在计算机科学中,二叉树是一种重要的数据结构,广泛应用于各种算法和程序设计中。二叉树的遍历是二叉树操作中的基础问题之一,其目的是以某种规则访问二叉树的每个结点,使得每个结点被且仅被访问一次。给定一个具有n个结点的二叉树,我们需要编写一个递归过程,以O(n)的时间复杂度输出每个结点的关键字。
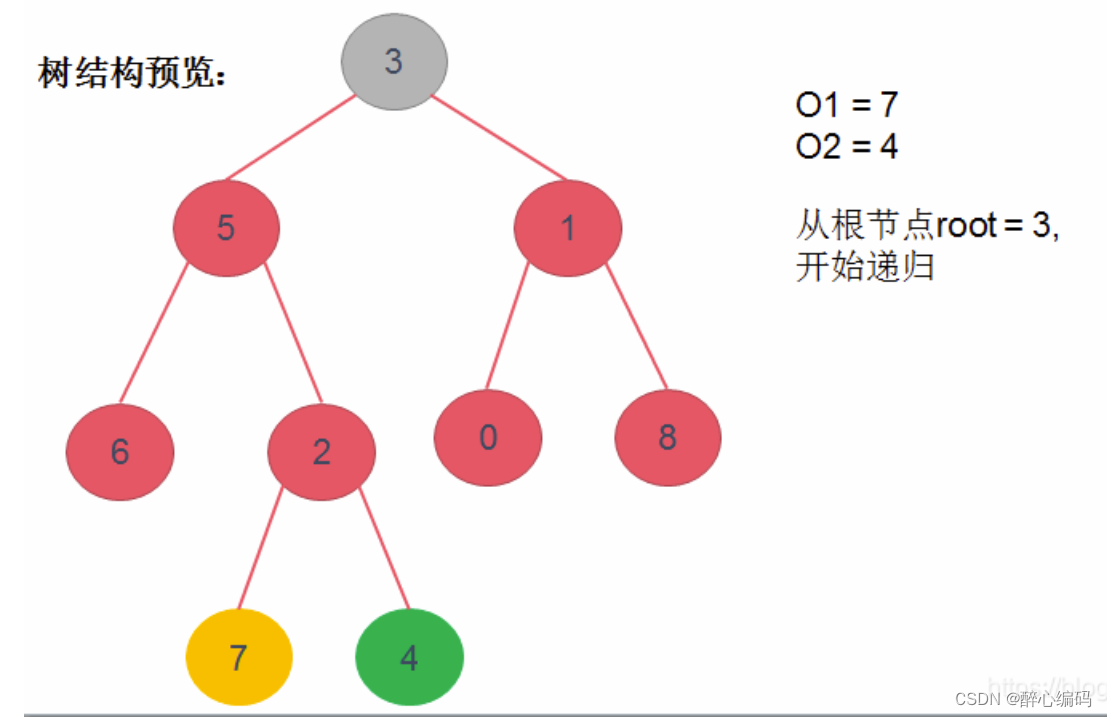
1.二叉树结构
首先,我们需要明确二叉树的基本结构。在C语言中,二叉树结点通常定义为包含数据域和左右孩子指针的结构体。数据域存储了结点的关键字或值,而左右孩子指针则指向该结点的左孩子和右孩子。
typedef struct TreeNode {
int key; // 结点的关键字
struct TreeNode *left; // 左孩子指针
struct TreeNode *right; // 右孩子指针
} TreeNode;
2.遍历算法
接下来,我们分析二叉树的遍历算法。常见的二叉树遍历方法包括前序遍历、中序遍历和后序遍历。每种遍历方法都有其特定的访问顺序。在这里,我们假设要求并没有明确指定使用哪一种遍历方法,因此我们可以选择任何一种遍历方法来实现。为了简化问题,我们将采用前序遍历作为示例,即先访问根结点,然后遍历左子树,最后遍历右子树。
前序遍历的递归算法可以描述如下:
访问根结点。
递归遍历左子树。
递归遍历右子树。
以下是前序遍历的伪代码表示:
2.1 伪代码
PreOrderTraversal(node):
if node is not null:
print(node.key) // 访问根结点
PreOrderTraversal(node.left) // 递归遍历左子树
PreOrderTraversal(node.right) // 递归遍历右子树
将伪代码转换为C语言代码,我们可以得到以下实现:
2.2 C代码
#include <stdio.h>
#include <stdlib.h>
// 二叉树结点定义
typedef struct TreeNode {
int key;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
// 创建新结点的函数(根据需要实现)
TreeNode* createNode(int key) {
TreeNode* newNode = (TreeNode*)malloc(sizeof(TreeNode));
if (newNode == NULL) {
printf("Memory allocation failed.\n");
exit(EXIT_FAILURE);
}
newNode->key = key;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
// 前序遍历函数
void preOrderTraversal(TreeNode* node) {
if (node != NULL) {
printf("%d ", node->key); // 访问根结点
preOrderTraversal(node->left); // 递归遍历左子树
preOrderTraversal(node->right); // 递归遍历右子树
}
}
