机器学习(算法篇)完整教程(附代码资料)主要内容讲述:机器学习算法课程定位、目标,K-近邻算法定位,目标,学习目标,1 什么是K-近邻算法,1 Scikit-learn工具介绍,2 K-近邻算法API。K-近邻算法,1.4 k值的选择学习目标,学习目标,1 kd树简介,2 构造方法,3 案例分析,4 总结。K-近邻算法,1.6 案例:鸢尾花种类预测--数据集介绍学习目标,1 案例:鸢尾花种类预测,2 scikit-learn中数据集介绍,1 什么是特征预处理,2 归一化,3 标准化。K-近邻算法,1.8 案例:鸢尾花种类预测—流程实现学习目标,1 再识K-近邻算法API,2 案例:鸢尾花种类预测,总结,1 什么是交叉验证(cross validation),2 什么是网格搜索(Grid Search)。线性回归,2.1 线性回归简介学习目标,1 线性回归应用场景,2 什么是线性回归,1 线性回归API,2 举例,1 常见函数的导数。线性回归,2.6 梯度下降法介绍学习目标,1 全梯度下降算法(FG),2 随机梯度下降算法(SG),3 小批量梯度下降算法(mini-bantch),4 随机平均梯度下降算法(SAG),5 算法比较。线性回归,2.8 欠拟合和过拟合学习目标,1 定义,2 原因以及解决办法,3 正则化,4 维灾难【拓展知识】。线性回归,2.9 正则化线性模型学习目标,1 Ridge Regression (岭回归,又名 Tikhonov regularization),2 Lasso Regression(Lasso 回归),3 Elastic Net (弹性网络),4 Early Stopping [了解],1 API。逻辑回归,3.4 分类评估方法学习目标,1.分类评估方法,2 ROC曲线与AUC指标,3 总结,1 曲线绘制,2 意义解释。决策树算法,4.4 特征工程-特征提取学习目标,1 特征提取,2 字典特征提取,3 文本特征提取。决策树算法,4.5 决策树算法api学习目标,1 泰坦尼克号数据,2 步骤分析,3 代码过程,3 决策树可视化,学习目标。集成学习,5.3 Boosting学习目标,1.boosting集成原理,2 GBDT(了解),3.XGBoost【了解】,4 什么是泰勒展开式【拓展】,学习目标。聚类算法,6.4 模型评估学习目标,1 误差平方和(SSE \The sum of squares due to error):,2 “肘”方法 (Elbow method) — K值确定,3 轮廓系数法(Silhouette Coefficient),4 CH系数(Calinski-Harabasz Index),5 总结。聚类算法,6.6 特征降维学习目标,1 降维,2 特征选择,3 主成分分析,1 需求,2 分析。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:

