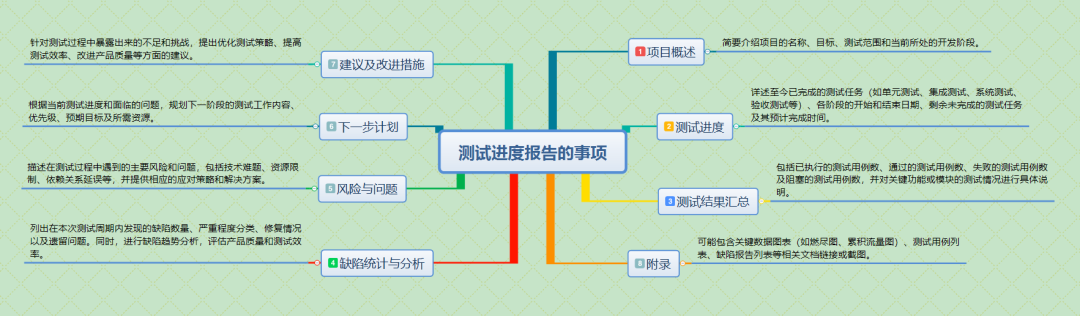
XML处理
- DOM
DOM解析要求解析器将整个XML文件全部加载到内存中,生成一个Document对象。
优点:元素和元素之间保留结构,关系,可以针对元素进行增删改查操作。
缺点:如果XML文件过大,可能会导致内存溢出。 - SAX
SAX解析是一种更加高效的解析方式。它是逐行扫描,边扫描边解析,并且以时间驱动的方式进行具体的解析,每解析一行都会触发一个事件。
优点:不会出现内存溢出的问题,可以处理大文件。
缺点:只能读,不能写。 - 常见的解析XML类库
解析器就是根据不同的解析方式提供具体的实现,为了方便开发人员来解析XML,有一些方便操作的类库。具体如下所示:
1.dom4j:比较简单的XML解析类库;
2.Jsoup:功能强大的DOM方式解析的类库,尤其对HTML的解析更加方便,所以可以使用Jsoup来爬取网页的数据。
JDK内置DOM
XML文件
books.xml
<?xml version="1.0" encoding="UTF-8"?>
<books>
<!-- book至少出现一次 -->
<book>
<!-- id -->
<id>1</id>
<!-- 书名 -->
<name>《JAVA从入门到放弃》</name>
<!-- 作者
属性type:可选(man|woman)默认值 “man”
属性age:必填属性
-->
<author type="man" age="23">张三</author>
</book>
<book>
<id>2</id>
<name>《这是一本书》</name>
<author type="woman" age="32">李四</author>
</book>
</books>
JDK内置DOM读XML
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
/**
* JDK内置DOM读XML
*
* @author Anna.
* @date 2024/3/31 17:42
*/
public class JavaDomReadDemo {
public static void main(String[] args) throws Exception {
new JavaDomReadDemo().read();
}
public void read() throws ParserConfigurationException, IOException, SAXException {
// 获取资源路径
String path = this.getClass().getResource("books.xml").getPath();
// 获取文件判断文件是否存在
File file = new File(path);
if (!file.exists() || !file.isFile()) {
throw new RuntimeException("获取资源失败");
}
// 从DocumentBuilderFactory获得DocumentBuilder。 DocumentBuilder包含用于从 XML 文档中获取 DOM 文档实例的 API。
DocumentBuilder documentBuilder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
// parse()方法将 XML 文件解析为Document
Document doc = documentBuilder.parse(file);
System.out.printf("根节点: %s", doc.getDocumentElement().getNodeName());
// 循环打印
NodeList nList = doc.getElementsByTagName("book");
for (int i = 0; i < nList.getLength(); i++) {
Node nNode = nList.item(i);
System.out.println("");
System.out.printf("元素: %s", nNode.getNodeName());
if (nNode.getNodeType() == Node.ELEMENT_NODE) {
Element elem = (Element) nNode;
String id = elem.getElementsByTagName("id").item(0).getTextContent();
String name = elem.getElementsByTagName("name").item(0).getTextContent();
Element authorNode = (Element) elem.getElementsByTagName("author").item(0);
String author = elem.getElementsByTagName("author").item(0).getTextContent();
String type = authorNode.getAttribute("type");
String age = authorNode.getAttribute("age");
System.out.println("");
System.out.printf("id: %s - name:%s - author:%s[type=%s,age=%s]", id, name, author, type, age);
}
}
}
}
执行结果

使用NodeIterator读取文本
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.NodeIterator;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
/**
* JDK内置DOM读XML
* 使用NodeIterator读取文本
*
* @author Anna.
