1、简单介绍
主要是关注目标检测方面的工作,现在纯CV已经前景黯淡,即使前段时间的YOLOv9发布也是关注一般。
现在大模型已成热点,而大模型要求的数据量和算力和算法复杂度,显然让很多人却步。但是具有大模型特点的多模态算法也算是研究的趋势,所以目前主要是关注多模态方面的目标检测工作。
其中目标检测领域,目前和多模态相关的主要是 开集、开放词汇、描述性目标检测以及情景理解等。相关的研究工作已经越来越多,这里权当学习记录。
RegionCLIP作为OVD检测算法,也是具有一定的代表性。
RegionCLIP的官方网址:https://github.com/microsoft/RegionCLIP
RegionCLIP的论文网址:https://arxiv.org/pdf/2112.09106.pdf

文章概述(摘自GitHub):
我们提出了 RegionCLIP,它显着扩展了 CLIP 以学习区域级的视觉表示。RegionCLIP支持图像区域和文本概念之间的细粒度对齐,从而支持基于区域的推理任务,包括零样本对象检测和开放词汇对象检测。
①预训练:我们利用 CLIP 模型将图像区域与模板标题进行匹配,然后预训练模型以对齐这些区域-文本对。
②零样本推理:预训练后,学习区域表示支持用于对象检测的零样本推理。
③迁移学习:学习的 RegionCLIP 模型可以通过额外的对象检测注释进一步微调,从而允许我们的模型用于完全监督或开放词汇的对象检测。
④结果:我们的方法展示了零样本目标检测和开放词汇目标检测的最新结果。
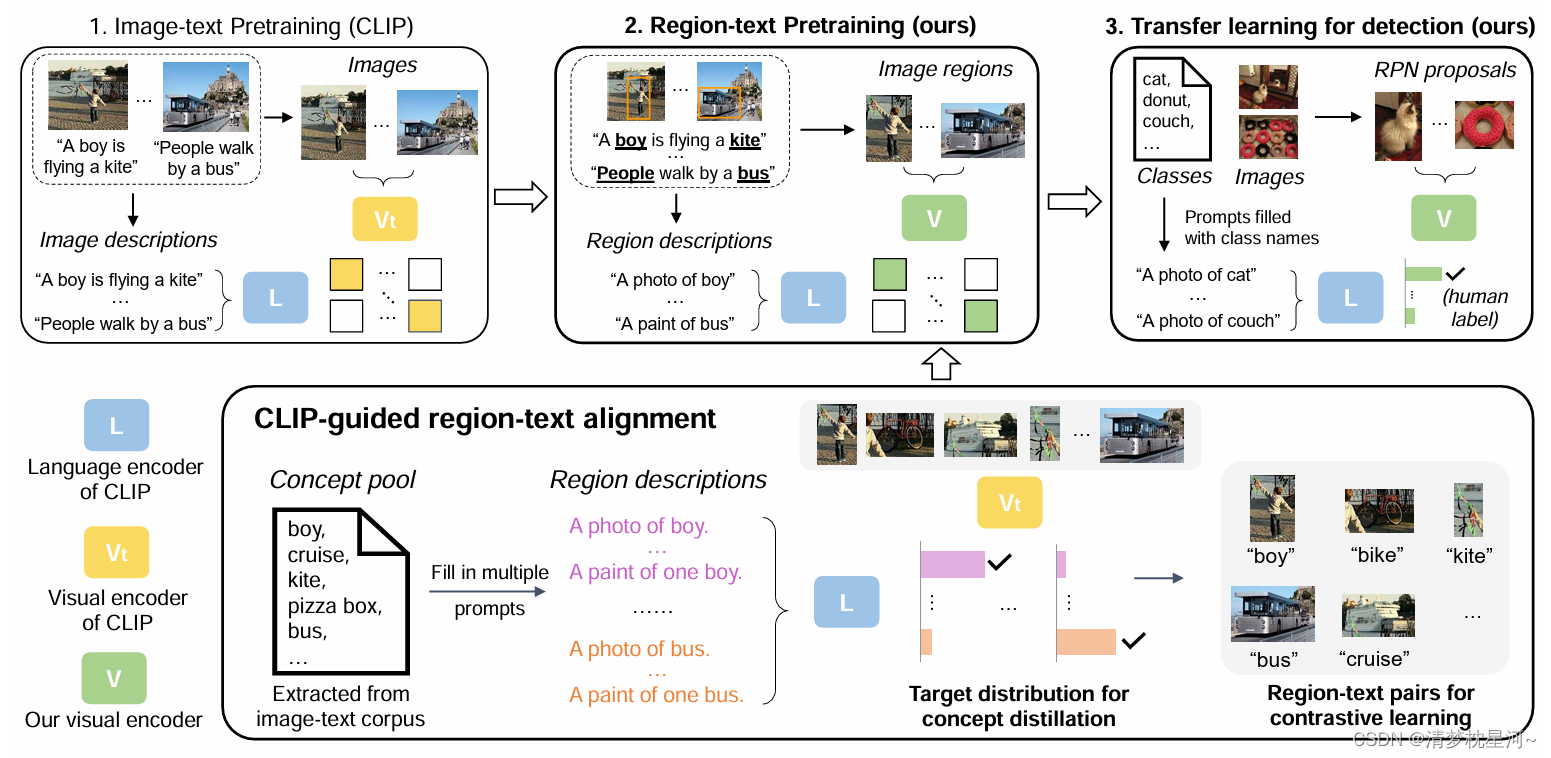
概括一下:核心思想就是把之前 图像特征和文本特征匹配的方式 聚焦到了 图像的局部区域特征 和文本特征的匹配
2、网络结构
大致看了代码,RegionCLIP是基于detectron2写的,包括预训练模型的训练和Fast RCNN结构的网络
2.1 预训练配置:
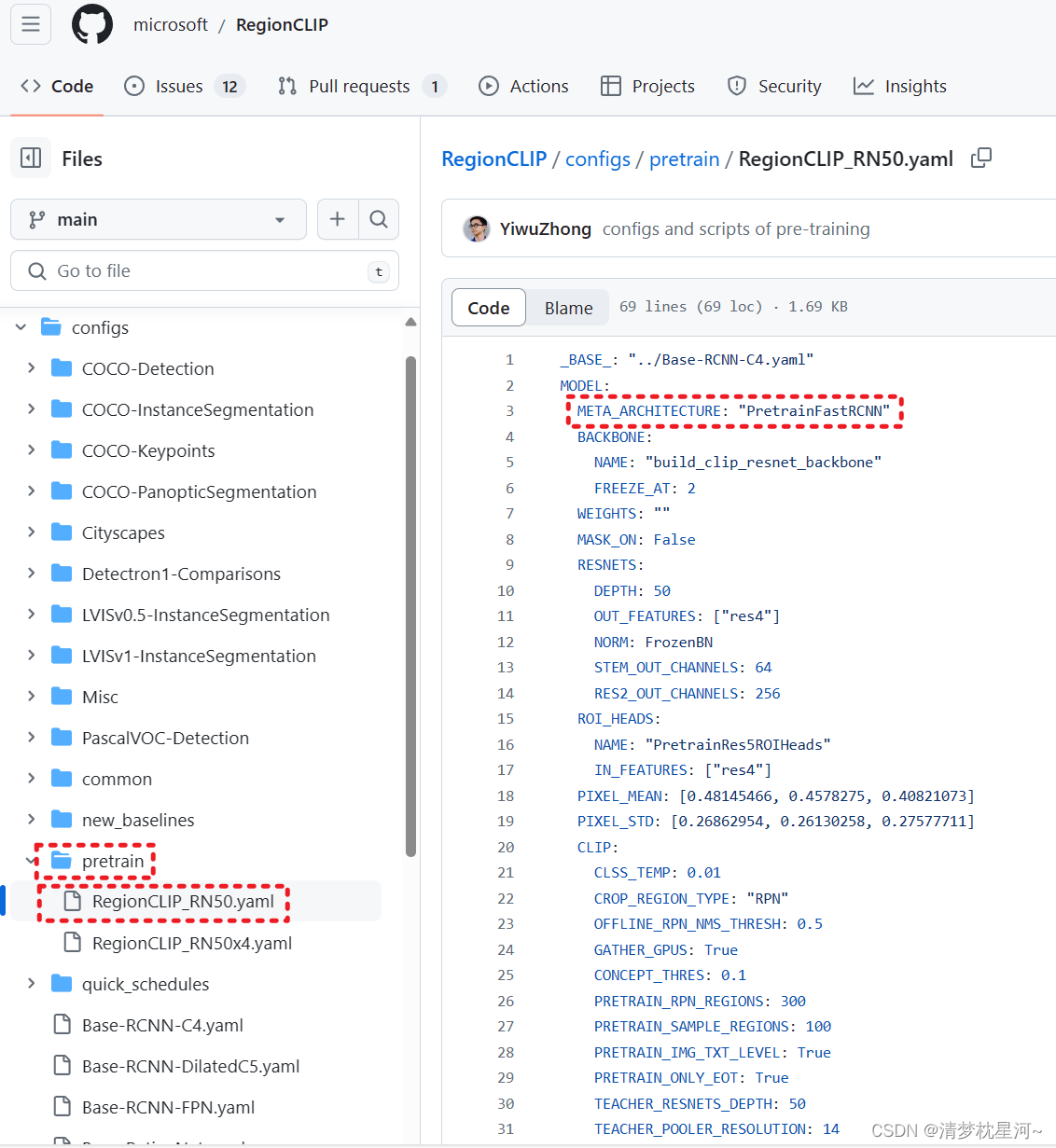
可以看到,这个预训练模型的结构是 PretrainFastRCNN
代码在
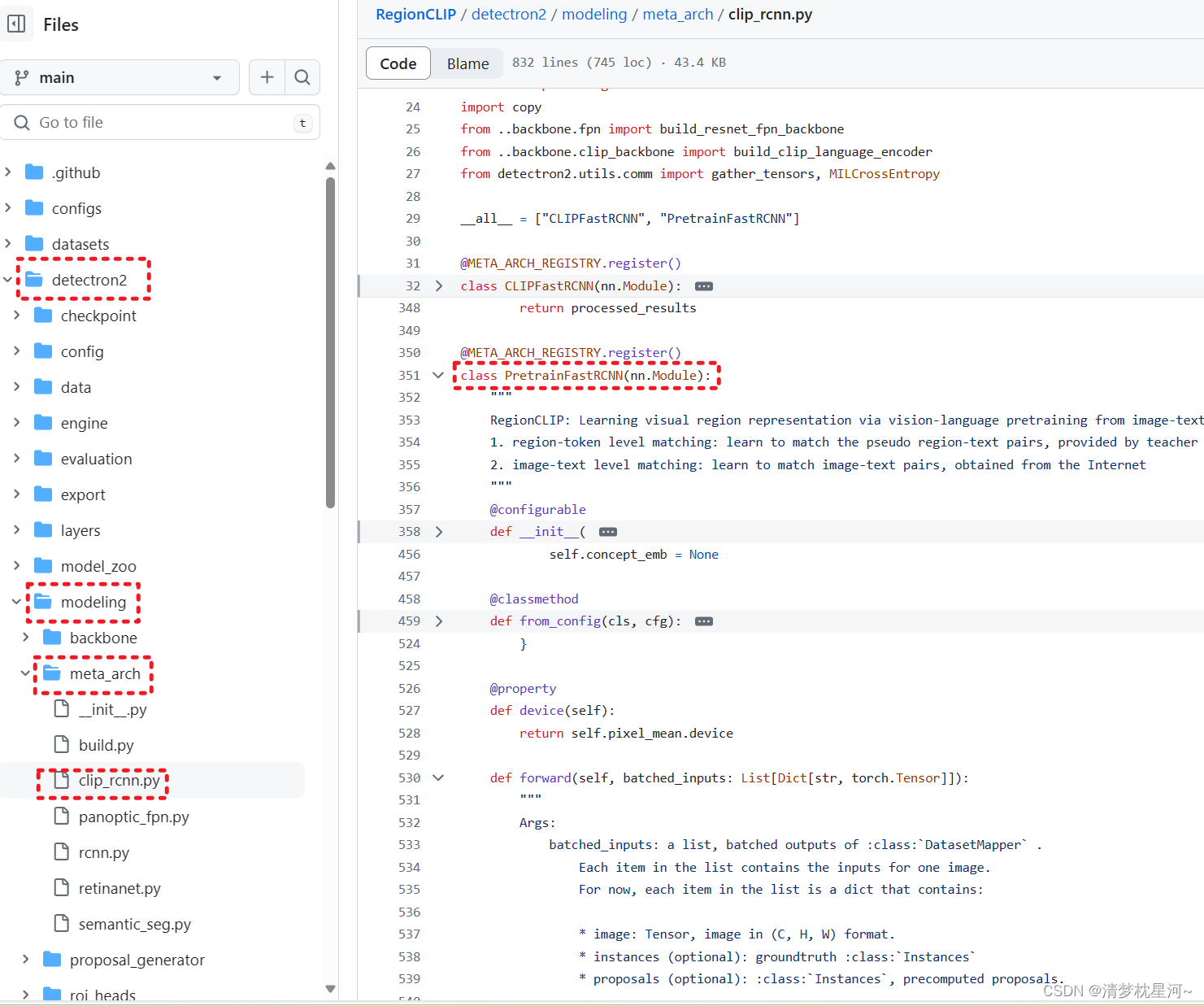
可以看到他的forward函数:
