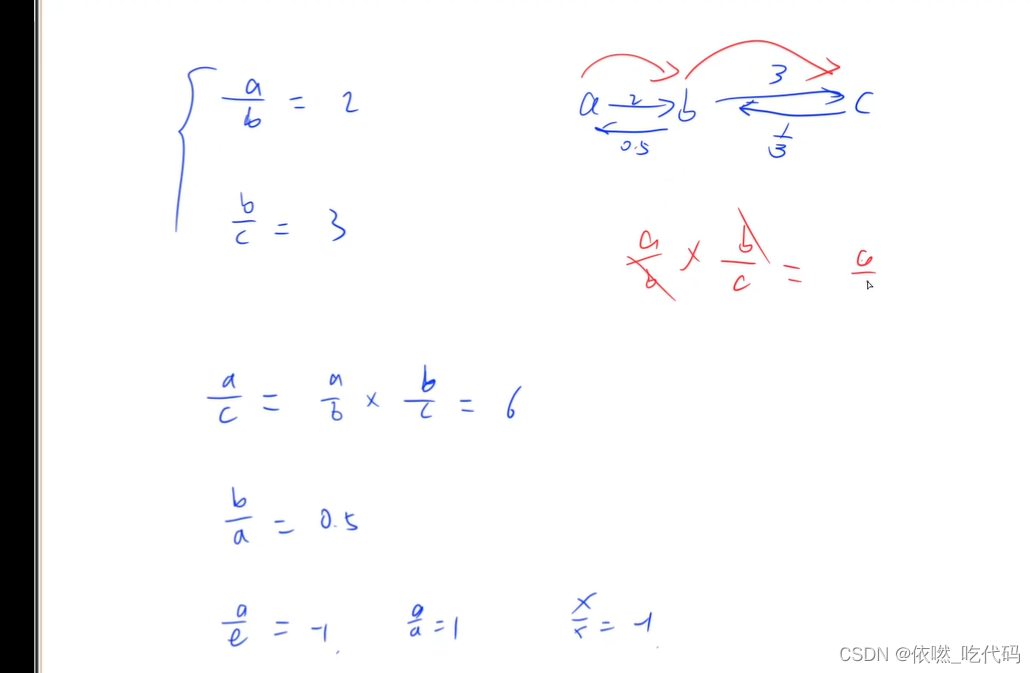目录
前言
1--Tensor RT基本概念
2--推理流程
3--实例代码
前言
以下 Tensor RT 的基本概念和推理流程均为博主自我的理解,可能部分内存会存在错误或偏差,仅供参考!
1--Tensor RT基本概念
① Logger:日志记录器,可用于记录模型编译的过程;
② Builder:可用于创建 Network,对模型进行序列化生成engine;
③ Network:由 Builder 的创建,最初只是一个空的容器;
④ Parser:用于解析 Onnx 等模型;
⑥ context:上接 engine,下接 inference,因此解释为上下文;
2--推理流程
结合之前博主的相关笔记,根据博主的个人理解,将Tensor RT的推理流程表达为下图:

① 基于 Tensor RT 进行模型的推理,从宏观上可分为三个阶段,即输入数据的前处理(preprocess)、模型推理(inference)和推理结果的后处理(postprocess);
② 在模型推理中,一般会将 Onnx 等格式的模型通过编译(build)生成推理引擎(engine),engine 可以通过序列化(serialize)的方式进行永久存储,永久存储的 engine 则可以通过反序列化(deserialize)的方式进行加载;
③ 在正式推理(inference)前,需要手动申请 Cuda 的内存(memory),以存储输入和输出数据流,数据将以流(stream)的形式进行传递;推理前,输入数据(input_data)需要从主机(host)转移到 Cuda(device)中,推理结束后的推理结果则需要从 Cuda(device)转移到主机(host)的内存当中;
④ 编译模型时,必须需要定义 logger,并使用定义的 parser 进行解析模型,config用于配置模型,如通过 profile 设定模型的动态输入尺寸,通过 builder 可以创建序列化的 engine;
⑤ 序列化的 engine 需要经过反序列化,才能用于创建 context,最后进行推理;
3--实例代码
以下提供一个使用 Tensor RT 进行完整推理的代码,使用的 Onnx 模型可参考博主之前的博客(导出动态的Onnx模型)。
import pycuda
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import torch
import numpy as np
# 前处理
def preprocess(data):
data = np.asarray(data)
return data
# 后处理
def postprocess(data):
data = np.reshape(data, (B, 256, H, W))
return data
# 创建build_engine类
class build_engine():
def __init__(self, onnx_path):
super(build_engine, self).__init__()
self.onnx = onnx_path
self.engine = self.onnx2engine() # 调用 onnx2engine 函数生成 engine
def onnx2engine(self):
# 创建日志记录器
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# 显式batch_size,batch_size有显式和隐式之分
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
# 创建builder,用于创建network
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(EXPLICIT_BATCH) # 创建network(初始为空)
# 创建config
config = builder.create_builder_config()
profile = builder.create_optimization_profile() # 创建profile
profile.set_shape("input", (1,3,128,128), (3,3,256,256), (5,3,512,512)) # 设置动态输入,分别对应:最小尺寸、最佳尺寸、最大尺寸
config.add_optimization_profile(profile)
config.max_workspace_size = 1<<30 # 允许TensorRT使用1GB的GPU内存,<<表示左移,左移30位即扩大2^30倍,使用2^30 bytes即 1 GB
# 创建parser用于解析模型
parser = trt.OnnxParser(network, TRT_LOGGER)
# 读取并解析模型
onnx_model_file = self.onnx # Onnx模型的地址
model = open(onnx_model_file, 'rb')
if not parser.parse(model.read()): # 解析模型
for error in range(parser.num_errors):