K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.6 案例:鸢尾花种类预测--数据集介绍
本实验介绍了使用Python进行机器学习的一些基本概念。 在本案例中,将使用K-Nearest Neighbor(KNN)算法对鸢尾花的种类进行分类,并测量花的特征。
本案例目的:
- 遵循并理解完整的机器学习过程
- 对机器学习原理和相关术语有基本的了解。
- 了解评估机器学习模型的基本过程。
1 案例:鸢尾花种类预测
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

2 scikit-learn中数据集介绍
2.1 scikit-learn数据集API介绍
-
sklearn.datasets
-
加载获取流行数据集
-
datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
-
datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
2.1.1 sklearn小数据集
- sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
2.1.2 sklearn大数据集
-
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
2.2 sklearn数据集返回值介绍
-
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
-
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
from sklearn.datasets import load_iris
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
2.3 查看数据分布
通过创建一些图,以查看不同类别是如何通过特征来区分的。 在理想情况下,标签类将由一个或多个特征对完美分隔。 在现实世界中,这种理想情况很少会发生。
-
seaborn介绍
-
Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以让你轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
- 安装 pip3 install seaborn
-
seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
- sns.lmplot() 里的 x, y 分别代表横纵坐标的列名,
- data= 是关联到数据集,
- hue=*代表按照 species即花的类别分类显示,
- fit_reg=是否进行线性拟合。
-
[参考链接: api链接](
%matplotlib inline
# 内嵌绘图
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 把数据转换成dataframe的格式
iris_d = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_d['Species'] = iris.target
def plot_iris(iris, col1, col2):
sns.lmplot(x = col1, y = col2, data = iris, hue = "Species", fit_reg = False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('鸢尾花种类分布图')
plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
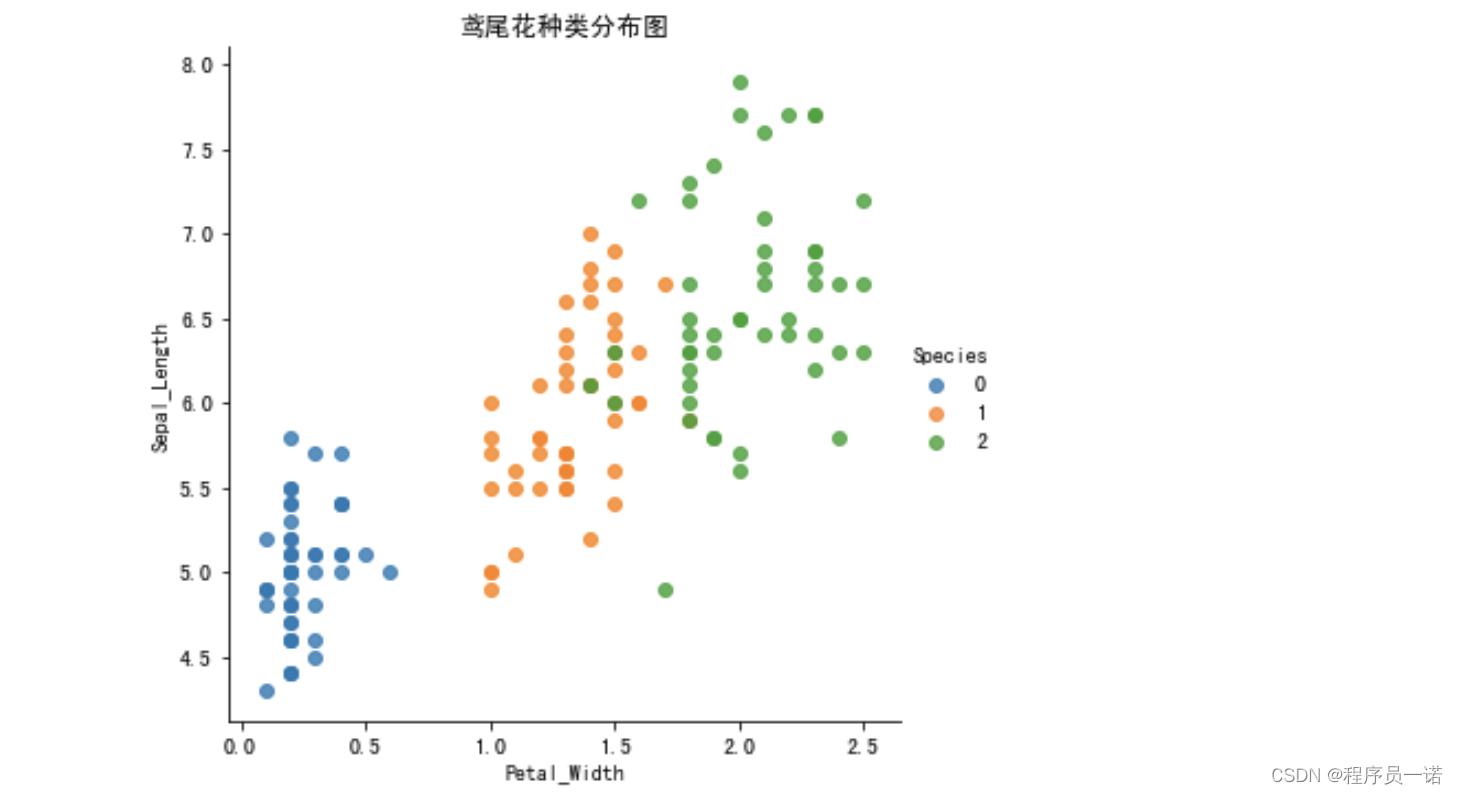
2.4 数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分api
-
sklearn.model_selection.train_test_split(arrays, *options)
-
x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1、获取鸢尾花数据集
iris = load_iris()
# 对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
1.7 特征工程-特征预处理
1 什么是特征预处理
1.1 特征预处理定义
scikit-learn的解释
provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
翻译过来:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
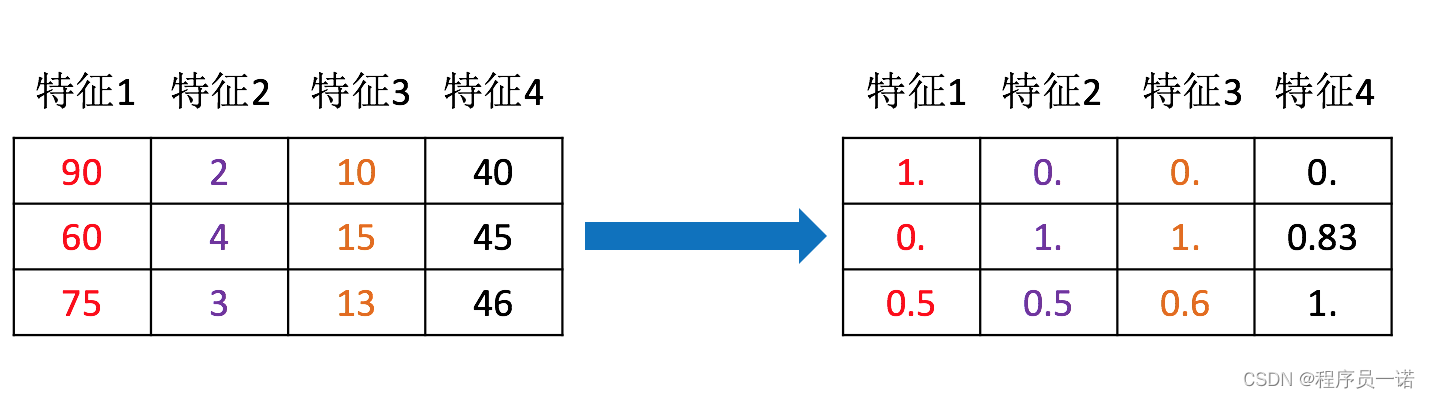
为什么我们要进行归一化/标准化?
- 特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
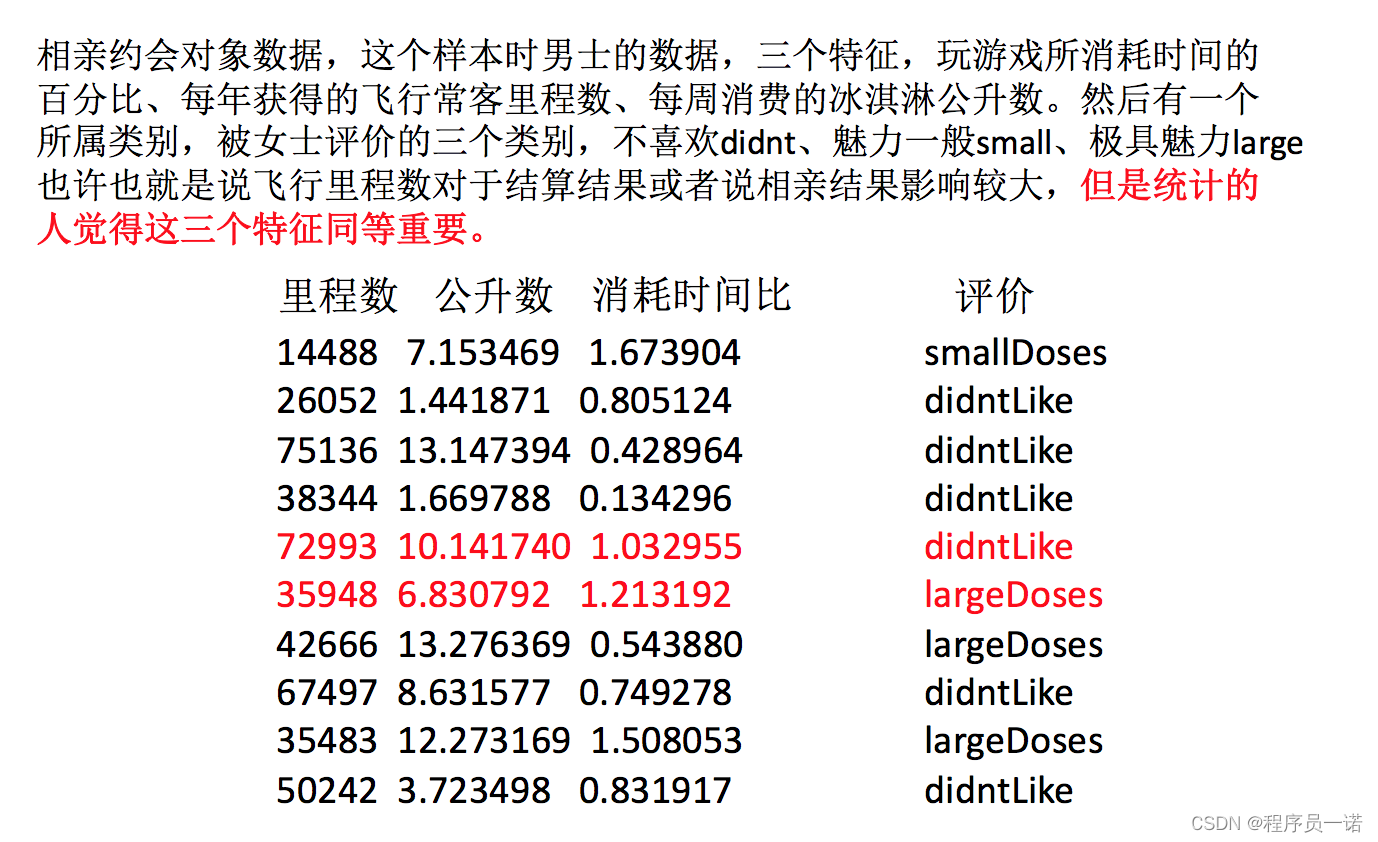
举例:约会对象数据
我们需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格