* @date 2024/3/31 17:42
*/
public class JavaDomReadDemo2 {
public static void main(String[] args) throws Exception {
new JavaDomReadDemo2().read();
}
public void read() throws ParserConfigurationException, IOException, SAXException {
// 获取资源路径
String path = this.getClass().getResource("books.xml").getPath();
// 获取文件判断文件是否存在
File file = new File(path);
if (!file.exists() || !file.isFile()) {
throw new RuntimeException("获取资源失败");
}
// 从DocumentBuilderFactory获得DocumentBuilder。 DocumentBuilder包含用于从 XML 文档中获取 DOM 文档实例的 API。
DocumentBuilder documentBuilder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
// parse()方法将 XML 文件解析为Document
Document doc = documentBuilder.parse(file);
DocumentTraversal trav = (DocumentTraversal) doc;
NodeIterator it = trav.createNodeIterator(doc.getDocumentElement(), NodeFilter.SHOW_ELEMENT, null, true);
for (Node node = it.nextNode(); node != null;
node = it.nextNode()) {
// 判断是否有属性
if (node.hasAttributes()) {
String attrStr = getAttrStr(node.getAttributes());
System.out.printf("元素名称:%s-元素值:%s-属性:%s %n", node.getNodeName(), node.getTextContent(), "".equalsIgnoreCase(attrStr) ? "null" : attrStr, node.getNodeType());
} else {
System.out.printf("元素名称:%s-元素值:%s%n", node.getNodeName(), node.getTextContent());
}
}
}
private String getAttrStr(NamedNodeMap attributes) {
StringBuffer sb = new StringBuffer();
if (attributes != null && attributes.getLength() > 0) {
sb.append("[");
for (int i = 0; i < attributes.getLength(); i++) {
Node item = attributes.item(i);
sb.append(item.getNodeName()).append("=").append(item.getNodeValue()).append(" ");
}
sb.append("]");
}
return sb.toString();
}
}
执行结果

使用NodeIterator读取文本自定义NodeFilter
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.traversal.DocumentTraversal;
import org.w3c.dom.traversal.NodeFilter;
import org.w3c.dom.traversal.NodeIterator;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
/**
* JDK内置DOM读XML
* 使用NodeIterator读取文本自定义NodeFilter
* @author Anna.
* @date 2024/3/31 17:42
*/
public class JavaDomReadDemo3 {
public static void main(String[] args) throws Exception {
new JavaDomReadDemo3().read();
}
public void read() throws ParserConfigurationException, IOException, SAXException {
// 获取资源路径
String path = this.getClass().getResource("books.xml").getPath();
// 获取文件判断文件是否存在
File file = new File(path);
if (!file.exists() || !file.isFile()) {
throw new RuntimeException("获取资源失败");
}
// 从DocumentBuilderFactory获得DocumentBuilder。 DocumentBuilder包含用于从 XML 文档中获取 DOM 文档实例的 API。
DocumentBuilder documentBuilder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
// parse()方法将 XML 文件解析为Document
Document doc = documentBuilder.parse(file);
DocumentTraversal trav = (DocumentTraversal) doc;
NodeIterator it = trav.createNodeIterator(doc.getDocumentElement(), NodeFilter.SHOW_ELEMENT, new MyFilter(), true);
for (Node node = it.nextNode(); node != null;
node = it.nextNode()) {
// 判断是否有属性
if(node.hasAttributes()){
String attrStr = getAttrStr(node.getAttributes());
System.out.printf("元素名称:%s-元素值:%s-属性:%s %n", node.getNodeName(),node.getTextContent(),"".equalsIgnoreCase(attrStr) ? "null" : attrStr, node.getNodeType());
}
else {
System.out.printf("元素名称:%s-元素值:%s%n", node.getNodeName(),node.getTextContent());
}
}
}
private String getAttrStr(NamedNodeMap attributes){
StringBuffer sb = new StringBuffer();
if(attributes != null && attributes.getLength() > 0){
sb.append("[");
for(int i = 0; i < attributes.getLength(); i++){
Node item = attributes.item(i);
sb.append(item.getNodeName()).append("=").append(item.getNodeValue()).append(" ");
}
sb.append("]");
}
return sb.toString();
}
/**
* 自定义过滤器
* 实现NodeFilter接口
* 通过返回NodeFilter.FILTER_ACCEPT和NodeFilter.FILTER_REJECT来控制要使用的节点
* @author Anna.
