第十六天课堂笔记
- 学习任务

Comparable接口★★★★
-
接口 : 功能的封装 => 一组操作规范
- 一个抽象方法 -> 某一个功能的封装
- 多个抽象方法 -> 一组操作规范
-
接口与抽象类的区别
- 1本质不同
- 接口是功能的封装 , 具有什么功能 => 对象能干什么
- 抽象类是事物本质的抽象 => 对象是什么
- 2定义方式不同
- 抽象类 : abstract
- 接口 : interface
- 3内容不同
- 抽象类 => 普通类内容 + 抽象方法
- 接口 => 抽象方法 + 常量 + static方法 + default 方法
- 4使用方式不同
- 抽象类 -> 单继承
- 接口: 多继承 , 多实现
- 1本质不同
-
Comparable<T>接口 : 封装了 两个对象 比较大小的功能
-
<T> : 泛型 : 参数传递的数据类型

-
实现接口, 重写int compareTo(T o)方法
- this : 当前对象
- o : 表示待比较的对象
- 返回类型int : return 对象2.比较实例变量 - this.比较实例对象;
- this > o : return 正数
- this < o : return 负数
- this = o: return 0
-
通过 Arrays.sort(对象数组 , 0 , 对象个数); 调用进行排序 , 该方法内会调用重写了的compareTo方法
-
二维数组★
-
一维数组 : int[] arrs = {1,3,2} ; : 存储整数类型的数组
-
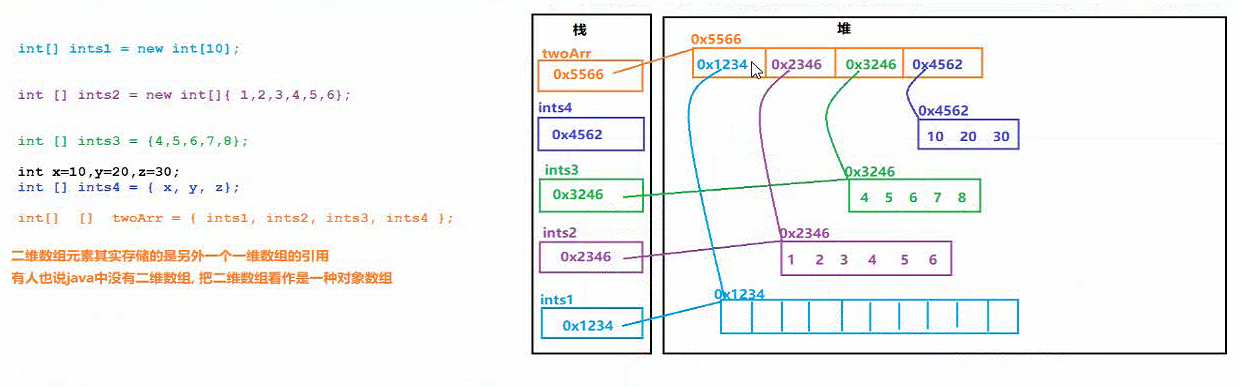
int[] [] 数组名 = {一维数组 , …}; : 存储一维数组类型的数组 => 数组的数组 => 二维数组的静态初始化形式
-
二位数组中的每个一维数组, 存储的是一维数组的引用值 => 将二维数组看作对象数组
-
-
二维数组的定义格式
- 动态初始化 :数据类型[] [] 数组名= new 数据类型[二维数组长度][一维数组长度];
- 当没给一维数组长度输入值 -> 那么系统不会给一维数组初始化, 即默认初始化为null -> 调用的话, 就会Null Pointer Exception
- 动态初始化 :数据类型[] [] 数组名= new 数据类型[二维数组长度][一维数组长度];
-
二维数组的遍历
- 两层for循环
- 两层foreach循环
Java常用类

String字符串★★★
-
创建String对象
-
赋值字符串创建 : String s = “fasfe”;
-
根据构造方法创建对象 :
-
根据字节数组创建
- String(byte[] bytes) 可以把bytes数组中所有字节以默认的字符编码解析为字符串
- String(byte[] bytes, int offset, int length)可以把bytes数组中从offset开始的length个字节以默认的字符编码解析为字符串
- String(byte[] bytes, String charsetName)可以把bytes数组中所有字节以指定的字符编码解析为字符串
- 用处: 从文件中读取若干字节保存到字节数组中 , 将字节数组 转换为 字符串 => 转换需要用到字符编码
- 字符编码就是字符与一串01二进制之间映射
- 常用的字符编码 : UTF-8 , UTF-16 , GBK/GB2312 , ASCII , ISO8859-1
- utf-8 : Unicode编码 ,
- 一个英文字符-> 1 byte字节的二进制 ,
- 一个汉字字符 -> 3 byte字节的二进制
- utf-16: Unicode编码 -> 2 byte字节的二进制 , => char类型数据默认编码
- GBK/GB 2312 : 中文编码 , GB 2312包含的字符数量多
- 一个英文字符-> 1 byte字节的二进制 ,
- 一个汉字字符 -> 2 byte字节的二进制
- ASCII : 美国信息交换码, 只有英文 -> 1 byte
- ISO8859-1 : 西欧编码,(Latin编码) 兼容ASCII => tomcat服务器默认编码
- utf-8 : Unicode编码 ,
- 常用的字符编码 : UTF-8 , UTF-16 , GBK/GB2312 , ASCII , ISO8859-1

-
根据字符数组创建
- String(char[] value) 把value数组中所有的字符连接为字符串.
- String(char[] value, int offset, int count) 把value数组中从offset开始的count个字符连接为字符串
-
-
-
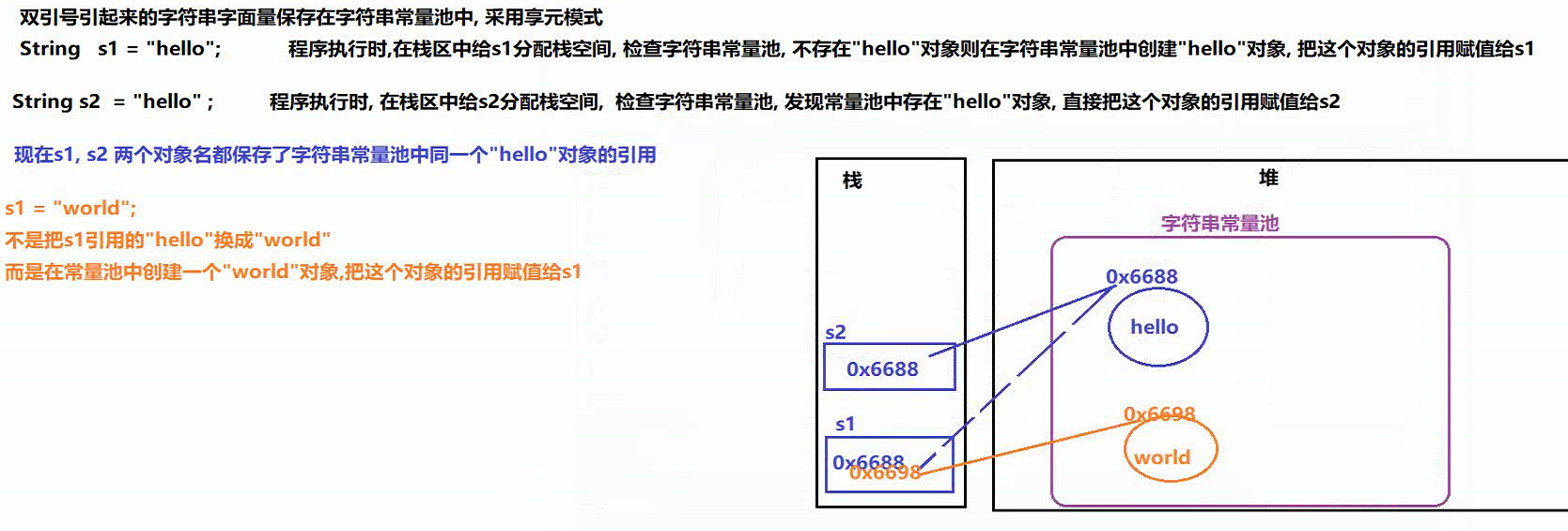
字符串数据存储 到 字符串常量池当中
-
字符串的字面值
- 字符串保存在字符串常量池中, 采用的是 享元模式
- 字符串对象声明赋值 : 先看 常量池是否有该数据 , 有则引用值, 无则创建
- 如果字符串重新赋值: 不是在常量池中覆盖替换 , 而是在常量池中重新创建一个字符串对象, 将对象引用赋值
-
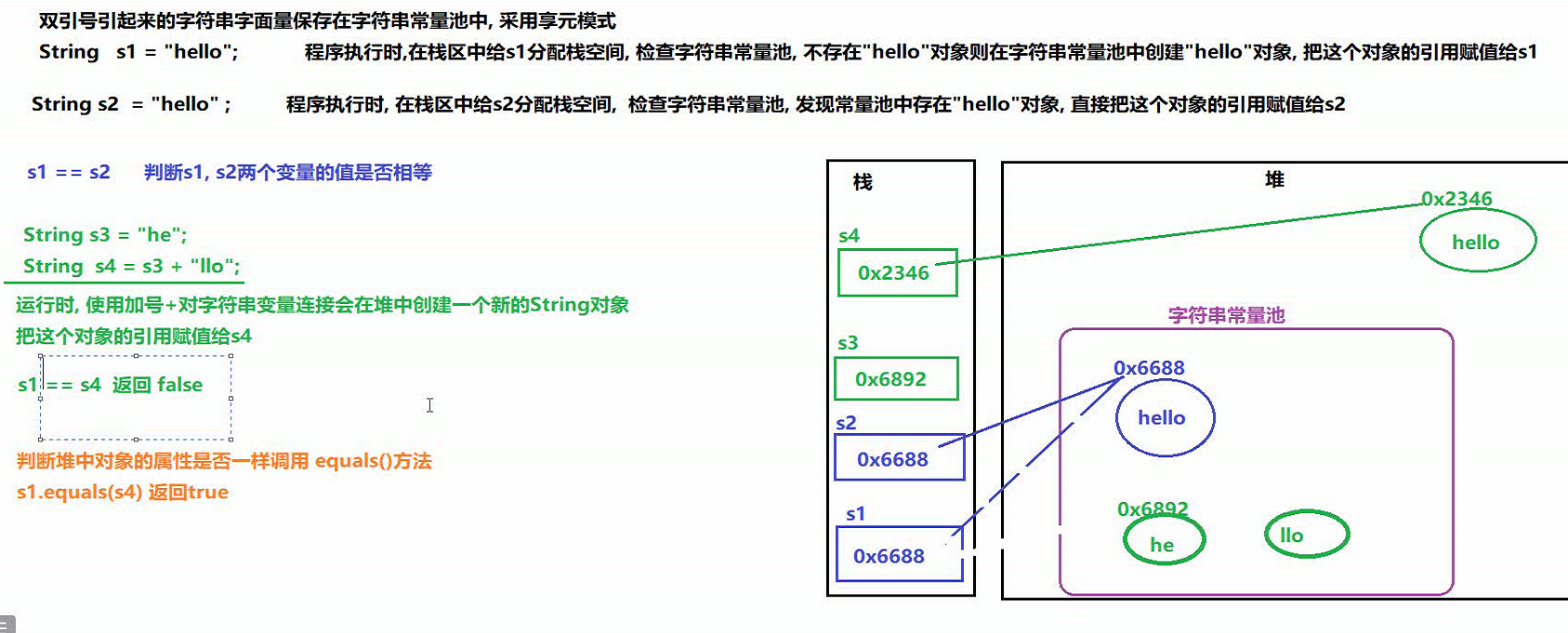
==javac编译器会 在编译过程中 对字符串 常量的连接 进行优化 , 在.Java -> .class的这个过程中优化
-
代码如下:
public static void main(String[] args) { // 定义两个字符串 // "helloworld" 会存储到堆区中的常量池中,将索引值赋值给s1 String s1 = "helloworld"; // "helloworld"已经存在常量池中, 不会再重新创建, 将索引值给s2 String s2 = "helloworld"; System.out.println("s1 == s2 = " + (s1 == s2)); System.out.println(s1 == s2); // 故判断结果为 true // 定义字符串 String s3 = "hello"; //"hello"在常量池中不存在, 故重新创建, 并将索引值给s3 String s4 = s3 + "world"; // s3是变量, 无法用到编译优化 , "world"不在常量池中,故需要创建 ,使用+号对string连接 , 会在 堆区 创建一个 新的字符串对象 , 故会是一个新的引用值 给 s4 System.out.println(s1 == s4); // 故 s1 和 s4 的码值不同 false String s5 = "hello" + "world"; // javac编译器会对字符串 常量的连接 进行优化 , 在.Java -> .class的这个过程中优化,故 s5 其实就是 s5 = "helloworld" System.out.println(s1 == s5); // true System.out.println(s4 == s5); // false // final 常量 final String s6 = "hello"; // "hello"在常量池中已经存在, 故直接引用值 赋给 s6 String s7 = s6 + "world"; // "world"已经在常量池中, 不需要创建,只需要调用, 因为s6是个常量 , 故javac编译器会对字符串 进行优化 => 即 s6 + "world" == "helloworld" , 然后又发现"helloworld"在常量池中已经存在 , 故直接将 引用值 赋 给 s7 System.out.println("s1 == s7 = " + (s1 == s7)); // true
-
面试题: 以下两个共创建了几个String字符串对象 ??
