文章目录
- 一、解压压缩包
- 二、修改配置文件conf/spark-env.sh
- 三、测试提交Spark任务
- 四、Spark on Hive配置
- 4.1 创建hive-site.xml(spark/conf目录)
- 4.2 查看hive的hive-site.xml配置与3.1配置的是否一致
- 4.3 测试SparkSQL
- 4.3.1 启动SparkSQL客户端(Yarn方式)
- 4.3.2 启动Hive客户端
- 五、通过Spark Web-UI分析SQL执行过程(TODO)
- 六、集群化(TODO)
一、解压压缩包
[hadoop@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
二、修改配置文件conf/spark-env.sh
cd /opt/module/spark-3.0.0-bin-hadoop3.2/conf
[hadoop@hadoop102 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@hadoop102 conf]$ vim spark-env.sh
内容:
export JAVA_HOME=/opt/module/jdk1.8.0_291
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
三、测试提交Spark任务
[hadoop@hadoop102 ~]$ cd /opt/module/spark-3.0.0-bin-hadoop3.2/
[hadoop@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \
> ./examples/jars/spark-examples_2.12-3.0.0.jar \
> 10
到YARN WEB页面查看任务提交情况
四、Spark on Hive配置
4.1 创建hive-site.xml(spark/conf目录)
[hadoop@hadoop102 conf]$ cd /opt/module/spark-3.0.0-bin-hadoop3.2/conf/
[hadoop@hadoop102 conf]$ vim hive-site.xml
内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--告知Spark创建表存到哪里-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/warehouse</value>
</property>
<!-- 不使用spark内置hive存储元数据 -->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--告知Spark Hive的MetaStore在哪-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
</configuration>
4.2 查看hive的hive-site.xml配置与3.1配置的是否一致
cd /opt/module/apache-hive-3.1.2-bin/conf
vim hive-site.xml
4.3 测试SparkSQL
4.3.1 启动SparkSQL客户端(Yarn方式)
[hadoop@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-sql --master yarn
spark-sql> show databases;
spark-sql> select count(1)
> from dw_ods.ods_activity_info_full
> where dt='2023-12-07';
4.3.2 启动Hive客户端
[hadoop@hadoop102 apache-hive-3.1.2-bin]$ bin/hive
hive> show databases;
hive> select count(1)
> from dw_ods.ods_activity_info_full
> where dt='2023-12-07';
五、通过Spark Web-UI分析SQL执行过程(TODO)
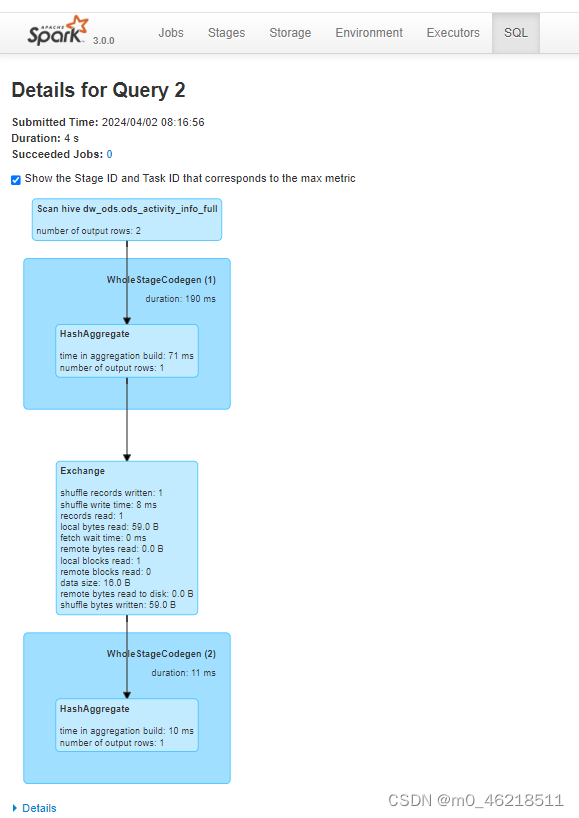




六、集群化(TODO)
优势在哪里??








![[数据结构初阶]堆的应用](https://img-blog.csdnimg.cn/direct/a764d84a83da498da9d10f599dc847eb.png)