2024.4.3 Wednesday
目录
- 5.MySQL函数
- 5.1.常用函数
- 5.1.1.数据函数
- 5.1.2.字符串函数
- 5.1.2.1.CHAR_LENGTH(str)计算字符串str长度
- 5.1.2.2.CONCAT(str1,str2,...)拼接字符串str1 str2 ...
- 5.1.2.3.INSERT(str,pos,len,newstr)把原文str第pos位开始长度为len的字符串替换成newstr
- 5.1.2.4.转换大小写
- 5.1.2.5.INSTR(str,substr)找到str中substr的位置
- 5.1.2.6.REPLACE(str,from_str,to_str)
- 5.1.2.7.SUBSTR(str FROM pos FOR len)从pos截取长度为len的子字符串
- 5.1.2.8.反转
- 5.1.2.9.查询姓‘张’的同学,替换成姓‘邹’
- 5.1.3.时间和日期函数(记)
- 5.1.3.1.获取当前日期
- 5.1.3.2.获取当前时间
- 5.1.3.3.获取本地时间
- 5.1.3.4.获取系统时间
- 5.1.3.5.获取年月日,时分秒
- 5.1.4.系统信息函数
- 5.1.4.1.用户
- 5.1.4.2.版本
- 5.2.聚合函数(常用)
- 5.2.1.简介
- 5.2.2.Count查询记录中的行数
- 5.2.3.注意点
- 5.2.4.SUM AVG MAX MIN
- 5.2.5.题目(转接到4.7.分组和过滤)
5.MySQL函数
5.1.常用函数
5.1.1.数据函数
-- 常用函数 --
-- 数据函数
SELECT ABS(-8) -- 绝对值

SELECT CEILING(9.1) -- 向上取整
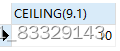
SELECT FLOOR(9.9) -- 向下取整
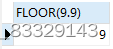
SELECT RAND() -- 返回一个[0,1)之间的随机数
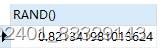
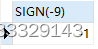
SELECT SIGN(-9) -- 判断一个数的符号:负数返回-1,0返回0,正数返回1
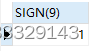
SELECT SIGN(9)
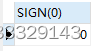
SELECT SIGN(0)
5.1.2.字符串函数
5.1.2.1.CHAR_LENGTH(str)计算字符串str长度
-- 字符串函数
SELECT CHAR_LENGTH('鲁智深倒拔垂杨柳') -- CHAR_LENGTH(str)计算字符串str长度

5.1.2.2.CONCAT(str1,str2,…)拼接字符串str1 str2 …
SELECT CONCAT('鲁智深','倒拔','垂杨柳') -- CONCAT(str1,str2,...)拼接字符串str1 str2 ...

5.1.2.3.INSERT(str,pos,len,newstr)把原文str第pos位开始长度为len的字符串替换成newstr
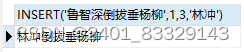
SELECT INSERT('鲁智深倒拔垂杨柳',1,3,'林冲') -- INSERT(str,pos,len,newstr)把原文str第pos位开始长度为len的字符串替换成newstr
5.1.2.4.转换大小写
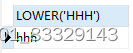
SELECT LOWER('HHH') -- 全部转为小写
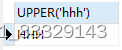
SELECT UPPER('hhh') -- 全部转为大写
5.1.2.5.INSTR(str,substr)找到str中substr的位置
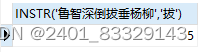
SELECT INSTR('鲁智深倒拔垂杨柳','拔') -- INSTR(str,substr)找到str中substr的位置
5.1.2.6.REPLACE(str,from_str,to_str)
SELECT REPLACE('鲁智深倒拔垂杨柳','倒拔','reverse a tendency') -- REPLACE(str,from_str,to_str)

5.1.2.7.SUBSTR(str FROM pos FOR len)从pos截取长度为len的子字符串
SELECT SUBSTR('鲁智深倒拔垂杨柳' FROM 4 FOR 5) -- SUBSTR(str FROM pos FOR len)从pos截取长度为len的子字符串

5.1.2.8.反转
SELECT REVERSE('鲁智深倒拔垂杨柳') -- 反转

5.1.2.9.查询姓‘张’的同学,替换成姓‘邹’
use `school`
-- 查询姓‘张’的同学
SELECT * FROM student
WHERE studentname LIKE '张%'
-- 替换成姓‘邹’(不会改变数据库里的原始数据),所以不用替换回来
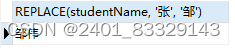
SELECT REPLACE(studentName, '张', '邹') FROM student
WHERE studentname LIKE '张%'

5.1.3.时间和日期函数(记)
5.1.3.1.获取当前日期
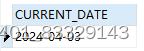
SELECT CURRENT_DATE -- 获取当前日期,好像不需要括号
SELECT CURDATE()
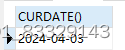
5.1.3.2.获取当前时间
SELECT NOW() -- 获取当前时间
*水印太烦人了,先关掉吧
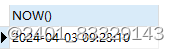
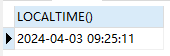
5.1.3.3.获取本地时间
SELECT LOCALTIME() -- 获取本地时间
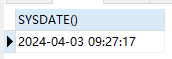
5.1.3.4.获取系统时间
SELECT SYSDATE() -- 获取系统时间
5.1.3.5.获取年月日,时分秒
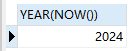
SELECT YEAR(NOW())
SELECT MONTH(NOW())

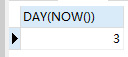
SELECT DAY(NOW())
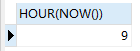
SELECT HOUR(NOW())
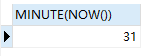
SELECT MINUTE(NOW())
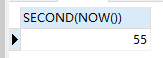
SELECT SECOND(NOW())
5.1.4.系统信息函数
5.1.4.1.用户
-- 系统信息函数
SELECT SYSTEM_USER() -- 用户
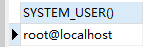
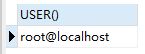
SELECT USER()
5.1.4.2.版本
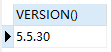
SELECT VERSION()
5.2.聚合函数(常用)
5.2.1.简介
| 函数名称 | 描述 |
|---|---|
| COUNT( ) | 返回满足Select条件的记录总和数,如 select count(*) 【不建议使用 *,效率低】 |
| SUM( ) | 返回数字字段或表达式列作统计,返回一列的总和 |
| AVG( ) | 通常为数值字段或表达列作统计,返回一列的平均值 |
| MAX( ) | 可以为数值字段,字符字段或表达式列作统计,返回最大的值 |
| MIN( ) | 可以为数值字段,字符字段或表达式列作统计,返回最小的值 |
5.2.2.Count查询记录中的行数
-- 聚合函数 --
-- 以下几个count都能够统计相应的表中的数据(查询记录中的行数)
SELECT COUNT(studentname) FROM student; -- Count(指定列(字段)),会忽略所有的null值
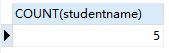
SELECT COUNT(borndate) FROM student; -- 有一行没有出生日期,所以统计出来的行数比所有的少1
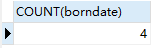
SELECT COUNT(*) FROM student; -- Count(*),不会忽略null值,本质:计算行数
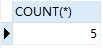
SELECT COUNT(1) FROM result; -- Count(1),不会忽略null值,本质:计算行数
5.2.3.注意点
-- 从含义上讲,count(1) 与 count(*) 都表示对全部数据行的查询。
-- count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
-- count(*) 包括了所有的列,相当于行数,在统计结果的时候,包含字段为null 的记录;
-- count(1) 用1代表代码行,在统计结果的时候,包含字段为null 的记录 。
/*
很多人认为count(1)执行的效率会比count(*)高,原因是count(*)会存在全表扫描,而count(1)可以针对一个字段进行查询。其实不然,count(1)和count(*)都会对全表进行扫描,统计所有记录的条数,包括那些为null的记录,因此,它们的效率可以说是相差无几。而count(字段)则与前两者不同,它会统计该字段不为null的记录条数。
下面它们之间的一些对比:
1)在表没有主键时,count(1)比count(*)快
2)有主键时,主键作为计算条件,count(主键)效率最高;
3)若表格只有一个字段,则count(*)效率较高。
*/
5.2.4.SUM AVG MAX MIN
SELECT SUM(`StudentResult`) AS 总和 FROM result

SELECT AVG(`StudentResult`) AS 平均分 FROM result
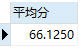
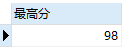
SELECT MAX(`StudentResult`) AS 最高分 FROM result
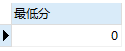
SELECT MIN(`StudentResult`) AS 最低分 FROM result
5.2.5.题目(转接到4.7.分组和过滤)
-- 查询不同课程的平均分,最高分,最低分
-- 前提:根据不同的课程进行分组
SELECT subjectname,AVG(studentresult) AS 平均分,MAX(StudentResult) AS 最高分,MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOIN `subject` AS s
ON r.subjectno = s.subjectno
GROUP BY r.subjectno
HAVING 平均分>80;
/*
where写在group by前面.
要是放在分组后面的筛选
要使用HAVING..
因为having是从前面筛选的字段再筛选,而where是从数据表中的>字段直接进行的筛选的
*/
具体实现:
SELECT SubjectName, AVG(StudentResult), MAX(StudentResult), MIN(StudentResult)
FROM result r
INNER JOIN `subject` sub
ON r.`SubjectNo` = sub.`SubjectNo`
-- WHERE AVG(StudentResult) > 70 这样写不符合语法要求(WHERE不能使用聚合函数)
GROUP BY r.SubjectNo -- 通过什么字段来分组
HAVING AVG(StudentResult) > 70 -- 筛选分组后的数据用HAVING