def forward(self, batched_inputs: List[Dict[str, torch.Tensor]]):
if not self.training:
return self.inference(batched_inputs)
gt_instances = None
losses = {}
# localization branch: offline modules to get the region proposals
proposals = self.get_region_proposals(batched_inputs)
global_proposals = self.create_global_proposals(batched_inputs)
# recognition branch: get 2D feature maps using the backbone of recognition branch and extract region features
images = self.preprocess_image(batched_inputs)
features = self.backbone(images.tensor)
region_feats = self.get_region_features(images, features, proposals, gt_instances)
global_feats = self.get_region_features(images, features, global_proposals, gt_instances)
# image-text level matching
if self.img_txt_level:
self.image_text_matching(batched_inputs, proposals, region_feats, losses, global_feats=global_feats)
# region-concept level matching
if self.concept_emb is not None:
self.region_concept_matching(images, proposals, gt_instances, region_feats, losses)
return losses
从上可以看到区域选取是通过 self.get_region_proposals(batched_inputs) 实现的 ,
self.get_region_features(images, features, proposals, gt_instances) 这个是获取区域图像的特征
self.region_concept_matching(images, proposals, gt_instances, region_feats, losses) 是 区域图像特征和文本特征匹配的
2.2 CLIPFastRCNN 结构
如下配置文件,可以看到整体的网络配置
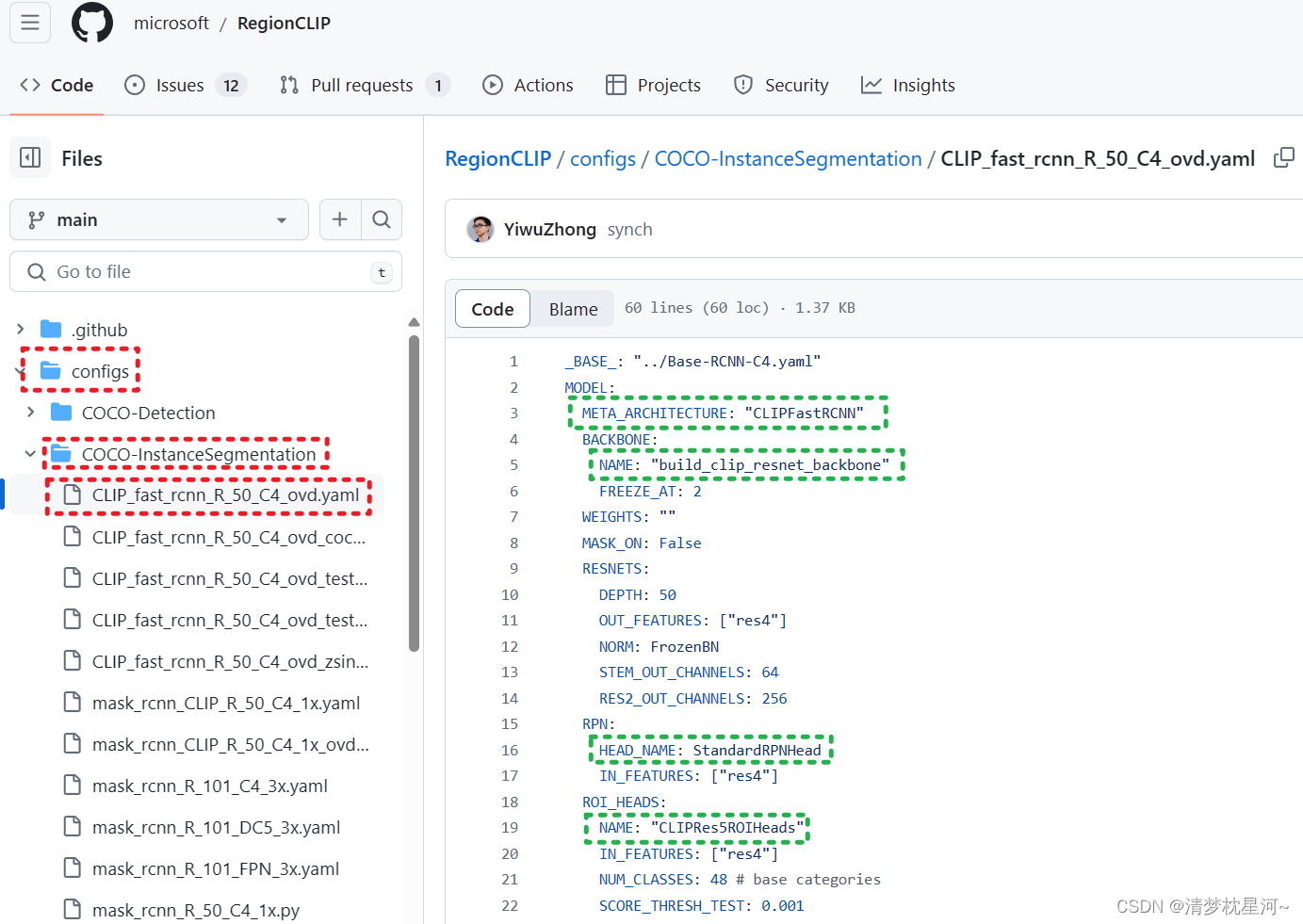
class CLIPFastRCNN(nn.Module):
"""
Fast R-CNN style where the cropping is conducted on feature maps instead of raw images.
