法学习目标,1.分类评估方法,2 ROC曲线与AUC指标,3 总结,1 曲线绘制,2 意义解释。决策树算法,4.4 特征工程-特征提取学习目标,1 特征提取,2 字典特征提取,3 文本特征提取。决策树算法,4.5 决策树算法api学习目标,1 泰坦尼克号数据,2 步骤分析,3 代码过程,3 决策树可视化,学习目标。集成学习,5.3 Boosting学习目标,1.boosting集成原理,2 GBDT(了解),3.XGBoost【了解】,4 什么是泰勒展开式【拓展】,学习目标。聚类算法,6.4 模型评估学习目标,1 误差平方和(SSE \The sum of squares due to error):,2 “肘”方法 (Elbow method) — K值确定,3 轮廓系数法(Silhouette Coefficient),4 CH系数(Calinski-Harabasz Index),5 总结。聚类算法,6.6 特征降维学习目标,1 降维,2 特征选择,3 主成分分析,1 需求,2 分析。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:
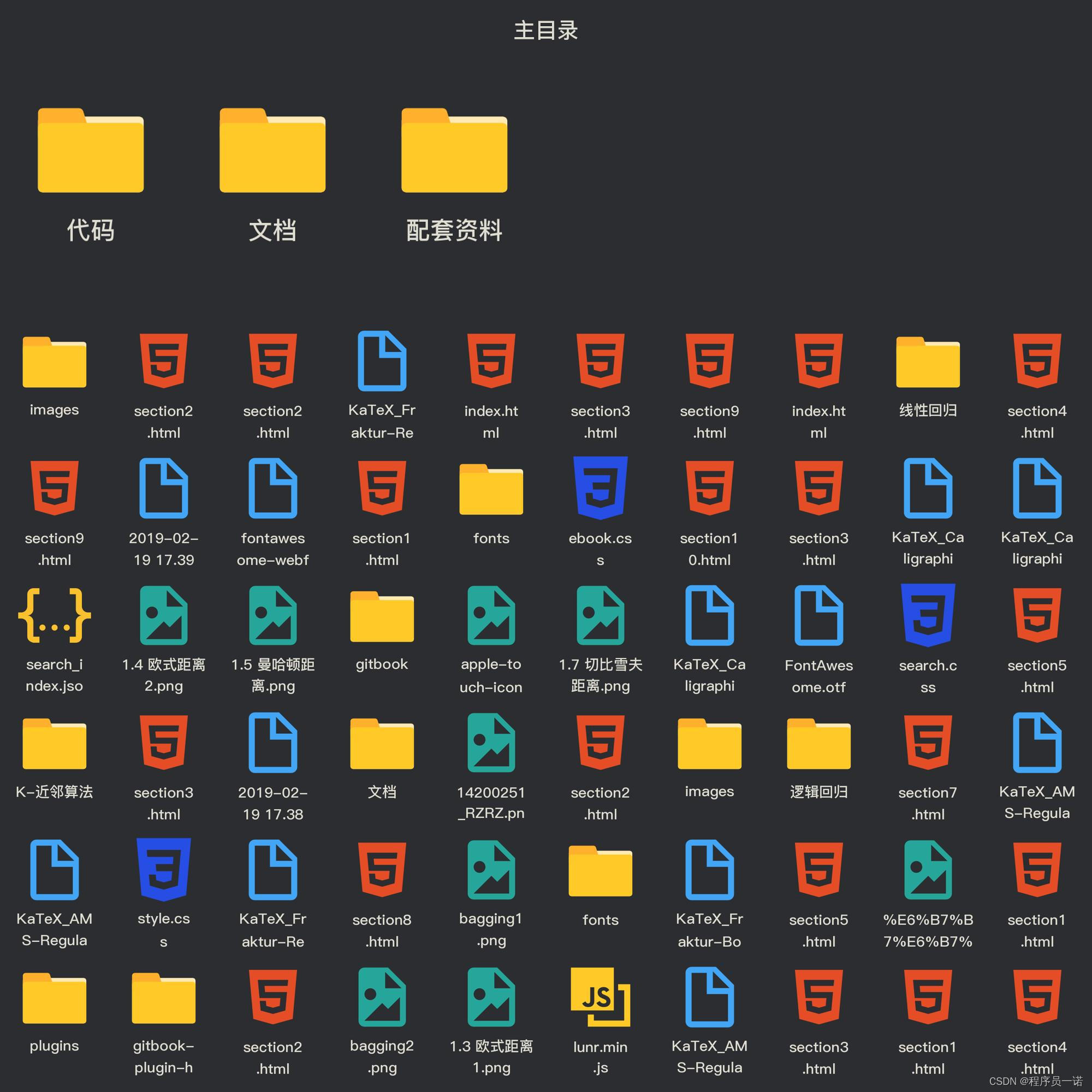
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.8 案例:鸢尾花种类预测—流程实现
1 再识K-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
-
n_neighbors:
- int,可选(默认= 5),k_neighbors查询默认使用的邻居数
-
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
-
快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,
- brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
- kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
-
2 案例:鸢尾花种类预测
2.1 数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