* @date 2024/3/31 18:50
*/
static class MyFilter implements NodeFilter {
@Override
public short acceptNode(Node thisNode) {
if (thisNode.getNodeType() == Node.ELEMENT_NODE) {
Element e = (Element) thisNode;
String nodeName = e.getNodeName();
if ("author".equals(nodeName)) {
return NodeFilter.FILTER_ACCEPT;
}
}
return NodeFilter.FILTER_REJECT;
}
}
}
执行结果

JDK内置DOM写XML
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
/**
* JDK内置DOM写XML
*
* @author Anna.
* @date 2024/3/31 17:42
*/
public class JavaDomWriteDemo {
public static void main(String[] args) throws Exception {
new JavaDomWriteDemo().write();
}
public void write() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.newDocument();
// 创建根节点
Element root = doc.createElementNS("", "books");
doc.appendChild(root);
// 设置子元素
Map<String, String> book1 = new HashMap<String, String>();
book1.put("type", "man");
book1.put("age", "34");
root.appendChild(createBook(doc, "1", "《JAVA从入门到放弃》", "张三", book1));
Map<String, String> book2 = new HashMap<String, String>();
book2.put("type", "man");
book2.put("age", "34");
root.appendChild(createBook(doc, "2", "《这是一本书》", "李四", book2));
// Java DOM 使用Transformer生成 XML 文件。 之所以称为转换器,是因为它也可以使用 XSLT 语言转换文档。
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transf = transformerFactory.newTransformer();
// 设置文档的编码和缩进
transf.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
transf.setOutputProperty(OutputKeys.INDENT, "yes");
transf.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "2");
// DOMSource保存 DOM 树
DOMSource source = new DOMSource(doc);
// 获取资源路径
String path = System.getProperty("user.dir") + File.separator + "01-xml-04-xml-handle/java-dom-demo/src/main/resources";
File myFile = new File(path + File.separator + "books2.xml");
StreamResult console = new StreamResult(System.out);
StreamResult file = new StreamResult(myFile);
// 写入控制台和文件
transf.transform(source, console);
transf.transform(source, file);
}
/**
* 创建Book
* e
*
* @param doc
* @param id
* @param name
* @param author
* @return org.w3c.dom.Node
* @author Anna.
* @date 2024/3/31 19:03
*/
private static Node createBook(Document doc, String id, String name, String author, Map<String, String> attrsMap) {
Element book = doc.createElement("book");
book.setAttribute("id", id);
book.appendChild(createUserElement(doc, "id", id, null));
book.appendChild(createUserElement(doc, "name", name, null));
book.appendChild(createUserElement(doc, "author", author, attrsMap));
return book;
}
/**
* 创建子节点
*
* @param doc
* @param name
* @param value
* @param attrsMap
* @return org.w3c.dom.Node
* @author Anna.
