🧧🧧🧧🧧🧧个人主页🎈🎈🎈🎈🎈
🧧🧧🧧🧧🧧数据结构专栏🎈🎈🎈🎈🎈
🧧🧧🧧🧧🧧【数据结构】非线性结构——二叉树🎈🎈🎈🎈🎈
文章目录
- 1. 优先级队列
- 1.1 概念
- 2. 优先级队列的模拟实现
- 2.1 堆的概念
- 2.2 堆的存储方式
- 2.3 堆的创建
- 2.4 堆的插入与删除
- 3.常用接口介绍
- 3.1 PriorityQueue的特性
- 3.2 PriorityQueue常用接口介绍
- 4.堆的应用
- 4.1堆排序
- 4.2Top-k问题
1. 优先级队列
1.1 概念
前面介绍过队列,队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,比如:在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话;初中那会班主任排座位时可能会让成绩好的同学先挑座位。在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
2. 优先级队列的模拟实现
JDK1.8中的PriorityQueue底层使用了堆这种数据结构,而堆实际就是在完全二叉树的基础上进行了一些调整。
2.1 堆的概念
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为 小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
总结:
小根堆:父亲节点比子结点小
大根堆:父亲节点比子结点大
堆的性质:
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
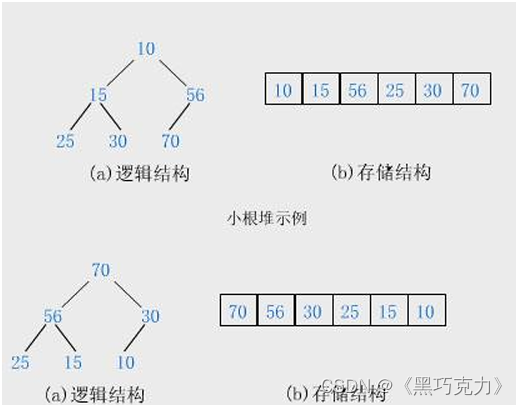
2.2 堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储,
注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
将元素存储到数组中后,可以根据二叉树章节的性质5对树进行还原。假设i为节点在数组中的下标,则有:
如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
2.3 堆的创建
2.3.1 堆向下调整
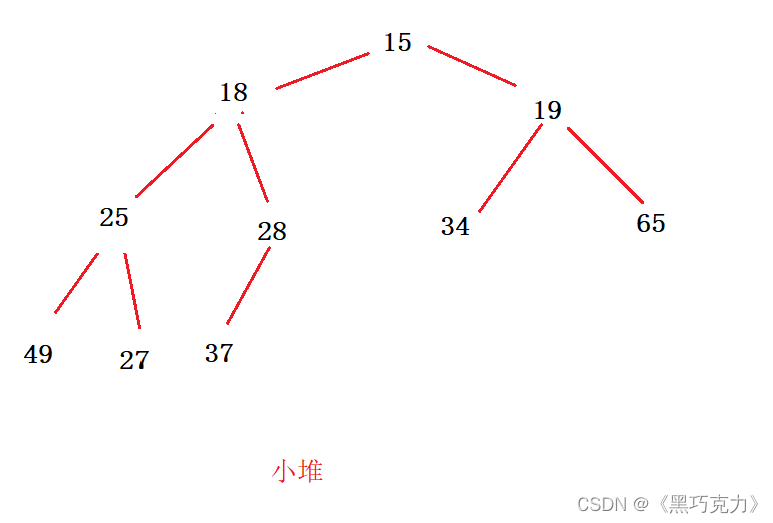
对于集合{ 27,15,19,18,28,34,65,49,25,37 }中的数据,如果将其创建成堆呢?