1.2 包含内容(数值型数据的无量纲化)
- 归一化
- 标准化
1.3 特征预处理API
sklearn.preprocessing
2 归一化
2.1 定义
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
2.2 公式
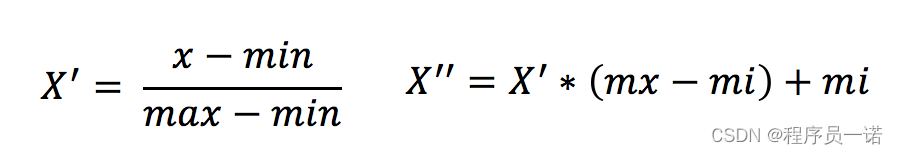
作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
那么怎么理解这个过程呢?我们通过一个例子

2.3 API
-
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
-
MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
-
返回值:转换后的形状相同的array
2.4 数据计算
我们对以下数据进行运算,在dating.txt中。保存的就是之前的约会对象数据
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
- 分析
1、实例化MinMaxScalar
2、通过fit_transform转换
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
归一化演示
:return: None
"""
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = MinMaxScaler(feature_range=(2, 3))
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("最小值最大值归一化处理的结果:\n", data)
return None
返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
.. ... ... ... ...
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最小值最大值归一化处理的结果:
[[ 2.44832535 2.39805139 2.56233353]
[ 2.15873259 2.34195467 2.98724416]
[ 2.28542943 2.06892523 2.47449629]
...,
[ 2.29115949 2.50910294 2.51079493]
[ 2.52711097 2.43665451 2.4290048 ]
[ 2.47940793 2.3768091 2.78571804]]
问题:如果数据中异常点较多,会有什么影响?
