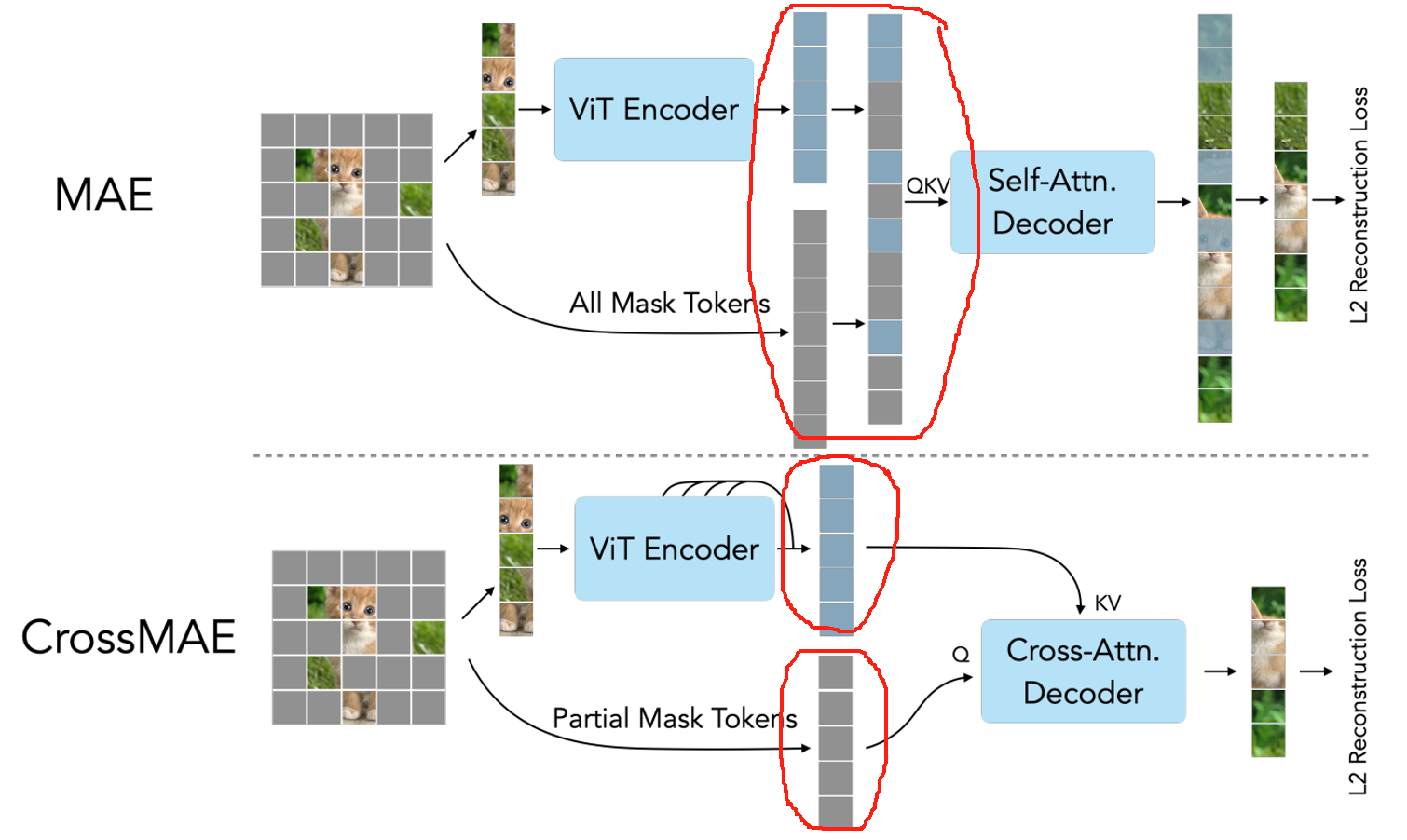
作者团队来自加州大学伯克利分校(UC Berkeley)和加州大学旧金山分校(UCSF)。论文主要探讨了在MAE的解码中,图像patch之间的依赖性,并提出了一种新的预训练框架 CrossMAE。
论文的主要贡献包括:
- 提出了CrossMAE框架,其解码器仅利用掩码和可见标记之间的交叉注意力,而不使用掩码标记之间的自注意力。这种设计在不降低下游性能的情况下,提高了效率。
- CrossMAE的设计允许仅解码一小部分掩码标记,这提高了预训练的效率。此外,每个解码器块现在可以利用不同的编码器特征,从而改善了表示学习。
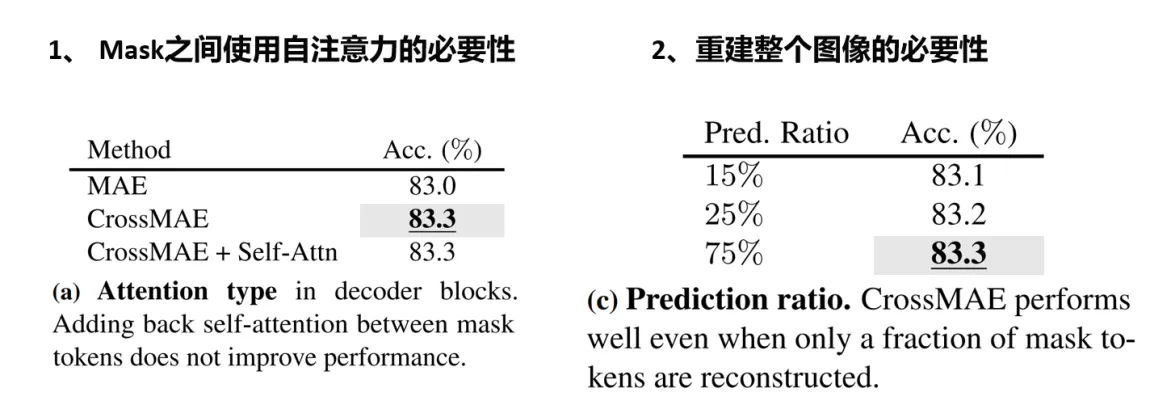
贡献1:CrossMAE与MAE的对比如下图所示。MAE在decoder重建时,将 unmask 的 token恢复到图像中,整体进行self-attention计算,作者认为 masked token 彼此间也进行了attention计算,是没有必要的。所以,作者进行了改进,在解码器中将masked token 做为Q,unmasked token做为KV,进行cross attention计算。