// 问题: 以下两个共创建了几个String字符串对象 ?? String s8 = new String("girlfriend"); String s9 = new String("girl" + "friend"); /* 共三个 首先 : "girlfriend" 在常量池中不存在, 故创建一个字符串对象 其次 : new String("girlfriend") : 表示new 了一个字符串对象 然而 : "girl" + "friend" 由于是两个常量使用+号拼接, 在javac编译时, 会自动进行调优, 使得"girl" + "friend" == "girlfriend" , 而"girlfriend" 在常量池中已经存在, 故只需要引用赋值, 不需要创建新的 最后 : new String("girl" + "friend") : 表示new 了一个字符串对象 综上所述 : 共创建了3个字符串对象 */
-
string对象的不可变性
- 创建string对象后, string字符串对象的字符序列,就无法修改了
- string提供的方法: toUppercase() , trim() , replace() 都是返回一个新的字符串对象, 原来的字符串不变
- string类底层使用private final byte[] value 字节数组 来保存字符串的每个字符 ,
- 该数组是private 私有的, 我们没有权限修改 value数组的元素
- string类 也没有相应的方法修改 value 数组元素
- 使用 + 进行字符串连接时 , 会创建新的string对象
-
问题 : 因为string字符串是不可变的 , 创建string字符串对象后 , 他的字符序列 就不能修改了 , 使用加号(+) 对string 变量进行连接时, 会创建新的string对象
- 当频繁使用字符串连接时 , 会出现多次创建string的情况 ,
- 故 频繁字符串操作 时建议使用 可变字符串来进行操作
stringBuilder&stringBuffer
-
可变字符串 => 字符序列可以修改
- stringBuffer : 是线程安全的
- stringBuilder : 是线程不安全的 , 但是执行效率更高
-
线程安全
- 多个线程 同时操作 一个共享数据 的时候, 可能会存在数据紊乱
-
创建对象常用构造方法
- new StringBuilder() 创建空字符串, 底层数组默认长度为16
- new StringBuilder( 1000000 ) 创建空字符串, 指定底层数组的大小, 避免数组频繁扩容
- StringBuilder(CharSequence seq) 根据其他字符串创建
-
常用操作
- StringBuilder append(String str) 在当前字符串后面连接str
- StringBuilder delete(int start, int end) 删除字符串中[start, end)范围内的字符
- StringBuilder insert(int offset , String str) : 在当前字符串的offset位置插入 str
- StringBuilder replace(int start, int end, String str) 把当前字符串[start, end)范围内的字符替换为str
- StringBuilder reverse() 把字符串中的字符序列逆序
- String toString()
- 因为字符串方法返回值类型都是字符串对象,故可以使用连缀操作
-
代码如下:
public static void main(String[] args) { // new一个可变字符串 StringBuilder stringBuilder = new StringBuilder();// 空串, 底层数组长度为16 StringBuilder stringBuilder1 = new StringBuilder(2000); // 空串, 底层数组长度为capacity : 2000 StringBuffer stringBuffer = new StringBuffer(); // 'StringBuffer stringBuffer' may be declared as 'StringBuilder' : 都可以声明为StringBuilder // append() : 字符串的连接 for (int i = 0; i < 10; i++) { stringBuffer.append(i); } System.out.println("stringBuffer = " + stringBuffer); // delete() : 删除 stringBuffer.delete(3, 8); // 删除[3 , 8)范围内数字 System.out.println("删完后stringBuffer = " + stringBuffer); //删完后stringBuffer = 01289 // insert() : 插入 stringBuffer.insert(3, "flower"); // 在索引为3的位置上插入个数,后面的数顺延 System.out.println("插入后stringBuffer = " + stringBuffer); //插入后stringBuffer = 012flower89 // replace() 替换 stringBuffer.replace(0, 3, "double"); System.out.println("替换后stringBuffer = " + stringBuffer); // 把[0 , 3)的值替换成str // 替换后stringBuffer = doubleflower89 // reverse() : 反转 stringBuffer.reverse(); System.out.println("反转后stringBuffer = " + stringBuffer); //反转后stringBuffer = 98rewolfelbuod // 因为字符串方法返回值类型都是字符串对象,故可以使用连缀操作 String string = stringBuffer.reverse() .replace(0, 5, "hejiabei") .toString(); System.out.println("string = " + string); // string = hejiabeieflower89 }
string常用的方法
-
char charAt(int index); : 返回字符串中 index 位置的字符
-
int length(); : 字符串中字符的数量
-
string字符串由若干字符组成,
-
jdk8之前 : 底层定义 private final char value[] 字符数组来保存字符串的每个字符
-
jdk9 开始 : 底层定义 private final byte[] value 字节数组来保存字符串的每个字符
- 目的 : 节省空间
- 在存储等操作时, 先判断字符编码,
- 如果是Latin编码则使用一个字节存储一个字符
- 如果是utf16编码 ,则使用2个字节存储一个字符
-
底层源码:
public int compareTo(String anotherString) { byte v1[] = value; byte v2[] = anotherString.value; byte coder = coder(); if (coder == anotherString.coder()) { return coder == LATIN1 ? StringLatin1.compareTo(v1, v2) : StringUTF16.compareTo(v1, v2); } return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2) : StringUTF16.compareToLatin1(v1, v2); } @IntrinsicCandidate public static int compareTo(byte[] value, byte[] other) { int len1 = value.length; int len2 = other.length; return compareTo(value, other, len1, len2); } public static int compareTo(byte[] value, byte[] other, int len1, int len2) { int lim = Math.min(len1, len2); for (int k = 0; k < lim; k++) { if (value[k] != other[k]) { return getChar(value, k) - getChar(other, k); } } return len1 - len2; }
-
-
-
代码如下:
// 定义一个字符串 String s = "繁荣昌盛,国泰民安"; // 获取字符串长度 System.out.println("s.length() = " + s.length()); for (int i = 0; i < s.length(); i++) { System.out.print(s.charAt(i) + " "); } System.out.println(); -
int compareTo(String anotherString) : 比较两个字符大小
-
string类型实现了comparable接口, 重写了comparaTo方法,
-
定义比较大小的规则: 区分大小写 , 逐个比较字符串的每个字符 , 遇到了第一个不一样的字符 字符相减 , 如果都一样 , 再比较字符串长度 .
-
底层代码:
public int compareTo(String anotherString) { byte v1[] = value; byte v2[] = anotherString.value; byte coder = coder(); if (coder == anotherString.coder()) { return coder == LATIN1 ? StringLatin1.compareTo(v1, v2) : StringUTF16.compareTo(v1, v2); } return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2) : StringUTF16.compareToLatin1(v1, v2); } private static int compareToUTF16Values(byte[] value, byte[] other, int len1, int len2) { int lim = Math.min(len1, len2); for (int k = 0; k < lim; k++) { char c1 = getChar(value, k); char c2 = StringUTF16.getChar(other, k); if (c1 != c2) { return c1 - c2; } } return len1 - len2; }
-
-
int compareToIgnoreCase(String str); 忽略大小写, 比较字符大小
- 代码如下:
// 比较两个字符串大小 System.out.println("\"hello\".compareTo(\"hella\") = " + "hello".compareTo("hella")); System.out.println("\"hello\".compareTo(\"w\") = " + "hello".compareTo("w")); System.out.println("\"繁荣昌盛\".compareTo(s) = " + "繁荣昌盛".compareTo(s)); System.out.println("\"hello\".compareTo(\"HELLO\") = " + "hello".compareTo("HELLO")); System.out.println("\"hello\".compareToIgnoreCase(\"HELLO\") = " + "hello".compareToIgnoreCase("HELLO")); -
boolean contains(CharSequence s) : 判断当前字符串是否包含s字符串
- CharSequence 是一个接口 ,
- 在调用方法时 , 方法实参为 CharSequence 接口的 实现类对象或者 匿名内部类对象
- CharSequence接口 的实现类有 : string , string builder , string buffer
- 代码如下:
// 包含 System.out.println("s.contains(\"国\") = " + s.contains("国")); // true System.out.println("s.contains(\"中\") = " + s.contains("中")); // fase - CharSequence 是一个接口 ,
-
boolean endsWith(String suffix) : 判断字符串是否以suffix结尾
-
boolean startsWith(String prefix) : 判断字符串是否以 prefix 开头
-
boolean equals(Object anjObject) : 判断两个字符串是否一样
-
boolean equalsIgnoreCase(String anotherString) : 忽略大小写, 判断是否一样
- 代码如下
// 判断字符 System.out.println("s.startsWith(\"繁\") = " + s.startsWith("繁")); //true System.out.println("s.endsWith(\"强\") = " + s.endsWith("强")); // false System.out.println("s.equals(\"繁荣昌盛,国泰民安\") = " + s.equals("繁荣昌盛,国泰民安")); //s.equals("繁荣昌盛,国泰民安") = true System.out.println("\"hello\".equalsIgnoreCase(\"HELLO\") = " + "hello".equalsIgnoreCase("HELLO")); //"hello".equalsIgnoreCase("HELLO") = true -
byte[] getBytes() : 返回当前字符串 在默认编码下 对应的字节数组 :
- utf-8编码中 , 一个英文字符对应一个byte字节, 一个汉字对应 3个 byte 字节
-
byte[] getBytes(String charsetName) : 返回当前字符串 在指定的编码 下对应的字节数组
- 报出异常 unhandled exception
- 代码如下:
// 返回 编码对应的字节数组 byte[] bytes = s.getBytes(); System.out.println("Arrays.toString(bytes) = " + Arrays.toString(bytes)); //Arrays.toString(bytes) = [-25, -71, -127, -24, -115, -93, -26, -104, -116, -25, -101, -101, 44, -27, -101, -67, -26, -77, -80, -26, -80, -111, -27, -82, -119] // 将字节数组 转为字符串: 通过创建string来实现 String s1 = new String(bytes); System.out.println("s1 = " + s1); //s1 = 繁荣昌盛,国泰民安 // 指定编码 返回对应的字节数组 byte[] gbks = s.getBytes("GBK"); //Unhandled exception: java.io.UnsupportedEncodingException System.out.println("Arrays.toString(gbks) = " + Arrays.toString(gbks)); //Arrays.toString(gbks) = [-73, -79, -56, -39, -78, -3, -54, -94, 44, -71, -6, -52, -87, -61, -15, -80, -78] // 将字节数组重新合成字符串 String s2 = new String(gbks); System.out.println("s2 = " + s2); //s2 = ���ٲ�ʢ,��̩�� String gbk = new String(gbks, "GBK"); System.out.println("gbk = " + gbk); //gbk = 繁荣昌盛,国泰民安 -
int indexOf(String str) : 返回str在当前字符串中第一次出现的索引值
-
int lastIndexOf(String str) : 返回最后一次出现的索引值
-
String substring(int beginIndex) : 返回当前字符串 从 begin Index位置 开始的子串
-
String substring(int beginIndex, int endIndex) : 返回[beginIndex , endIndex ) 范围的子串
-
代码如下:
// 查字符 String path = "E:\\course\\02Project\\javaSEProject\\day16\\src\\cn\\hejiabei\\string\\StringMethod.java"; // 获取文件名 以及 文件类型 int slash = path.lastIndexOf("\\"); // 获取最后一个小标 int dot = path.lastIndexOf('.'); // 获取字符串一段的值 String fileName = path.substring(slash + 1, dot); System.out.println("fileName = " + fileName); // fileName = StringMethod String suffix = path.substring(dot); System.out.println("suffix = " + suffix); // suffix = .java -
String replace(CharSequence target, CharSequence replacement) : 将target 替换为 replacement, 返回一个新字符串 , 原字符串不变
-
代码如下:
// 字符替换replace String s3 = "xiaoming666xiaohua666"; String s4 = s3.replace('6', '*'); System.out.println("原来是s3 = " + s3); //原来是s3 = xiaoming666xiaohua666 System.out.println("替换后s4 = " + s4); //s4 = xiaoming***xiaohua*** -
String[] split(String regex) : 将字符串 通过regex 拆分成 数组
- regex = “”: 使用""空串 对字符串拆分 , => 即拆分成字符数组 ==> 相当于toCharArray方法
-
代码如下:
// 拆分 String s5 = " 东临碣石,以观沧海,水何澹澹,山岛竦峙,树木丛生,百草丰茂,秋风萧瑟,洪波涌起,日月之行,若出其中,星汉灿烂,若出其里,幸甚至哉,歌以咏志"; System.out.println(s5); // 东临碣石,以观沧海,水何澹澹,山岛竦峙,树木丛生,百草丰茂,秋风萧瑟,洪波涌起,日月之行,若出其中,星汉灿烂,若出其里,幸甚至哉,歌以咏志 String[] split = s5.split(","); System.out.println("Arrays.toString(split) = " + Arrays.toString(split)); //Arrays.toString(split) = [ 东临碣石, 以观沧海, 水何澹澹, 山岛竦峙, 树木丛生, 百草丰茂, 秋风萧瑟, 洪波涌起, 日月之行, 若出其中, 星汉灿烂, 若出其里, 幸甚至哉, 歌以咏志] // 也可以使用""空字符进行拆分 String[] split1 = s5.split(""); System.out.println("Arrays.toString(split1) = " + Arrays.toString(split1)); //Arrays.toString(split1) = [ , 东, 临, 碣, 石, ,, 以, 观, 沧, 海, ,, 水, 何, 澹, 澹, ,, 山, 岛, 竦, 峙, ,, 树, 木, 丛, 生, ,, 百, 草, 丰, 茂, ,, 秋, 风, 萧, 瑟, ,, 洪, 波, 涌, 起, ,, 日, 月, 之, 行, ,, 若, 出, 其, 中, ,, 星, 汉, 灿, 烂, ,, 若, 出, 其, 里, ,, 幸, 甚, 至, 哉, ,, 歌, 以, 咏, 志] -
char[] toCharArray(); : 将字符串转成 字符数组
-
代码如下:
// 字符串 转换成 字符数组 String s6 = "hello , world"; char[] charArray = s6.toCharArray(); System.out.println("Arrays.toString(charArray) = " + Arrays.toString(charArray)); //Arrays.toString(charArray) = [h, e, l, l, o, , ,, , w, o, r, l, d] -
String toLowerCase(); : 大写转小写
-
String toUpperCase(); : 小写转大写
-
代码如下:
// 大小写转化 String s7 = "Good Good Study"; String upperCase = s7.toUpperCase(); System.out.println("upperCase = " + upperCase); //upperCase = GOOD GOOD STUDY String lowerCase = s7.toLowerCase(); System.out.println("lowerCase = " + lowerCase); //lowerCase = good good study -
String trim(); : 去掉字符串前后空格符
-
代码如下:
// 去掉两边空白字符 String s8 = " Good Good Study "; System.out.println("s8 = " + s8); //s8 = Good Good Study // 去掉两边空白 String trim = s8.trim(); System.out.println("trim = " + trim); //trim = Good Good Study -
static String valueOf(int i) : 把其他类型的数据转换为字符串
- 底层调用stu对象的toString()对象 , Student类没有重写toString()对象, 调用object类继承来的toString()方法 , 返回: 全限定类名 + “@” + 哈希码的十六进制
-
static String valueOf(Object obj) : 把对象转为字符串
-
代码如下:
// 将 数据类型 转换为 字符串 valueof int num = 2523; String s9 = String.valueOf(num); System.out.println("s9 = " + s9); // // s9 = 2523 // object转换 Student student = new Student("张三"); String s10 = String.valueOf(student); System.out.println("s10 = " + s10); //s10 = cn.hejiabei.string.StringMethod$Studenfd0d5ae
调用object类继承来的toString()方法 , 返回: 全限定类名 + “@” + 哈希码的十六进制
-
static String valueOf(Object obj) : 把对象转为字符串
-
代码如下:
// 将 数据类型 转换为 字符串 valueof int num = 2523; String s9 = String.valueOf(num); System.out.println("s9 = " + s9); // // s9 = 2523 // object转换 Student student = new Student("张三"); String s10 = String.valueOf(student); System.out.println("s10 = " + s10); //s10 = cn.hejiabei.string.StringMethod$Studenfd0d5ae



![[HNCTF 2022 WEEK2]来解个方程?](https://img-blog.csdnimg.cn/direct/b62b92076b114dde893ff82b8d194d19.png)