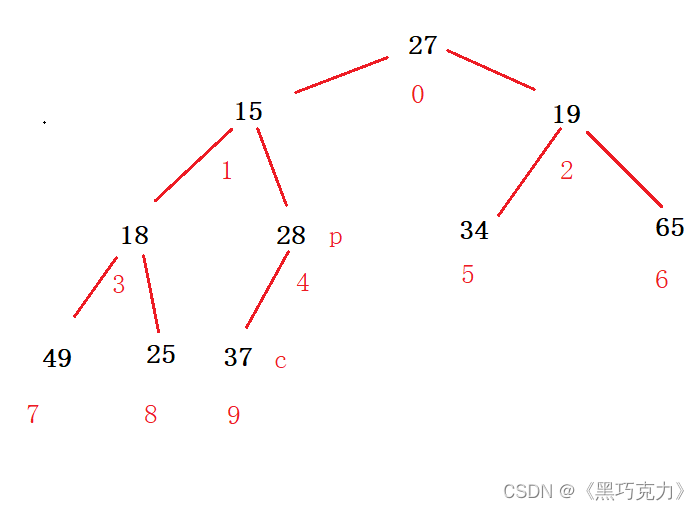
仔细观察上图后发现:根节点的左右子树已经完全满足堆的性质,因此只需将根节点向下调整好即可。
向下过程(以小堆为例):
- 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子)
- 如果parent的左孩子存在,即:child < size, 进行以下操作,直到parent的左孩子不存在
parent右孩子是否存在,存在找到左右孩子中最小的孩子,让child进行标
将parent与较小的孩子child比较,如果:
parent小于较小的孩子child,调整结束
否则:交换parent与较小的孩子child,交换完成之后,parent中大的元素向下移动,可能导致子
树不满足对的性质,因此需要继续向下调整,即parent = child;child = parent*2+1; 然后继续2。

代码实现:
//小堆创建
public void createSmallHeap() {
//由最后一棵子树的结点找到它的父节点下标,然后从这棵子树开始向下调整,依次下标减1.
for(int parent = (usedSize-1-1)/2;parent>=0;parent--) {
//此刻传的两个参数,分别为要向下调整的根结点的下标和这个数组的长度
//为什么传的数组的长度,因为这个向下调整是一个过程,它总有一个时间段是停下的,传的这个数组长度就是一个临界条件
siftDown2(parent,usedSize);
}
}
//向下调整的方法
public void siftDown2(int p,int end) {
//得到该结点的子结点的下标
int c = 2*p + 1;
//临界条件:子结点的下标<数组的长度
while(c < end) {
//找到最小的子结点
if(c+1<end && elem[c] >elem[c+1]) {
c++;
}
//将该结点与最小子结点比较,如大于则交换否则直接break返回
if(elem[p] > elem[c]) {
//交换
swap(p,c);
//将指向该结点的引用指向该结点的子结点,再重新将子结点的下标进行变化,检查该结点的子树是否满足大堆,不满足则继续向下调整
p = c;
c = 2*p + 1;
} else {
break;
}
}
}
以下是创建小堆完成的图:
注意:在调整以parent为根的二叉树时,必须要满足parent的左子树和右子树已经是堆了才可以向下调整。
时间复杂度:最坏的情况是O(log2 N)是以2为底的N的对数
大堆创建的代码:
//大堆的创建
public void createBigHeap() {
//由最后一棵子树的结点找到它的父节点下标,然后从这棵子树开始向下调整,依次下标减1.
for(int parent = (usedSize-1-1)/2;parent>=0;parent--) {
//此刻传的两个参数,分别为要向下调整的根结点的下标和这个数组的长度
//为什么传的数组的长度,因为这个向下调整是一个过程,它总有一个时间段是停下的,传的这个数组长度就是一个临界条件
siftDown1(parent,usedSize);
}
}
//向下调整的方法
public void siftDown1(int p,int end) {
//得到该结点的子结点的下标
int c = 2*p + 1;
//临界条件:子结点的下标<数组的长度
while(c < end) {
//找到最大的子结点
if(c+1<end && elem[c] < elem[c+1]) {
c++;
}
//将该结点与最大子结点比较,如小于则交换否则直接break返回
if(elem[p] < elem[c]) {
//交换
swap(p,c);
//将指向该结点的引用指向该结点的子结点,再重新将子结点的下标进行变化,检查该结点的子树是否满足大堆,不满足则继续向下调整
p = c;
c = 2*p + 1;
} else {
break;
}
}
}
//交换方法
public void swap(int x, int y) {
int tmp = elem[x];
elem[x] = elem[y];
elem[y] = tmp;
}
2.4 堆的插入与删除
2.4.1 堆的插入
堆的插入总共需要两个步骤:
- 先将元素放入到底层空间中(注意:空间不够时需要扩容)
- 将最后新插入的节点向上调整,直到满足堆的性质
画图演示过程:
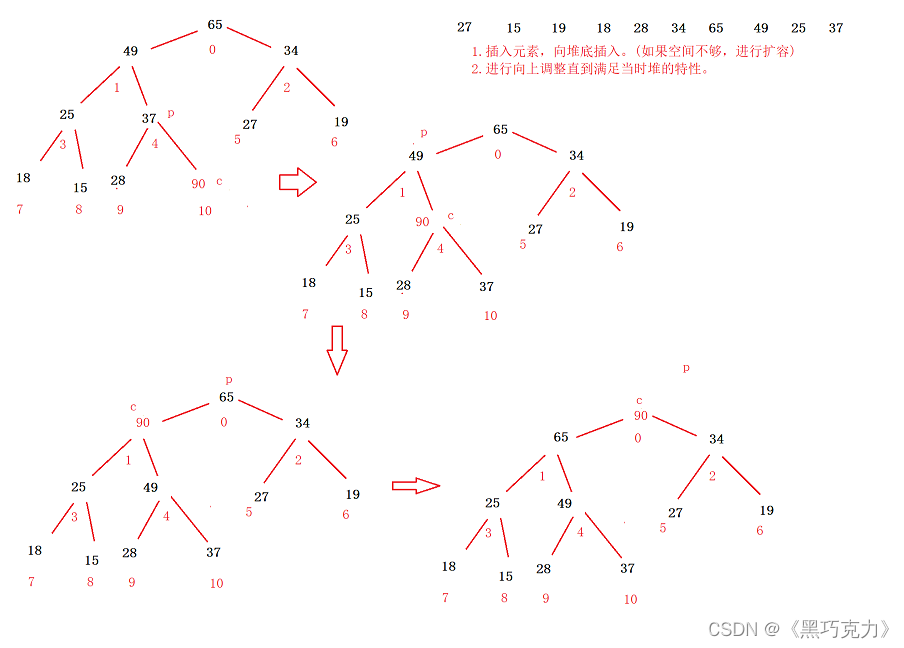
代码实现:
//堆的插入
public void offer(int val) {
//1.判断是否扩容
if(isFull()) {
this.elem = Arrays.copyOf(elem,2*elem.length);
}
//插入元素
elem[usedSize] = val;
usedSize++;//11
//向上调整
siftUp(usedSize-1);
}
private void siftUp(int child) {
int parent = (child-1)>>>1; //>>>1等于除于2
while(child > 0) {
//判断child与parent的大小
if(child >parent) {
//交换
swap(parent,child);
//移动c与p的位置
child = parent;
parent = (child-1)>>>1;
} else {
break;
}
}
}
private boolean isFull() {
return usedSize == elem.length;
}
2.4.2 堆的删除
注意:堆的删除一定删除的是堆顶元素。具体如下:
- 将堆顶元素对堆中最后一个元素交换
- 将堆中有效数据个数减少一个
- 对堆顶元素进行向下调整
代码实现:
//堆的删除(堆的删除一定是堆顶元素)
public int poll() {
//记录删除的元素
int tmp = elem[0];
//交换堆顶元素与最后一个元素
swap(0,usedSize-1);
//数组长度减1
usedSize--;
//对堆顶元素向下调整,因为这个堆本身之前是一个大堆,堆顶之下的结点基本都满足大堆的规则,所以只需要从堆顶的元素向下调整即可
// 直到这个堆完全满足大堆的特性
siftDown1(0,usedSize);
return tmp;
}
//向下调整的方法
public void siftDown1(int p,int end) {
//得到该结点的子结点的下标
int c = 2*p + 1;
//临界条件:子结点的下标<数组的长度
while(c < end) {
//找到最大的子结点
if(c+1<end && elem[c] < elem[c+1]) {
c++;
}
//将该结点与最大子结点比较,如小于则交换否则直接break返回
if(elem[p] < elem[c]) {
//交换
swap(p,c);
//将指向该结点的引用指向该结点的子结点,再重新将子结点的下标进行变化,检查该结点的子树是否满足大堆,不满足则继续向下调整
p = c;
c = 2*p + 1;
} else {
break;
}
}
}
3.常用接口介绍
3.1 PriorityQueue的特性
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,本文主要介绍PriorityQueue。
关于PriorityQueue的使用要注意:
- 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
- PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常 - 不能插入null对象,否则会抛出NullPointerException
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
- 插入和删除元素的时间复杂度为
- PriorityQueue底层使用了堆数据结构
- PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
3.2 PriorityQueue常用接口介绍
1. 优先级队列的构造
有四种PriorityQueue构造方式,分别为:
1.传空参数:

2:传数组的大小的参数:
3.传比较器参数:

4.数组大小和比较器都传:
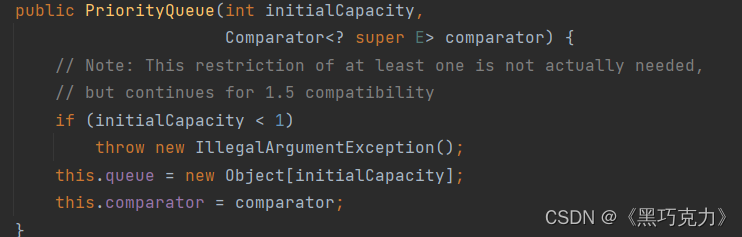
注意:其实细心就会发现前三种不管传了什么,都会调用第四种方式。
这里我需要解释一下:
DEFAULT_INITIAL_CAPACITY:基本容量
Comparator<? super E> comparator: 比较器
这是PriorityQueue队列在创建堆的分析图:
默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
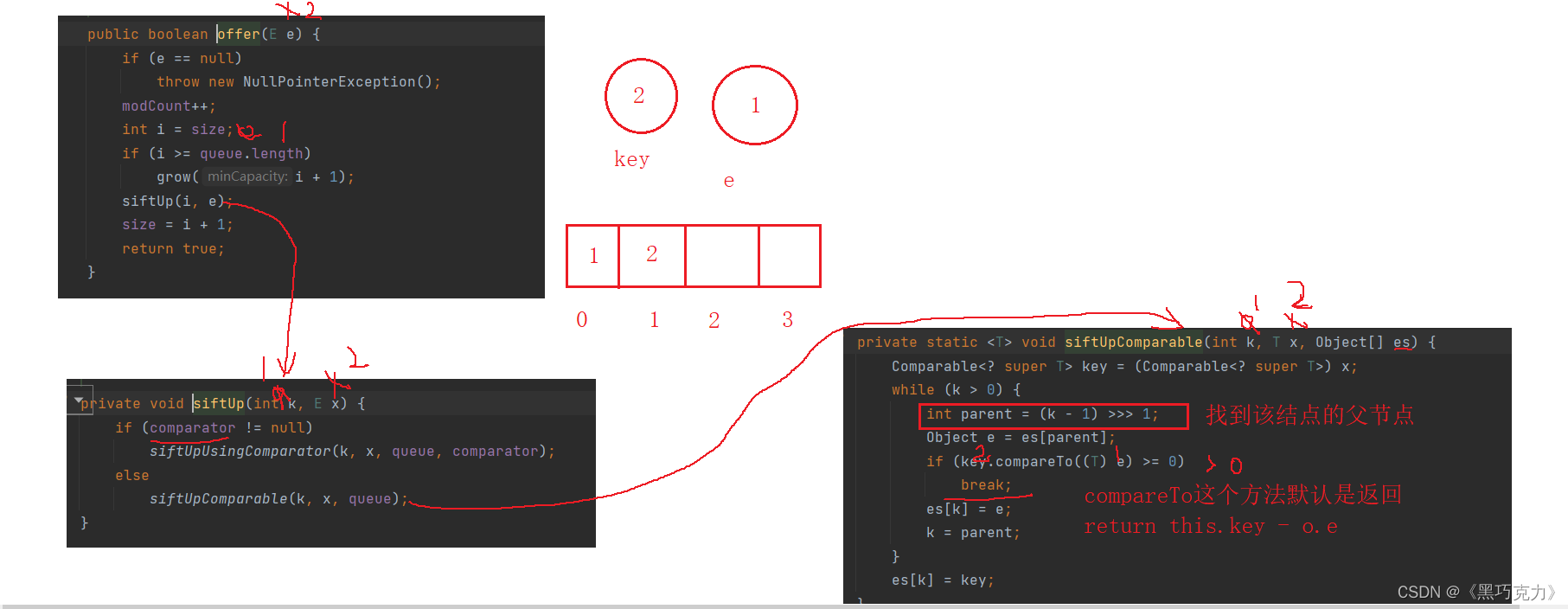
这是传了比较器,通过去重写compare方法,去创建大堆。

代码实现:
class Imp implements Comparator<Integer> {
//通过自己建一个比较器来将小堆转化为大堆
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
}
public class PrioQueue {
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue1 = new PriorityQueue<>();
priorityQueue1.offer(1);
priorityQueue1.offer(2);
System.out.println("======");
Imp imp = new Imp();
PriorityQueue<Integer> priorityQueue2= new PriorityQueue<>(imp);
/*priorityQueue2.offer(1);
priorityQueue2.offer(2);
System.out.println("=========");*/
2.PriorityQueue队列的一些方法:

4.堆的应用
4.1堆排序
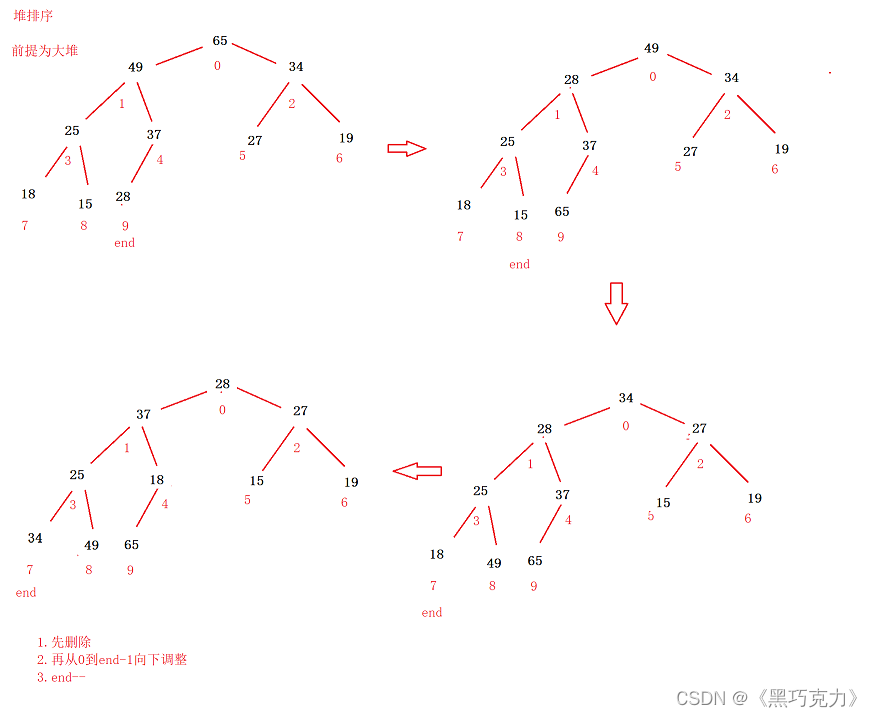
如果你需要将数据以升序的方式排序,则你必须要一个大根堆。
1.创建大根堆(前面实现了)
2.删除堆顶的元素
3.再从0到end-1向下调整
4.end–
画图演示:
代码实现:
public void heapSort() {
int end = usedSize-1;
while(end>0) {
swap(0,end);
siftDown1(0,end-1);
end--;
}
}
//向下调整的方法
public void siftDown1(int p,int end) {
//得到该结点的子结点的下标
int c = 2*p + 1;
//临界条件:子结点的下标<数组的长度
while(c < end) {
//找到最大的子结点
if(c+1<end && elem[c] < elem[c+1]) {
c++;
}
//将该结点与最大子结点比较,如小于则交换否则直接break返回
if(elem[p] < elem[c]) {
//交换
swap(p,c);
//将指向该结点的引用指向该结点的子结点,再重新将子结点的下标进行变化,检查该结点的子树是否满足大堆,不满足则继续向下调整
p = c;
c = 2*p + 1;
} else {
break;
}
}
}
//交换方法
public void swap(int x, int y) {
int tmp = elem[x];
elem[x] = elem[y];
elem[y] = tmp;
}
4.2Top-k问题
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
代码实现:
public int[] smallestK(int[] arr, int k) {
int[] tmp = new int[k];
if (k == 0) {
return tmp;
}
Imp imp = new Imp();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(imp);
// 建立大堆含k个元素
for (int i = 0; i < k; i++) {
maxHeap.offer(arr[i]);
}
// 从第k个元素遍历
for (int j = k; j < arr.length; j++) {
// 堆顶元素小于数组下标j的大小
if (arr[j] < maxHeap.peek()) {
maxHeap.poll();
maxHeap.offer(arr[j]);
}
}
// 打印这个大堆中的元素
for (int i = 0; i < tmp.length; i++) {
tmp[i] = maxHeap.poll();
}
return tmp;
}*/
在求找出最小的数或者找出最大的数我们应该怎么做呢?
有知道的可以在评论区分享你的思路或者代码也行,下篇文章我们来解答这个问题。
希望大家可以从我的文章中学到东西,希望大家可以留下点赞收藏加关注🎉🎉🎉🎉🎉
![16进制的字符串转byte[]数组 以及将字节数组转换成十六进制的字符串](https://img-blog.csdnimg.cn/direct/71f70e101dd14f7ab0c0183ba0d3f914.png)