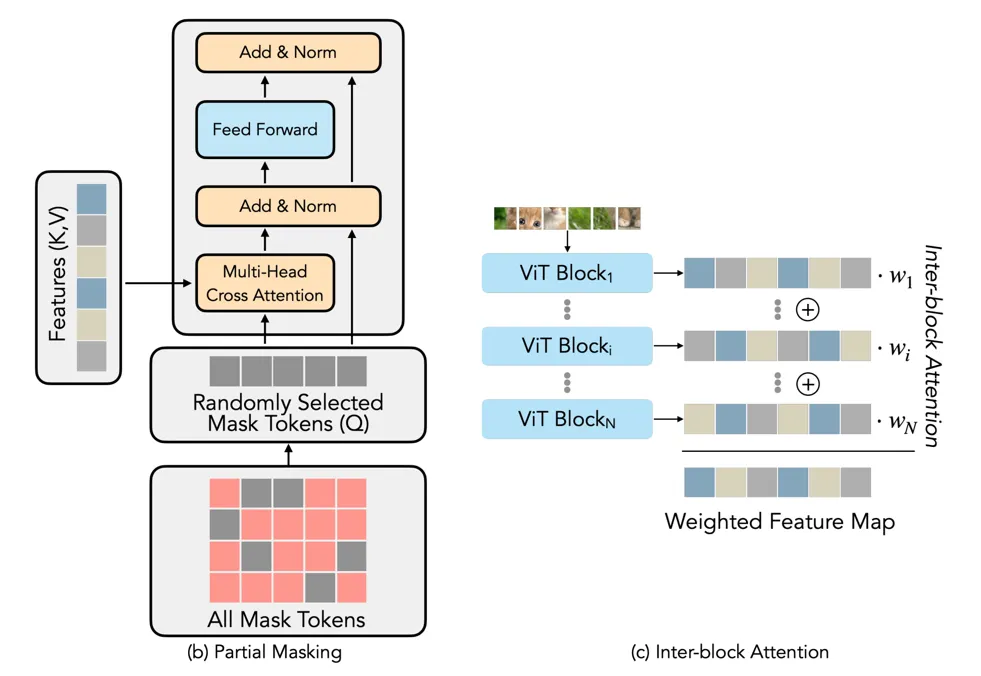
贡献2: partial masking。作者只是随机挑选了一些 masked tokens 进行修复,这样会降低计算量,后面有实验分析。此外,作者还有一处改进,在编码器的各个 transformer block 之间动态学习了一个权重,对特征加权。这就有些像 layer attention。不过,这个改进并没有刻意的在引言里强调。
CrossMAE 比 MAE 提高了0.3%,而且只重建25%的token效果就已经非常好了,计算效率显著提升。





![[中级]软考_软件设计_计算机组成与体系结构_07_存储系统](https://img-blog.csdnimg.cn/direct/893bfad31fec4e86898abf9ba6ce376d.png)

![[C#]OpenCvSharp使用帧差法或者三帧差法检测移动物体](https://img-blog.csdnimg.cn/direct/fcdbca9fb19848e4afe4d34a102b6544.png)