print(parser.get_error(error)) # 打印错误(如果解析失败,根据打印的错误进行Debug)
# 创建序列化engine
engine = builder.build_serialized_network(network, config)
return engine
def get_engine(self):
return self.engine # 返回 engine
# 分配内存缓冲区
def Allocate_memory(engine, context):
bindings = []
for binding in engine:
binding_idx = engine.get_binding_index(binding) # 遍历获取对应的索引
size = trt.volume(context.get_binding_shape(binding_idx))
# context.get_binding_shape(binding_idx): 获取对应索引的Shape,例如input的Shape为(1, 3, H, W)
# trt.volume(shape): 根据shape计算分配内存
dtype = trt.nptype(engine.get_binding_dtype(binding))
# engine.get_binding_dtype(binding): 获取对应index或name的类型
# trt.nptype(): 映射到numpy类型
if engine.binding_is_input(binding): # 当前index为网络的输入input
input_buffer = np.ascontiguousarray(input_data) # 将内存不连续存储的数组转换为内存连续存储的数组,运行速度更快
input_memory = cuda.mem_alloc(input_data.nbytes) # cuda.mem_alloc()申请内存
bindings.append(int(input_memory))
else:
output_buffer = cuda.pagelocked_empty(size, dtype)
output_memory = cuda.mem_alloc(output_buffer.nbytes)
bindings.append(int(output_memory))
return input_buffer, input_memory, output_buffer, output_memory, bindings
if __name__ == "__main__":
# 设置输入参数,生成输入数据
Batch_size = 3
Channel = 3
Height = 256
Width = 256
input_data = torch.rand((Batch_size, Channel, Height, Width))
# 前处理
input_data = preprocess(input_data)
# 生成engine
onnx_model_file = "./Dynamics_InputNet.onnx"
engine_build = build_engine(onnx_model_file)
engine = engine_build.get_engine()
# 生成context
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
runtime = trt.Runtime(TRT_LOGGER)
engine = runtime.deserialize_cuda_engine(engine)
context = engine.create_execution_context()
# 绑定上下文
B, C, H, W = input_data.shape
context.set_binding_shape(engine.get_binding_index("input"), (B, 3, H, W))
# 分配内存缓冲区
input_buffer, input_memory, output_buffer, output_memory, bindings = Allocate_memory(engine, context)
# 创建Cuda流
stream = cuda.Stream()
# 拷贝数据到GPU (host -> device)
cuda.memcpy_htod_async(input_memory, input_buffer, stream) # 异步拷贝数据
# 推理
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# 将GPU得到的推理结果 拷贝到主机(device -> host)
cuda.memcpy_dtoh_async(output_buffer, output_memory, stream)
# 同步Cuda流
stream.synchronize()
# 后处理
output_data = postprocess(output_buffer)
print("output.shape is : ", output_data.shape)运行结果如下: