文章目录
- 一、错误分析
- 二、快速构建系统然后迭代
- 三、训练和测试的不同数据分布
- 1、不匹配数据的偏差和方差
- 2、解决数据不匹配问题。
- 四、迁移学习 transfer learning
- 五、多任务学习 multi-task learning
- 六、端到端 end-to-end learning
一、错误分析
当我们在构建一个系统时,我们可以采用人工方法来分析错误率主要是由什么造成的。
比如一个识别猫的系统,我们可以取出100张分析错误的照片,来看分析错误的主要原因是什么,比如将狗识别成猫的概率有百分之40,因为图片模糊而识别错误占百分之9等,我们就可以有一个很好的理由来去通过狗与猫的特征来提高识别准确率。
但是这个错误也可能是由于我们一开始标签标记错了
比如一张猫的图片,我们一开始标记成了0,不是猫,但是最后系统识别出为1,我们也可以采用错误分析来人工检测这个标记错误的情况值不值得我们花费时间去修改错误,如果所占比例比较小,则我们就可以忽略这个错误。
二、快速构建系统然后迭代
如果我们在研究一个全新的领域,没有大量论文等支撑,则我们可以先确定开发集与测试集和度量指标,之后快速搭建起我们的系统,不必太复杂,之后通过偏差/方差以及人工进行错误分析,来提高我们系统的准确率。
但是如果我们研究的是一个很成熟的领域或者我们研究的领域有大量论文支撑,那么就不适合该方法。
三、训练和测试的不同数据分布
1、不匹配数据的偏差和方差
训练数据和开发集/测试集的分布不同
train 与 tarin-dev 有相同的分布
dev 与 test 有相同的分布。
这里我们把训练数据集分为tarin set和train-dev set.
神经网络只能看到train set,通过train set来训练模型.
训练完模型之后 将train-dev 放入模型来检测error。
若 human-level error 为0%,train-error 为1%,train-dev error 为9%,dev error 为10%,则证明我们的模型方差过大。
若 human-level error 为0%,train-error 为1%,train-dev error 为1.5%,dev error 为10%,则证明我们模型的data mismatch 问题过大,我们应该解决data mismatch 问题。
若 human-level error 为0%,train-error 为10%,train-dev error 为11%,dev error 为11.5%,则证明我们模型的可避免偏差问题过大。
若 human-level error 为0%,train-error 为10%,train-dev error 为11%,dev error 为20%,则证明我们模型的不仅可避免偏差问题过大 而且data mismatch 问题也过大。
同样 如果有test error ,我们可以根据它与dev-error 的差距来看是否模型对于dev set 出现了过拟合的现象。
同样,也可能出现在dev set的error 小于 train 与train-dev。这可能是由于我们关注的数据集比训练集容易操作。
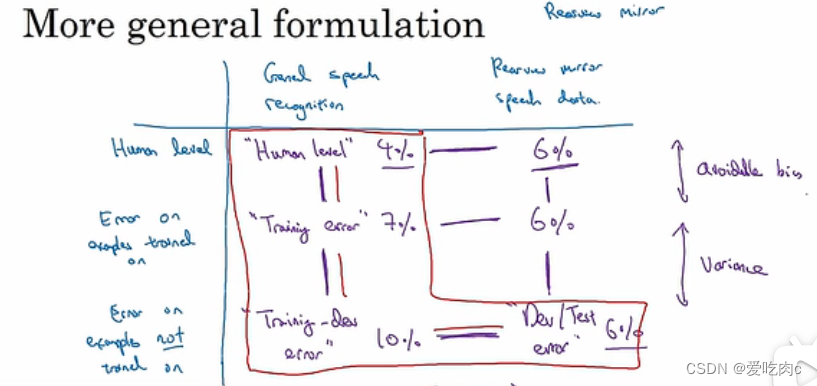
如图,我们以后视镜语音系统为例,假设我们得到了许多语音识别数据作为训练集,而我们真正关注的是后视镜的语音识别数据,通过不同数据的error 我们可以看出我们的模型应该在哪里进行改进。
2、解决数据不匹配问题。
①可以人工进行误差分析,来看我们的训练数据与开发集主要的差异在哪里。
②通过查找主要误差我们可以通过人工合成等方式来使训练数据更贴合开发数据集。
比如 如果我们在语音激活后视镜系统重,我们的训练数据与开发数据的主要差异在于开发数据有汽车噪音,那么我们可以通过人工合成的方式,在训练数据集上添加上汽车噪音。
但是通过人工合成的方式时我们要注意,是否我们采用的只是所有数据的一部分子集。比如汽车噪音,我们人工合成使用的如果只是汽车噪音的一部分子集,就会造成我们对这部分噪音经行了过拟合。
又比如汽车检测,我们要注意是否我们合成的汽车模型,只是所有汽车的一小部分子集呢。
四、迁移学习 transfer learning

①当任务A和任务B有相同的输入时,比如识别猫 与 检测X光片 输入都是图片
②任务A比任务B有多得多的数据。
就是比如我们识别猫系统(A)可以获得大量的图片,但是X光片(B)获得的图片很少,都是图片,在神经网络较低层提取的特征是相通的,可以迁移,所以我们可以通过训练A获得的参数来应用到任务B,只需修改最后一层参数以及权值。
③任务A低层次获取的特征有助于任务B
见②
五、多任务学习 multi-task learning
比如图片检测中,我们可以进行多任务,比如给一张图片,我们可以同时进行 是否有红绿灯,是否有汽车,是否有行人等多个输出任务。
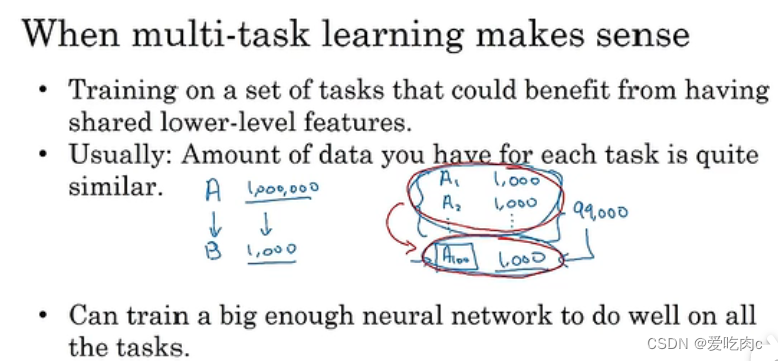
第一点,比如都是图像识别,所以低层次获得的特征是相同的。
第二点不是必须的。
第三点,通过训练一个大的神经网络 会使多任务比单一任务的效果更好。
六、端到端 end-to-end learning
端到端学习就是 对于输入x 可以直接输出y,没有了中间多个途径组成的通道
比如语音识别。给出一段音频可以直接输出对应的文字,没有中间阶段 如识别出音频 音素等。
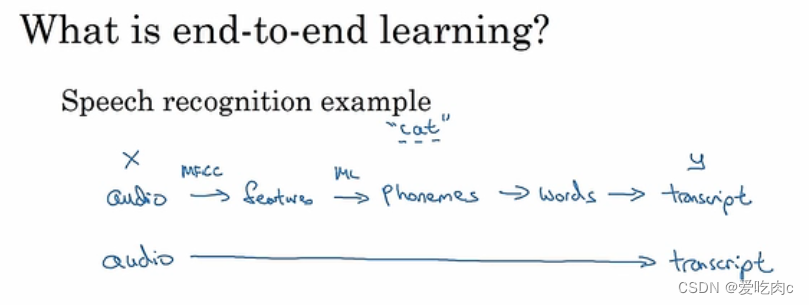
端到端学习的优缺点

端到端学习使数据占主导地位,比如传统的语音识别,是人为设计的音频,因素这些中间学习阶段,但是如果使用端到端学习,或许神经网络会自动找到一种更好的语音识别算法,没有太多人为设计。
但是端到端学习需要大量的数据支撑。比如通过儿童手掌x光片来推测年龄。
如果单单使用端到端系统是很困难的一项任务。
此时,我们采用传统的方法,分开中间阶段,如第一阶段首先识别到骨骼区域,之后通过计算出骨骼的平均长度等信息来计算年龄,这两步都不复杂,只需要少量数据就可以训练出好的算法。
所以端到端学习可能会排除那些原本有效的人为设计。


![阿拉伯数转中文与英文[找到规律,抽象问题,转换成代码]](https://img-blog.csdnimg.cn/18f8f3cb1f444667aeacdb9c0d379257.png)






![[34]. 在排序数组中查找元素的第一个和最后一个位置](https://img-blog.csdnimg.cn/358e6b57c10346b9a448d006abc053e6.png)