* @date 2024/3/31 19:02
*/
private static Node createUserElement(Document doc, String name, String value, Map<String, String> attrsMap) {
Element node = doc.createElement(name);
node.appendChild(doc.createTextNode(value));
if (attrsMap != null && attrsMap.size() > 0) {
for (Map.Entry entry : attrsMap.entrySet()) {
node.setAttribute(entry.getKey().toString(), entry.getValue().toString());
}
}
return node;
}
}
执行结果

DOM4J读写XML
引入MAVEN坐标
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.3</version>
</dependency>
SAX读XML
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.Iterator;
/**
* SAX读XML文件
*
* @author Anna.
* @date 2024/3/31 19:40
*/
public class SaxReadDemo {
public static void main(String[] args) {
new SaxReadDemo().read();
}
public void read() {
// 获取资源路径
String path = this.getClass().getResource("books.xml").getPath();
// 获取文件判断文件是否存在
File file = new File(path);
if (!file.exists() || !file.isFile()) {
throw new RuntimeException("获取资源失败");
}
// 1 创建SAXReader对象,用于读取XML文件
SAXReader saxReader = new SAXReader();
// 读取XML文件,得到document对象
try {
Document document = saxReader.read(new File(path));
// 获取根元素
Element rootElement = document.getRootElement();
System.out.println("根元素名称:" + rootElement.getName());
// 获取根元素下所有子元素
Iterator<?> iterator = rootElement.elementIterator();
while (iterator.hasNext()) {
// 取出元素
Element element = (Element) iterator.next();
System.out.println("子元素名称:" + element.getName());
// 获取子元素
Element id = element.element("id");
Element name = element.element("name");
Element author = element.element("author");
System.out.printf("子元素的子元素值-id:%s -name: %s --author:%s[type=%s,age=%s]%n",
id.getStringValue(), name.getText(),
author.getText(),
// 获取author属性type
author.attribute("type").getValue(),
// 获取author属性age
author.attribute("age").getValue());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
执行结果

DOM4J写XML
Dom4j的常用API说明
| 方法 | 操作 |
|---|---|
| Element getRootElement(); | 获取XML文件的根节点 |
| String getName(); | 返回标签的名称 |
| List < Element > elements(); | 获取标签所有的子标签 |
| String arrtributeVallue(String name) ; | 获取指定属性名称的属性值 |
| String getText(); | 获取标签的文本 |
| String elementText(String name); | 获取指定名称的子标签的文本,返回子标签文本的值 |
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
/**
* Dom4j写XML文件
*
* @author Anna.
* @date 2024/3/31 19:40
*/
public class Dom4jWriteDemo {
public static void main(String[] args) {
String path = System.getProperty("user.dir") + File.separator + "01-xml-04-xml-handle/dom4j-demo/src/main/resources";
new Dom4jWriteDemo().write(path + File.separator + "books2.xml");
}
public void write(String path) {
// 通过documentHelper生成一个Documen对象
Document document = DocumentHelper.createDocument();
// 添加并得到根元素
Element books = document.addElement("books");
// 为根元素添加子元素
Element book = books.addElement("book");
// 为book添加子元素
Element id = book.addElement("id");
Element name = book.addElement("name");
Element author = book.addElement("author");
// 为子元素添加文本
id.addText("1");
name.addText("《Java自学基础》");
author.addText("张三");
author.addAttribute("type", "man");
author.addAttribute("age", "12");
// 将DOC输出到XML文件 简单输出
// Writer writer = null;
// try {
// writer = new FileWriter(new File(path));
// document.write(writer);
// // 关闭资源
// writer.close();
// } catch (IOException e) {
// e.printStackTrace();
// } finally {
// if (writer != null) {
// try {
// writer.close();
// } catch (IOException e) {
// e.printStackTrace();
// }
// }
// }
// 美化格式输出
OutputFormat format = OutputFormat.createPrettyPrint();
XMLWriter xmlWriter = null;
try {
xmlWriter = new XMLWriter(new FileWriter(new File(path)), format);
xmlWriter.write(document);
// 关闭资源
xmlWriter.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (xmlWriter != null) {
try {
xmlWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
执行结果