// 主函数,用于测试遍历算法
int main() {
// 构建一个简单的二叉树作为示例(这里仅作为示意,实际构建过程可能更复杂)
TreeNode* root = createNode(1);
root->left = createNode(2);
root->right = createNode(3);
root->left->left = createNode(4);
root->left->right = createNode(5);
// 执行前序遍历并输出结点关键字
printf("Pre-order traversal of binary tree:\n");
preOrderTraversal(root);
printf("\n");
// 释放二叉树占用的内存(根据需要实现)
// ...(这里省略了释放内存的代码)
return 0;
}
上述代码定义了一个二叉树结点结构,并实现了前序遍历的递归函数。在main函数中,我们创建了一个简单的二叉树,并调用preOrderTraversal函数进行遍历,输出每个结点的关键字。注意,这里为了简化示例,我们省略了内存释放的代码,实际使用中应该在不需要二叉树时释放其占用的内存,避免内存泄漏。
3.时间复杂度
关于时间复杂度,由于每个结点只被访问一次,且递归调用的次数与结点的数量成正比,因此该算法的时间复杂度为O(n),其中n为二叉树的结点数量。这是最优的时间复杂度,因为我们必须至少访问每个结点一次才能输出其关键字。
4.总结
总结来说,我们利用递归的思想实现了二叉树的前序遍历,并输出了每个结点的关键字。该算法的时间复杂度为O(n),满足题目要求,并且在实际应用中具有广泛的适用性。
4.1递归遍历的深入理解
递归遍历二叉树是算法学习中的基础内容,但要想真正理解和掌握它,需要深入理解递归的本质和二叉树的结构特点。递归,简单来说,就是函数自己调用自己。在二叉树的遍历中,递归体现在对每个结点的处理上:先处理当前结点,然后递归处理左子树和右子树。
4.2递归遍历的优点与挑战
递归遍历的优点在于其代码简洁易懂,逻辑清晰。它能够自然地反映出二叉树的结构特点,使得算法的实现变得直观和简单。然而,递归遍历也面临着一些挑战,比如递归深度的限制和栈空间的消耗。当二叉树的深度很大时,递归遍历可能会导致栈溢出,因此需要谨慎使用。
4.3递归遍历的变种与应用
除了前序遍历,递归遍历还可以应用于中序遍历和后序遍历。这两种遍历方法在处理结点的顺序上有所不同,但基本的递归思想和实现方式是相似的。中序遍历按照“左-根-右”的顺序访问结点,常用于二叉搜索树的排序操作;后序遍历则按照“左-右-根”的顺序访问结点,常用于先处理子问题再处理父问题的场景。
4.4 递归遍历的性能优化
虽然递归遍历的时间复杂度已经达到了最优的O(n),但在实际应用中,我们还可以通过一些技巧来进一步优化其性能。例如,可以使用迭代法来模拟递归过程,从而避免栈空间的额外消耗;还可以使用尾递归优化来减少递归调用的开销,提高算法的执行效率。
5.结语与展望
通过本文的阐述,我们深入理解了递归遍历二叉树的原理和实现方法,并探讨了其在实际应用中的优点与挑战。递归遍历作为二叉树操作的基础算法之一,不仅具有理论价值,更具有广泛的实用价值。在未来的学习和工作中,我们将继续探索和优化这一算法,以适应更加复杂和多样的应用场景。