It contains the following two components:
1. Localization branch: pretrained backbone+RPN or equivalent modules, and is able to output object proposals
2. Recognition branch: is able to recognize zero-shot regions
"""
@configurable
def __init__(
self,
*,
offline_backbone: Backbone,
backbone: Backbone,
offline_proposal_generator: nn.Module,
language_encoder: nn.Module,
roi_heads: nn.Module,
pixel_mean: Tuple[float],
pixel_std: Tuple[float],
input_format: Optional[str] = None,
vis_period: int = 0,
clip_crop_region_type: str = 'GT',
use_clip_c4: False,
use_clip_attpool: False,
offline_input_format: Optional[str] = None,
offline_pixel_mean: Tuple[float],
offline_pixel_std: Tuple[float],
):
这是定义的 CLIPFastRCNN 的初始内容,包含要传递的参数模块
其中backbone 是 build_clip_resnet_backbone,这个可以在如下找到
def build_backbone(cfg, input_shape=None):
"""
Build a backbone from `cfg.MODEL.BACKBONE.NAME`.
Returns:
an instance of :class:`Backbone`
"""
if input_shape is None:
input_shape = ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN))
backbone_name = cfg.MODEL.BACKBONE.NAME
backbone = BACKBONE_REGISTRY.get(backbone_name)(cfg, input_shape)
assert isinstance(backbone, Backbone)
return backbone
也就是通过 cfg.MODEL.BACKBONE.NAME 来定位到定义的backbone,如下:

可以看到,最终返回一个 ModifiedResNet
其中用了配置文件中的 MODEL.BACKBONE.FREEZE_AT、MODEL.RESNETS.OUT_FEATURES 和 MODEL.RESNETS.DEPTH , 具体如下:
def build_clip_resnet_backbone(cfg, input_shape):
"""
Create a CLIP-version ResNet instance from config.
Returns:
ModifiedResNet: a :class:`ModifiedResNet` instance.
"""
# port standard ResNet config to CLIP ModifiedResNet
freeze_at = cfg.MODEL.BACKBONE.FREEZE_AT
out_features = cfg.MODEL.RESNETS.OUT_FEATURES
depth = cfg.MODEL.RESNETS.DEPTH
# num_groups = cfg.MODEL.RESNETS.NUM_GROUPS
# width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP
# bottleneck_channels = num_groups * width_per_group
# in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
# out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS
# stride_in_1x1 = cfg.MODEL.RESNETS.STRIDE_IN_1X1
# res5_dilation = cfg.MODEL.RESNETS.RES5_DILATION
# deform_on_per_stage = cfg.MODEL.RESNETS.DEFORM_ON_PER_STAGE
# deform_modulated = cfg.MODEL.RESNETS.DEFORM_MODULATED
# deform_num_groups = cfg.MODEL.RESNETS.DEFORM_NUM_GROUPS
num_blocks_per_stage = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3],
200: [4, 6, 10, 6], # flag for ResNet50x4
}[depth]
vision_layers = num_blocks_per_stage
vision_width = {
50: 64,
101: 64,
200: 80, # flag for ResNet50x4
}[depth] # cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
# default configs of CLIP ModifiedResNet, but not used if only building ModifiedResNet as backbone
embed_dim = {
50: 1024,
101: 512,
200: 640, # flag for ResNet50x4
}[depth]
vision_heads = vision_width * 32 // 64
image_resolution = {
50: 224,
101: 224,
200: 288, # flag for ResNet50x4
}[depth]
# if combine {ModifiedResNet of CLIP, C4, text emb as classifier}, then has to use att_pool to match dimension
create_att_pool = True if (cfg.MODEL.ROI_HEADS.NAME in ['CLIPRes5ROIHeads', 'CLIPStandardROIHeads'] and cfg.MODEL.CLIP.USE_TEXT_EMB_CLASSIFIER)\
or cfg.MODEL.ROI_HEADS.NAME == 'PretrainRes5ROIHeads' else False
return ModifiedResNet(layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width,
out_features=out_features,
freeze_at=freeze_at,
depth=depth,
pool_vec=False,
create_att_pool=create_att_pool,
)
继续看 CLIPFastRCNN ,其中 @classmethod ----- 类方法让类模板具有记忆力,用@classmethod描述类方法,然后用"cls"代表本类。
@classmethod
def from_config(cls, cfg):
# create independent backbone & RPN
if cfg.MODEL.CLIP.CROP_REGION_TYPE == "RPN":
# create offline cfg for the pretrained backbone & RPN
from detectron2.config import get_cfg
offline_cfg = get_cfg()
offline_cfg.merge_from_file(cfg.MODEL.CLIP.OFFLINE_RPN_CONFIG)
if cfg.MODEL.CLIP.OFFLINE_RPN_LSJ_PRETRAINED: # large-scale jittering (LSJ) pretrained RPN
offline_cfg.MODEL.BACKBONE.FREEZE_AT = 0 # make all fronzon layers to "SyncBN"
offline_cfg.MODEL.RESNETS.NORM = "SyncBN" # 5 resnet layers
offline_cfg.MODEL.FPN.NORM = "SyncBN" # fpn layers
offline_cfg.MODEL.RPN.CONV_DIMS = [-1, -1] # rpn layers
if cfg.MODEL.CLIP.OFFLINE_RPN_NMS_THRESH:
offline_cfg.MODEL.RPN.NMS_THRESH = cfg.MODEL.CLIP.OFFLINE_RPN_NMS_THRESH # 0.9
if cfg.MODEL.CLIP.OFFLINE_RPN_POST_NMS_TOPK_TEST:
offline_cfg.MODEL.RPN.POST_NMS_TOPK_TEST = cfg.MODEL.CLIP.OFFLINE_RPN_POST_NMS_TOPK_TEST # 1000
# create offline backbone and RPN
offline_backbone = build_backbone(offline_cfg)
offline_rpn = build_proposal_generator(offline_cfg, offline_backbone.output_shape())
# convert to evaluation mode
for p in offline_backbone.parameters(): p.requires_grad = False
for p in offline_rpn.parameters(): p.requires_grad = False
offline_backbone.eval()
offline_rpn.eval()
# region proposals are ground-truth boxes
elif cfg.MODEL.CLIP.CROP_REGION_TYPE == "GT":
offline_backbone = None
offline_rpn = None
offline_cfg = None
backbone = build_backbone(cfg)
# build language encoder
if cfg.MODEL.CLIP.GET_CONCEPT_EMB: # extract concept embeddings
language_encoder = build_clip_language_encoder(cfg)
else:
language_encoder = None
roi_heads = build_roi_heads(cfg, backbone.output_shape())
return {
"offline_backbone": offline_backbone,
"offline_proposal_generator": offline_rpn,
"backbone": backbone,
"language_encoder": language_encoder,
"roi_heads": roi_heads,
"input_format": cfg.INPUT.FORMAT,
"vis_period": cfg.VIS_PERIOD,
"pixel_mean": cfg.MODEL.PIXEL_MEAN,
"pixel_std": cfg.MODEL.PIXEL_STD,
"clip_crop_region_type" : cfg.MODEL.CLIP.CROP_REGION_TYPE,
"use_clip_c4": cfg.MODEL.BACKBONE.NAME == "build_clip_resnet_backbone",
"use_clip_attpool": cfg.MODEL.ROI_HEADS.NAME in ['CLIPRes5ROIHeads', 'CLIPStandardROIHeads'] and cfg.MODEL.CLIP.USE_TEXT_EMB_CLASSIFIER,
"offline_input_format": offline_cfg.INPUT.FORMAT if offline_cfg else None,
"offline_pixel_mean": offline_cfg.MODEL.PIXEL_MEAN if offline_cfg else None,
"offline_pixel_std": offline_cfg.MODEL.PIXEL_STD if offline_cfg else None,
}
从上面可以看到 backbone ,language_encoder,roi_heads 构建相应的模块,基本上CLIPFastRCNN 的模块都在里面了。不过里面的 offline_backbone 让我疑惑,不知道这个是如何起作用的,发挥什么功能?我判断是加载离线模型 就是做过预训练的模型,用来生成proposals的,感觉这段代码不太好看,而且后面也不清晰怎么处理的。
还可以进一步看forward函数,直观了解数据处理:
def forward(self, batched_inputs: List[Dict[str, torch.Tensor]]):
"""
Args:
batched_inputs: a list, batched outputs of :class:`DatasetMapper` .
Each item in the list contains the inputs for one image.
For now, each item in the list is a dict that contains:
* image: Tensor, image in (C, H, W) format.
* instances (optional): groundtruth :class:`Instances`
* proposals (optional): :class:`Instances`, precomputed proposals.
Other information that's included in the original dicts, such as:
* "height", "width" (int): the output resolution of the model, used in inference.
See :meth:`postprocess` for details.
Returns:
list[dict]:
Each dict is the output for one input image.
The dict contains one key "instances" whose value is a :class:`Instances`.
The :class:`Instances` object has the following keys:
"pred_boxes", "pred_classes", "scores", "pred_masks", "pred_keypoints"
"""
if not self.training:
return self.inference(batched_inputs)
if "instances" in batched_inputs[0]:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
else:
gt_instances = None
# localization branch: offline modules to get the region proposals
with torch.no_grad():
if self.clip_crop_region_type == "GT": # from ground-truth
proposals = []
for r_i, b_input in enumerate(batched_inputs):
this_gt = copy.deepcopy(b_input["instances"]) # Instance
gt_boxes = this_gt._fields['gt_boxes'].to(self.device)
this_gt._fields = {'proposal_boxes': gt_boxes, 'objectness_logits': torch.ones(gt_boxes.tensor.size(0)).to(self.device)}
proposals.append(this_gt)
elif self.clip_crop_region_type == "RPN": # from the backbone & RPN of standard Mask-RCNN, trained on base classes
if self.offline_backbone.training or self.offline_proposal_generator.training: # was set to True in training script
self.offline_backbone.eval()
self.offline_proposal_generator.eval()
images = self.offline_preprocess_image(batched_inputs)
features = self.offline_backbone(images.tensor)
if self.offline_proposal_generator is not None:
proposals, _ = self.offline_proposal_generator(images, features, None)
# recognition branch: get 2D feature maps using the backbone of recognition branch
images = self.preprocess_image(batched_inputs)
features = self.backbone(images.tensor)
# Given the proposals, crop region features from 2D image features and classify the regions
if self.use_clip_c4: # use C4 + resnet weights from CLIP
if self.use_clip_attpool: # use att_pool from CLIP to match dimension
_, detector_losses = self.roi_heads(images, features, proposals, gt_instances, res5=self.backbone.layer4, attnpool=self.backbone.attnpool)
else: # use mean pool
_, detector_losses = self.roi_heads(images, features, proposals, gt_instances, res5=self.backbone.layer4)
else: # regular detector setting
if self.use_clip_attpool: # use att_pool from CLIP to match dimension
_, detector_losses = self.roi_heads(images, features, proposals, gt_instances, attnpool=self.backbone.bottom_up.attnpool)
else: # use mean pool
_, detector_losses = self.roi_heads(images, features, proposals, gt_instances)
if self.vis_period > 0:
storage = get_event_storage()
if storage.iter % self.vis_period == 0:
self.visualize_training(batched_inputs, proposals)
#visualize_proposals(batched_inputs, proposals, self.input_format)
losses = {}
losses.update(detector_losses)
return losses
可以看到数据输入 batched_inputs 的处理,features = self.backbone(images.tensor) 这一步完成特征提取,features里包含了文本特征,后续进入 roi_heads 进行损失计算。
以上就是RegionCLIP的 CLIPFastRCNN 的网络结构对应代码解析。









![[C++初阶]初识C++(一)—————命名空间和缺省函数](https://img-blog.csdnimg.cn/direct/0885298cb0c64fcfaf9046f95acc820e.png)