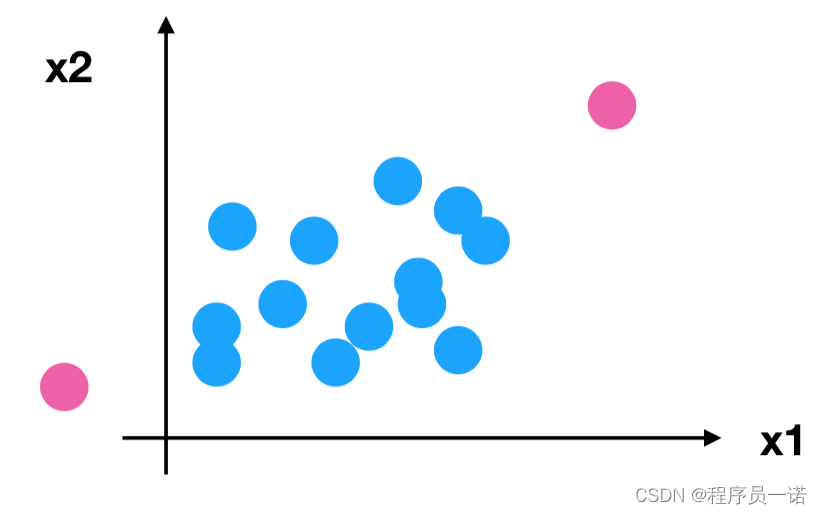
2.5 归一化总结
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
怎么办?
3 标准化
3.1 定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
3.2 公式
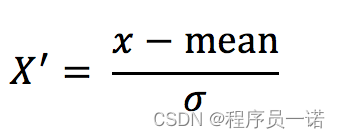
作用于每一列,mean为平均值,σ为标准差
所以回到刚才异常点的地方,我们再来看看标准化
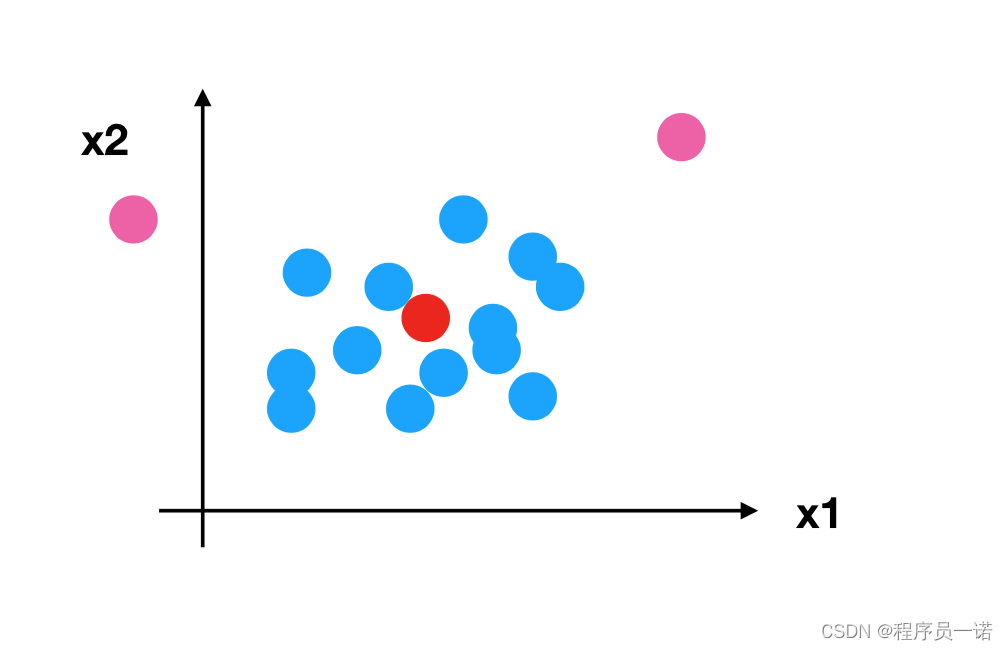
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
3.3 API
-
sklearn.preprocessing.StandardScaler( )
-
处理之后每列来说所有数据都聚集在均值0附近标准差差为1
-
StandardScaler.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
-
返回值:转换后的形状相同的array
3.4 数据计算
同样对上面的数据进行处理
- 分析
1、实例化StandardScaler
2、通过fit_transform转换
import pandas as pd
from sklearn.preprocessing import StandardScaler
def stand_demo():
"""
标准化演示
:return: None
"""
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
.. ... ... ... ...
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
标准化的结果:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...,
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]
每一列特征的平均值:
[ 3.36354210e+04 6.55996083e+00 8.32072997e-01]
每一列特征的方差:
[ 4.81628039e+08 1.79902874e+01 2.46999554e-01]
3.5 标准化总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。