2.2 步骤分析
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
2.3 代码过程
- 导入模块
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
- 先从sklearn当中获取数据集,然后进行数据集的分割
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
-
进行数据标准化
-
特征值的标准化
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- 模型进行训练预测
# 4、机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=9)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 方法2:直接计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
1.9 练一练
同学之间讨论刚才完成的机器学习代码,并且确保在自己的电脑是哪个运行成功
总结
-
在本案例中,具体完成内容有:
-
使用可视化加载和探索数据,以确定特征是否能将不同类别分开。
- 通过标准化数字特征并随机抽样到训练集和测试集来准备数据。
-
通过统计学,精确度度量进行构建和评估机器学习模型。
-
k近邻算法总结
-
优点:
- 简单有效
- 重新训练的代价低
-
适合类域交叉样本
- KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
-
适合大样本自动分类
- 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
-
缺点:
-
惰性学习
- KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
-
类别评分不是规格化
- 不像一些通过概率评分的分类
-
输出可解释性不强
- 例如决策树的输出可解释性就较强
-
对不均衡的样本不擅长
- 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
-
计算量较大
- 目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
-
1.10 交叉验证,网格搜索
1 什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
1.1 分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

1.2 为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
2 什么是网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3 交叉验证,网格搜索(模型选择与调优)API:
-
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
-
对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
-
结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
4 鸢尾花案例增加K值调优
- 使用GridSearchCV构建估计器
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、特征工程:标准化
# 实例化一个转换器类
transfer = StandardScaler()
# 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 4.3 fit数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
- 然后进行评估查看最终选择的结果和交叉验证的结果
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
- 最终结果
比对预测结果和真实值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True True True True True True True
True True]
直接计算准确率:
0.947368421053
在交叉验证中验证的最好结果:
0.973214285714
最好的参数模型:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
每次交叉验证后的准确率结果:
{'mean_fit_time': array([ 0.00114751, 0.00027037, 0.00024462]), 'std_fit_time': array([ 1.13901511e-03, 1.25300249e-05, 1.11011951e-05]), 'mean_score_time': array([ 0.00085751, 0.00048693, 0.00045625]), 'std_score_time': array([ 3.52785082e-04, 2.87650037e-05, 5.29673344e-06]), 'param_n_neighbors': masked_array(data = [1 3 5],
mask = [False False False],
fill_value = ?)
, 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([ 0.97368421, 0.97368421, 0.97368421]), 'split1_test_score': array([ 0.97297297, 0.97297297, 0.97297297]), 'split2_test_score': array([ 0.94594595, 0.89189189, 0.97297297]), 'mean_test_score': array([ 0.96428571, 0.94642857, 0.97321429]), 'std_test_score': array([ 0.01288472, 0.03830641, 0.00033675]), 'rank_test_score': array([2, 3, 1], dtype=int32), 'split0_train_score': array([ 1. , 0.95945946, 0.97297297]), 'split1_train_score': array([ 1. , 0.96 , 0.97333333]), 'split2_train_score': array([ 1. , 0.96, 0.96]), 'mean_train_score': array([ 1. , 0.95981982, 0.96876877]), 'std_train_score': array([ 0. , 0.00025481, 0.0062022 ])}
1.11 案例2:预测facebook签到位置
1 数据集介绍

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
train.csv,test.csv
row_id:登记事件的ID
xy:坐标
准确性:定位准确性
时间:时间戳
place_id:业务的ID,这是您预测的目标
官网:[
2 步骤分析
-
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
-
1 缩小数据集范围 DataFrame.query()
-
2 选取有用的时间特征
-
3 将签到位置少于n个用户的删除
-
分割数据集
-
标准化处理
-
k-近邻预测
3 代码过程
- 1.获取数据集
# 1、获取数据集
facebook = pd.read_csv("./data/FBlocation/train.csv")
- 2.基本数据处理
# 2.基本数据处理
# 2.1 缩小数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 2.3 去掉签到较少的地方
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"]>3]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = facebook_data["place_id"]
# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
- 特征工程--特征预处理(标准化)
# 3.特征工程--特征预处理(标准化)
# 3.1 实例化一个转换器
transfer = StandardScaler()
# 3.2 调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
- 机器学习--knn+cv
# 4.机器学习--knn+cv
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
# 4.3 模型训练
estimator.fit(x_train, y_train)
- 模型评估
# 5.模型评估
# 5.1 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)

![[Spring Cloud] gateway全局异常捕捉统一返回值](https://img-blog.csdnimg.cn/img_convert/c8d13eba2f684c0896025b7afba170d7.png)



![蓝桥杯(5):python动态规划DF[2:背包问题]](https://img-blog.csdnimg.cn/direct/0caab64c3f4d4ba69bd2c208e455ab64.png)